Slimmable Neural Networks(ICLR2019)
论文:https://arxiv.org/pdf/1812.08928.pdf
这篇论文还是挺有意思的,他说一般我们部署的时候都需要从大小网络中挑好一个(譬如MobileNet x1.0,x0.75,x0.5,x0.25这些)才能部署。但如果设备的算力或者约束改变,就需要更换新的网络模型,需要额外的网络传输开销,同时需要维护表项告诉我们什么情况下适合用什么网络结构。
这篇论文的核心思想就是:只训一个网络,需要多大的网络就裁多少通道出来。这篇论文是从网络宽度上下手,在约束不同时直接裁出不同宽度的网络作为子网络,直接用于推理。
Switchable BN
从传统角度出发,我训了个宽度64的ResNet,然后每层都裁出32个通道跑推理,显然结果是会亲妈爆炸的啊!作者认为这里面的主要原因是BN的存在,每层的通道数变了以后,神经元的入度会发生变化,导致特征图的均值方差发生改变,如果我们依然用原始网络的running_mean、running_var会使得BN的统计信息原地爆炸螺旋飞升。
Switchable BN其实说简单也很简单,譬如我想要我的网络能跑在 [x0.25,x0.5,x0.75,x1.0] 四个宽度上,那在训练时就在每个卷积后接4个BN层,分别对应一种宽度的config,但是所有宽度config下的子网络共用同一个卷积层。由于这篇论文的精髓就是只需要训一个网络,显然不论宽度config有多少个,整个网络都是联合训练的。
↓↓↓↓↓以下是该联合训练过程的伪代码
举个栗子,我的原始网络是ResNet50,我给定了 [x0.25,x0.5,x0.75,x1.0] 四个宽度config,那卷积层的基础宽度就是64,但BN层有独立的四个,其宽度分别为16、32、48、64,用于对应不同的宽度config。联合训练的每一个step都需要做4次前向和4次反传,卷积层是直接裁出需要的 [x0.25,x0.5,x0.75,x1.0] 部分通道,BN层则取对应宽度config的私有BN。(训练速度会变慢宽度config的长度倍)
学习率需不需要动是个问题啊!每一层的不同通道过的前向反向次数也不同,是不是需要归一化一下梯度?
然后在推理的时候,我们只需要选择合适的config,从原始网络中裁出需要的卷积通道,取出需要的BN层即可。
实验结果
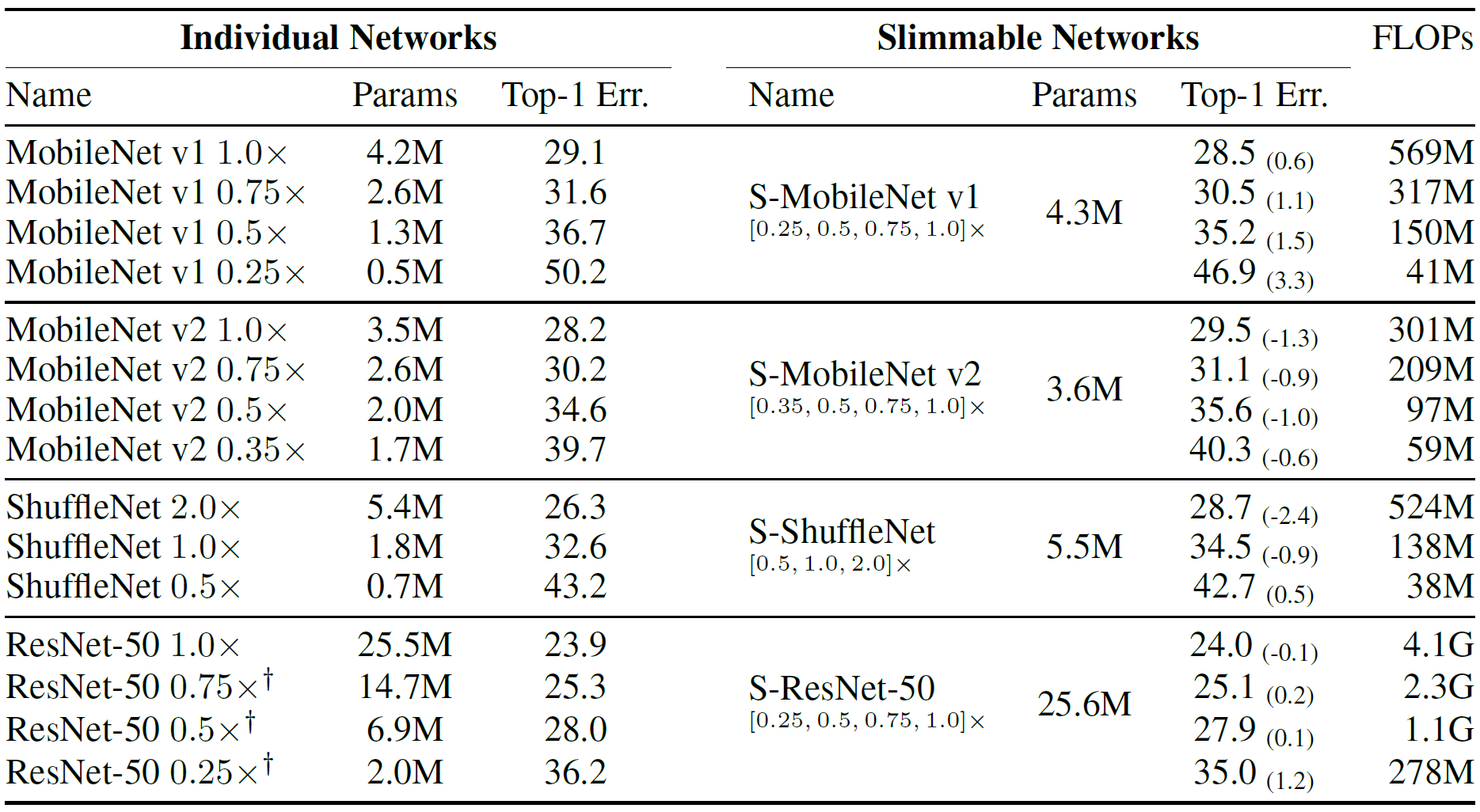
(然后感觉做个自蒸馏会不会更好,用完整网络蒸子网络)
以上想法在《Universally Slimmable Networks and Improved Training Techniques》(ICCV2019)里已有实现!
Universally Slimmable Networks(ICCV2019)
论文:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9009445
《Universally Slimmable Networks and Improved Training Techniques》
这篇论文也挺有意思的,其实是Slimmable Neurla Network的延伸,S-Net只能在[0.25, 0.5, 0.75, 1.0]x 四个宽度选项中做选择,对于宽度为64的网络,即[16, 32, 48, 64]中选择,但这篇论文使得[16~64]宽度中每个宽度都可选择,并引入了sandwich rule和inplace distillation两种针对slimmable网络的优化手段。
虽然这允许通过单个网络的训练裁出不同大小子网络,但本质上依然还是静态神经网络。
BN统计量的处理
在处理BN统计量时,Slimmable Networks的那一套并不可行,因为人家只需要处理4套统计量,而US-Net需要几十套,开销过大。作者采用的方法是,训练过程中不track统计量,收敛后通过喂入小批数据(1000张足矣)一次性统计出所有几十套统计量。
对于 ,所有子网络共用一套参数也能获得较好的效果,虽然Slimmable Networks里它们是独立的。
,所有子网络共用一套参数也能获得较好的效果,虽然Slimmable Networks里它们是独立的。
在不考虑BN统计量的不准确对slimmable网络的影响时,作者认为,越宽的网络一定比越窄的网络性能更好,至少宽网络可以通过将额外通道训至0来保证不比窄网络差。也就是说slim网络相比原始网络的误差满足:
(其中 表示允许的最窄网络宽度,
表示允许的最窄网络宽度, 表示原始的网络宽度)
表示原始的网络宽度)
由于在训练过程中缺乏runningmean和running_var,我们不能在训练过程中获得测试集上的结果。作者提出的思路是,追踪最小网络(宽度为 )与最大网络(宽度为
)与最大网络(宽度为 )对应的running_mean与running_var,基于我们上述对于不同子网络误差的讨论,所有子网络的准确度应该对于区间内。
)对应的running_mean与running_var,基于我们上述对于不同子网络误差的讨论,所有子网络的准确度应该对于区间内。
两个训练技巧
Sandwich Rule
Slimmable网络的训练,不可能在每个step都遍历所有子网络,只能从中抽样一部分用作当前step的训练。三明治准则,正是利用了: 这一规律,只要我们提高了模型精度的下确界与上确界,就能隐式地提高所有子网络的准确度。因此在每一步训练过程中,我们每次都抽样
这一规律,只要我们提高了模型精度的下确界与上确界,就能隐式地提高所有子网络的准确度。因此在每一步训练过程中,我们每次都抽样 ,再随机选择(N-2)个其它宽度的子网络。
,再随机选择(N-2)个其它宽度的子网络。
Inplace Distillation
这其实也是一种自蒸馏方式,就是我看Slimmable Networks是想到的宽网络蒸窄网络。类似于《Be your own teacher: Improve the performance of convolutional neural networks via self distillation》在深度层面实现自蒸馏(完整深度蒸浅stage拉出来的分类器),这篇论文用宽网络蒸窄网络。
对于分类任务,直接将最宽网络的预测结果作为软标签,用于训练所有其它宽度的网络。
作者尝试了结合GT硬标签与最宽网络软标签一起训练子网络,恒定loss比例与动态衰减的loss比例(前期软标签为主后期GT硬标签为主)都试了,但都没有直接用软标签训效果好。
US-Net训练流程

实验结果
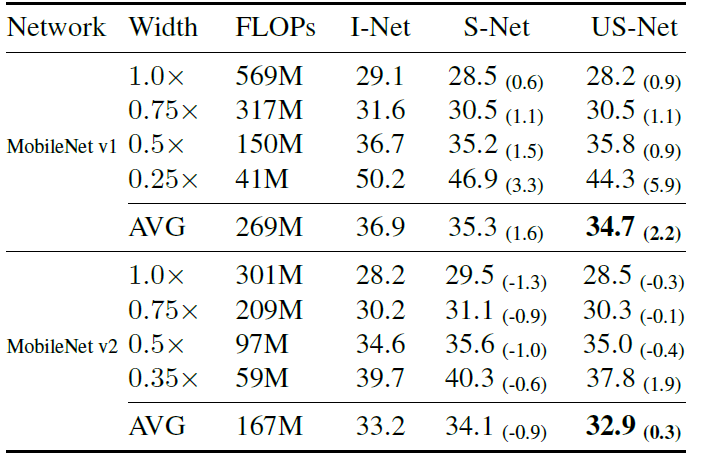
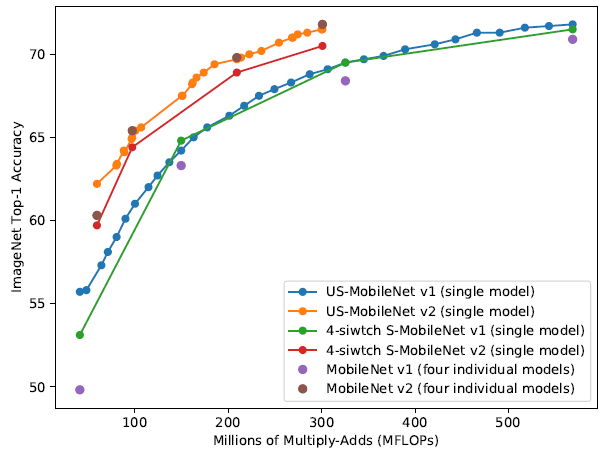
Ablation Study
Sandwich Rule: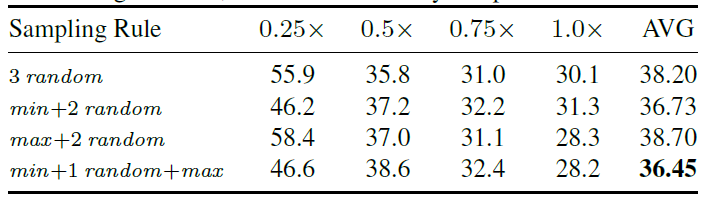
Inplace Distillation: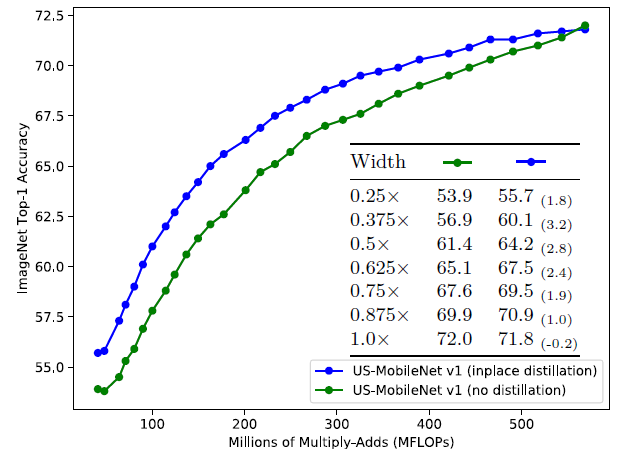
最终获取BN统计量时用的样本数与统计方法: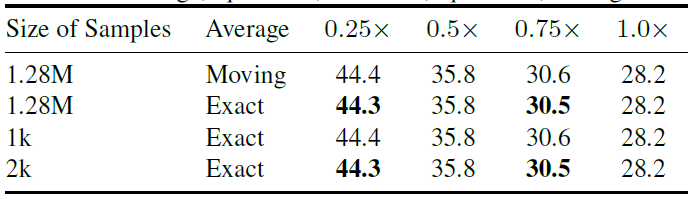
最小宽度k0的影响: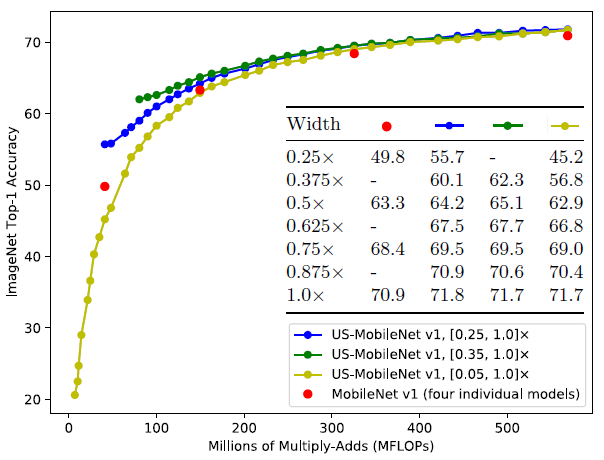
每个step采样的子网络数量N的影响:(N=3即每个step采样最小最大+一个随机子网络)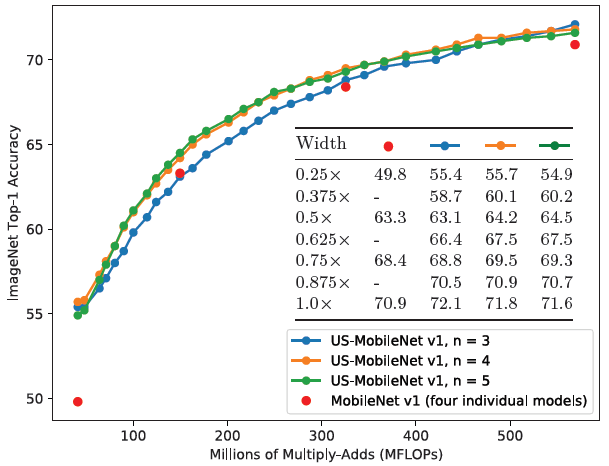
Dynamic Slimmable Network(CVPR2021)
论文:https://arxiv.org/pdf/2103.13258.pdf(通道级条件计算)
其实这篇和ICLR2019的那篇《Slimmable Neural Networks》有那么点像,那篇的特点是(x0.25,x0.50,x0.75,x1.0)四个宽度的网络使用了同一个supernet(超网),达到只训练一个网络就能根据需要选择不同宽度的效果,但是选择哪个宽度是手工指定的而非自适应,所以说白了依然不是动态神经网络方法。
相比Channel Gating、GaterNet等通道级条件计算方法,作者提出那些方法在实际计算中需要做内存重排从而不能起到加速效果。比如说从16个通道中选择了[3, 5, 6, 10, 13],但这些通道的特征图与卷积核在内存中不是连续的,需要做重排,甚至比做mask直接算所有通道都耗时。作者提出的动态路径类似于《Slimmable Neural Networks》,譬如16个通道选择(1~4、1~8、1~12、1~16),而非每个通道的开闭都独立决策。
从出发点来说,这篇论文的重点并不在于为每个输入/特征图选择合适的通道进行推理,而在于预测当前输入
的难度,难度高的输入多用一些通道而难度低的输入少用一些通道,从而实现动态神经网络的条件计算。
训练方法
作者使用了一个两阶段pipeline,并分别引入了一些trick。在训练的第一阶段,门控被禁用,类似于US-Net的方法训练backbone。在训练的第二阶段,backbone被锁死并训练门控。
DS-Net相当于改进了US-Net的训练方法,并加了个训练门控的阶段以实现条件计算。
In-place Ensemble Bootstrapping
US-Net中提出的sandwich rule和in-place distillation提升了可变宽模型的准确度。然而在训练初期,教师模
型的输出波动剧烈可能会使得收敛困难,因此作者采用了教师模型的EMA用于给出软标签(神奇!):
另外,以上讨论的是最宽网络(用 表示)的输出。在US-Net中,最窄网络(用
表示)的输出。在US-Net中,最窄网络(用 表示)和其它所有随机宽度的子网络(用
表示)和其它所有随机宽度的子网络(用 表示)均采用
表示)均采用 作为标签。而在DS-Net中,
作为标签。而在DS-Net中, 网络采用
网络采用 (EMA结果)作为标签,而
(EMA结果)作为标签,而 网络同时采用了
网络同时采用了 网络和所有
网络和所有 网络的标签:
网络的标签:

门控的构建
门控采用了简单的Avgpool+FC+ReLU+FC的结构。作者想到了控制门控输出的两种方法,一是直接sigmoid输出需要用到的通道的比例数,二是做分类预测离散的每个选项的概率。作者发现第二种效果更好(why?)
作者使用了所谓的“double-headed”,其中宽度门控为 ,这一部分只在第二阶段训练时使用。另一部分则就是SE模块,只不过与门控共享了
,这一部分只在第二阶段训练时使用。另一部分则就是SE模块,只不过与门控共享了 部分,开源代码(写的稀巴烂)中的seratio就是
部分,开源代码(写的稀巴烂)中的seratio就是 的输出维度与输入维度的比值。(SE原始是sigmoid,这里用了1+tanh,其实两者都可)
的输出维度与输入维度的比值。(SE原始是sigmoid,这里用了1+tanh,其实两者都可)

Sandwich Gate Sparsification
在第二阶段的训练过程中,作者引入了端到端交叉熵损失 以及复杂度损失
以及复杂度损失 。为了使得离散门控能够用端到端交叉熵损失训练,作者使用了老生常谈的gumbel-softmax技术。但即便如此,门控也总是坍塌陷入某个静态决策结果(和之前大部分条件计算碰到的困难一样)。为此作者额外引入了SGS loss。
。为了使得离散门控能够用端到端交叉熵损失训练,作者使用了老生常谈的gumbel-softmax技术。但即便如此,门控也总是坍塌陷入某个静态决策结果(和之前大部分条件计算碰到的困难一样)。为此作者额外引入了SGS loss。
SGS loss作为Gate的loss真的是人间迷惑并且相当匪夷所思的一个东西。譬如门控有4个离散的宽度选项,分别为[x0.25, x0.5, x0.75, x1.0],SGS loss是完全当做分类任务去对待的。
当最小的网络也能正确预测时,样本为简单样本,记为 ,类别标注为x0.25这个类别(门控目标标注
,类别标注为x0.25这个类别(门控目标标注 );不能被最大网络正确预测,样本为难样本
);不能被最大网络正确预测,样本为难样本 ;其余样本为不确定样本,记为
;其余样本为不确定样本,记为 ,其类别标注都为x1.0这个类别(门控目标标注
,其类别标注都为x1.0这个类别(门控目标标注 )。
)。
x0.5和x0.75两个类没有任何被选中的机会(所以你说你要这两个类干嘛,x0.5和x0.75反一反也没任何区别啊!!!!)
然后具体算loss就是和分类问题交叉熵一样,先把Gate的输出softmax后直接CrossEntropy(output, target)。
实验结果
上面说了这么多,还以为这个动态网络做的有多好,结果:
- ResNet每个stage只有第一个Block有Gate,stage内的所有Block共用第一个Block的Gate输出的宽度。门控会从[0.25, 0.5, 0.75, 1.0]中做选择。因此对于ImageNet网络总共可能有444*4=256种状态。
- MobileNet前5个Block均采用
 ,第6个Block开头有唯一一个门控,门控会从[0.35, 0.4, 0.45, 0.5, …, 1.25]中做选择。因此对于ImageNet网络总共只有18种状态????
,第6个Block开头有唯一一个门控,门控会从[0.35, 0.4, 0.45, 0.5, …, 1.25]中做选择。因此对于ImageNet网络总共只有18种状态????
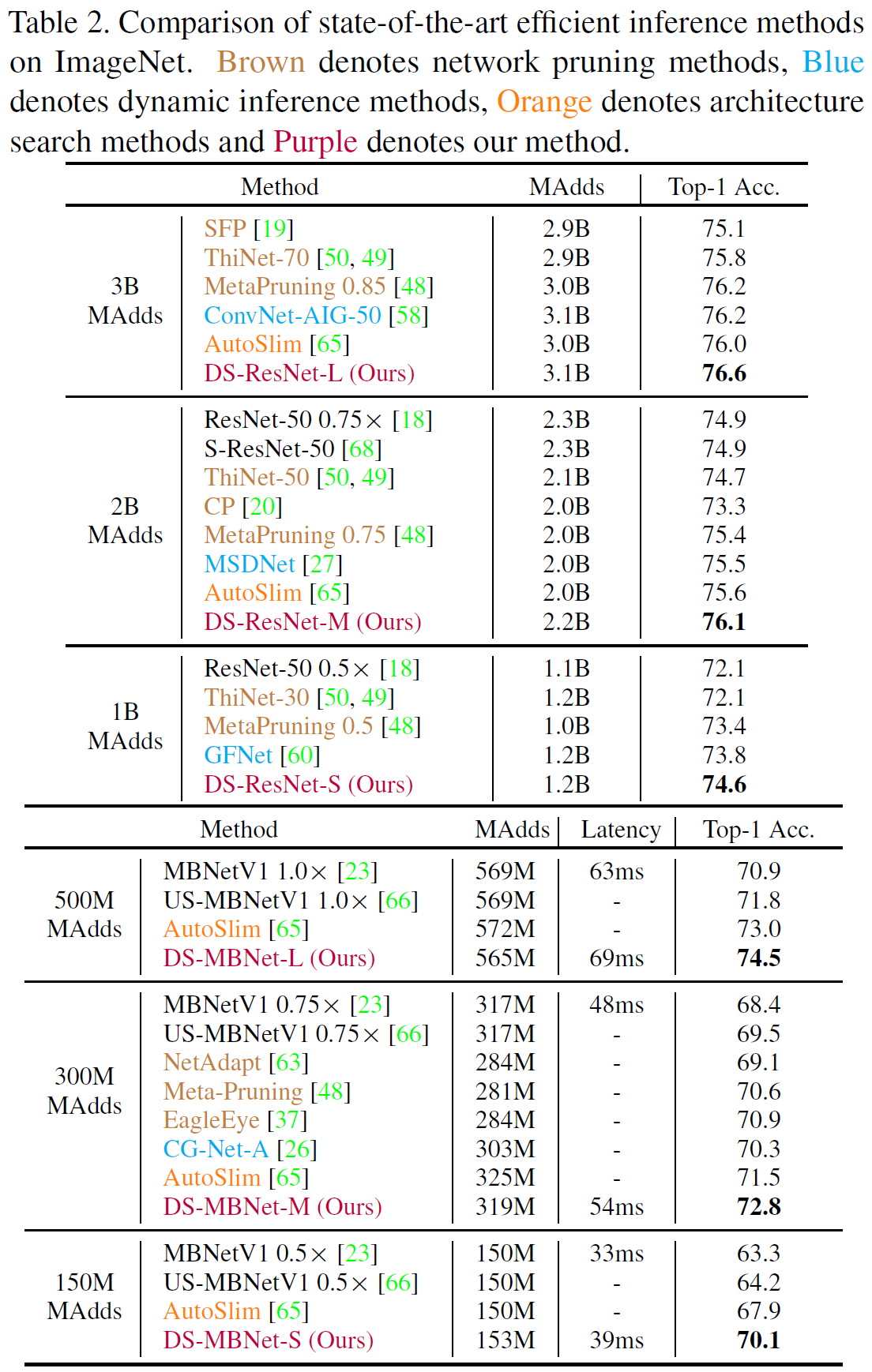
Ablation Study
IEB蒸馏,最小网络的标签是否集成,以及最大网络给标签时是否做EMA
第二阶段训练采用不同loss的结果(只用Complexity loss应该就变最小网络了)
需要注意的是,Try Best即 ,而Give Up就是对难样本放弃治疗,即
,而Give Up就是对难样本放弃治疗,即 。
。
感觉这样显然不能这么比啊,应该根据推理阶段门控的输出再去选择是否放弃治疗而不能在训门控的时候就这么瞎J2训,会让模型以为简单样本和难样本都应通过最小网络,只有不确定样本需要通过最大网络,NaN训。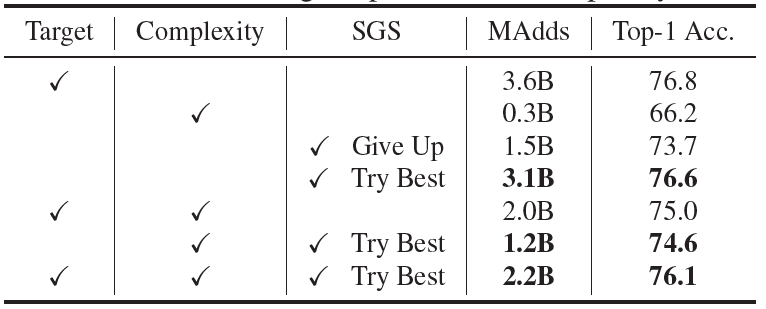
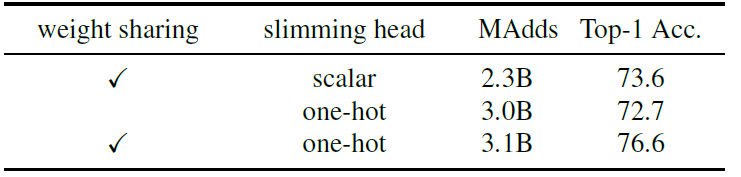
接下来这个对比感觉有点精髓,虽然不知道为什么用one-hot构建门控比scalar更好。weight sharing指的是SE模块与Gate是否共用第一层FC: 。一开始还不知道SE存在的意义是啥,现在才感觉是为了给门控一个比较好的偏置
。一开始还不知道SE存在的意义是啥,现在才感觉是为了给门控一个比较好的偏置 。
。
跑出来ResNet上4个stage宽度的分布情况(为啥0.5和0.75不是0????)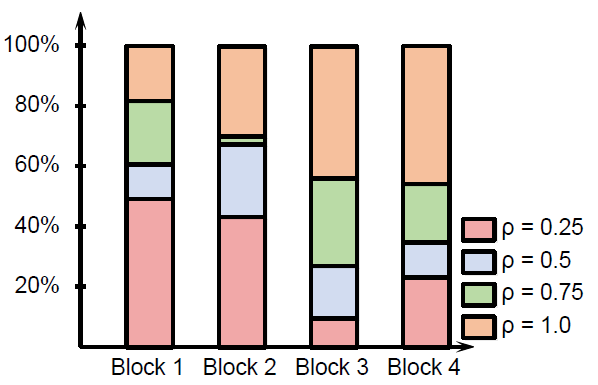

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}