论文:Bag of Tricks for Image Classification with Convolutional Neural Networks
后续除了上述论文外加了一些拓展
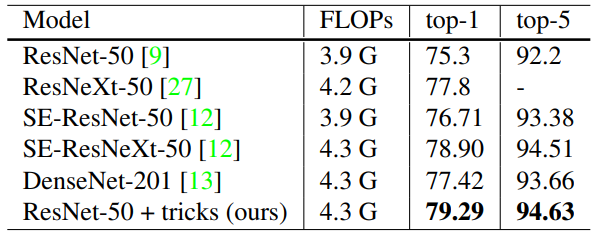
论文的重点是作者提出了一系列的tricks,能够在基本不改变网络结构的前提下提高传统分类网络的性能。
2. 训练细节
2.1 Baseline
预处理流程:
transform = transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.4, saturation=0.4, hue=0.2),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])pytorch没有.PACNoise(mean=0, std=0.1)])
参数初始化使用了均匀分布的Xavier初始化。
训练参数:bs=256(8张v100),lr=0.1,[30,60,90]epc的时候砍10倍,共训练120epc。
3. 高效训练
3.1 大batch_size训练
增大batch_size有利于增加计算的并行度,非常适合GPU计算,但batch_size变大以后可能会对训练产生不利的影响。对于同一网络在同一数据集上,训练相同的epoch数,batch_size更大时,网络的test准确率往往会下降。以下提出了四种缓解该问题的方法。
- 学习率与batch_size线性增长
在mini-batch SGD中,由于样本随机从数据集中抽取,随机梯度下降是一个随机过程。当batch_size增大时,梯度的期望没有发生改变,但方差却等比例减小了,也就是说梯度中的随机噪声被削减了,因此我们需要等比例地增大学习率。
- warmup
在训练初期,参数几乎呈随机分布,与最终结果相差甚远,此时使用过大的学习率进行学习可能使模型变得不稳定。因此我们引入warmup,在初期使用较小的学习率(一般为设定学习率的0.1倍)直到训练过程趋于稳定。Goyal等人提出了另一种warmup方法,在训练初期线性增长学习率至设定的学习率。譬如设置5epc的warmup,共m step,那么第i step的学习率就为 。
。
- Zero_init_residual
在ResNet中,将每个残差单元的最后一个BN层(对BasicBlock而言是bn2,对Bottleneck而言是bn3)的 初始化为0而不是1。这样所有的残差单元在初始状态下就完全变为了恒等映射,使得网络更易训练。
初始化为0而不是1。这样所有的残差单元在初始状态下就完全变为了恒等映射,使得网络更易训练。
- 不对bias做正则化
最好只对权重层的weight做正则化,而不对bias和BN中的和 做正则化。
做正则化。
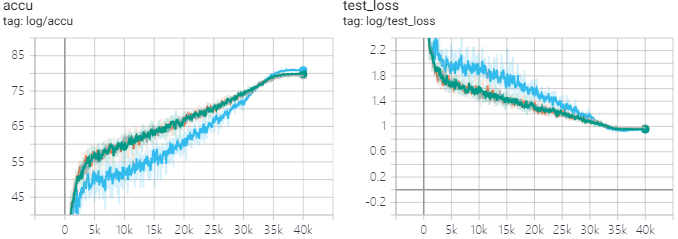
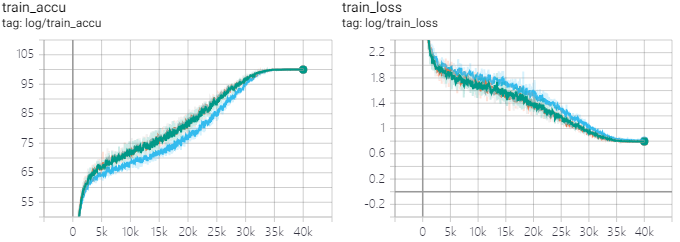
我自己在CIFAR100上做实验,发现精度掉了1个点都不止,猜测是该方法只对非常大的batch_size有效,我使用的bs=256还太小,可能要1k以上才会起作用,这么大的bs没这个条件测就算了。(蓝线对应所有参数都加L2,acc=81.2%;绿、黄、灰线对应只对卷积核全连接的weight加L2,acc max=80.0%)
可以看到,对BN不加L2并没有引起过拟合,训练阶段test和train的准确率都高出很多,但训到收敛就是差。
3.2 低精度训练
最新架构的GPU对FP16的算力远高于FP32,而且FP16在很多情况下精度已经足够,因此使用FP16可以将训练过程加速2~3倍。使用FP16的问题是,FP16的精度范围较低,使用FP16增大了数值溢出的可能性,从而影响训练。Micikevicius等人提出以FP16存储参数并计算激活输出,但是实时保存一份FP32的参数副本用于参数更新。
除此之外,为loss增添一个scalar因子也会更利于将梯度限定在FP16的精度范围内。(这是啥,不懂)
3.3 实验结果
训ImageNet时,用FP32时batch_size只能取256,13.3分钟/epc;用FP16时,batch_size取1024,速度提升到了4.4分钟/epc。即使使用了学习率等比例缩放,将batch_size从256扩大到1024依然掉了0.9%精度,但把上面提到的改进全部用上以后,FP16/BS=1024甚至反而比FP32/bs=256好了。
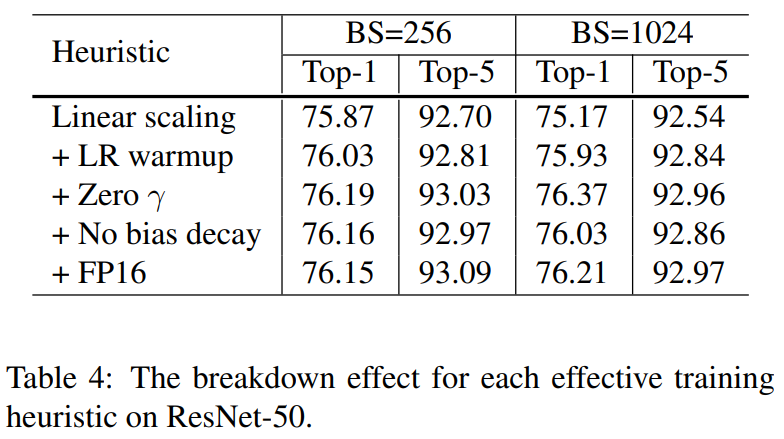
(↑↑↑展示的是单项改进方案的结果)
4. 模型调整
本文使用了ResNet举例,提出了一些几乎不影响计算量但能有不可忽略的性能提升的模型调整。
4.2 ResNet调整
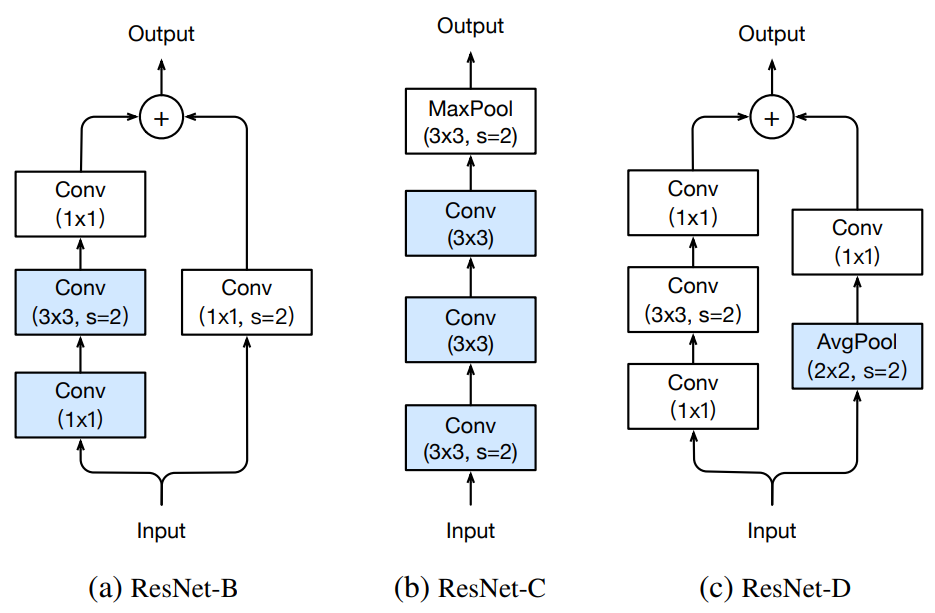<br />ResNet-B将原始ResNet Bottleneck结构中残差分支的下采样从第一个1x1卷积移到了3x3卷积,防止3/4信息的丢失;<br />ResNet-C将原始ResNet的conv1(一开始的7x7卷积)拆分为了三个3x3卷积并在第一个卷积层下采样,其中前两个卷积层的输出通道数为32,第三个为64;<br />ResNet-D是作者提出的,在ResNet-B的基础上同时改善了短连分支丢失3/4信息的缺陷,在需要进行下采样的时候用平均池化进行下采样再接一个1x1卷积变更通道。<br /> 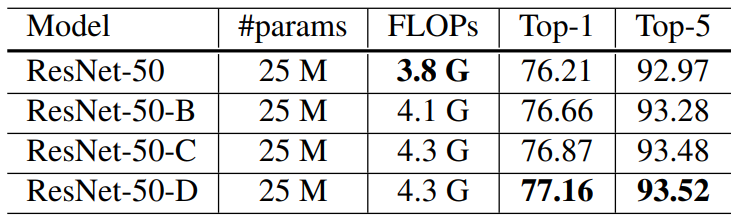<br />相比原始的ResNet,ResNet-D在训练中慢了3%(没说测试),精度高了大约1%。
5. 改进训练方法
5.1 余弦型学习率削减
*__需要注意的是这个和余弦周期性学习率不是一回事
假设训练总共有 步(len(trainloader)*epc,暂时忽略warmup),那么每一步的学习率就是:
步(len(trainloader)*epc,暂时忽略warmup),那么每一步的学习率就是:
 _
_
和传统的“砍两刀”学习率调控方法的学习率对比图:
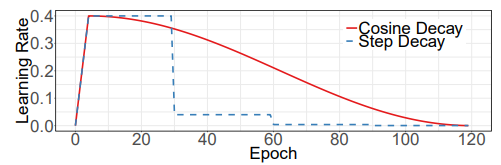
作者也说不出什么理由反正就说这个好,虽然我还是第一次看到这种学习率调控方法。
5.2 标签平滑
标签平滑最早提出于Inception v2,但是该论文中对于标签平滑只是一笔带过。
对于传统的分类网络训练过程中采用的交叉熵loss,只有当正确分类的预测值达到无穷大且其它分类的预测值足够小时,loss才趋于0。这种训练方法鼓励模型的输出标签显得“与众不同”才行,这样容易造成过拟合。
标签平滑最早是提出来用于训练Inception-v2的,它将原来的one-hot硬标签更改为了:

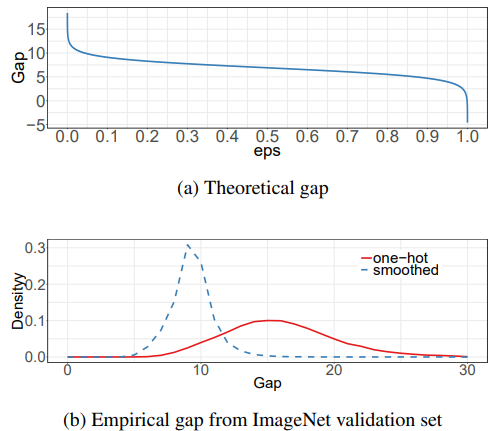
记使得loss为0时,正确分类的输出与错误分类的输出的差值为gap(譬如 为0时gap为无穷大,为(K-1)/K时gap为0)。作者画出了不同epsilon下gap的变化,以及使用one-hot lable和smooth lable训练的模型在ImageNet的测试集上gap的分布情况。一般常取
为0时gap为无穷大,为(K-1)/K时gap为0)。作者画出了不同epsilon下gap的变化,以及使用one-hot lable和smooth lable训练的模型在ImageNet的测试集上gap的分布情况。一般常取 。
。
产生了一个危险的想法:平滑标签会将正例输出已经达到0.99时硬拉回0.9,如果用 做正例lable,
做正例lable, 做负例lable进行训练就不会发生这种事情了?用输出指导标注是不是不太靠谱?感觉和毕设的时候犯得蠢很像但又不一样,毕设的时候是隐式地用了test的结果指导train的过程。
做负例lable进行训练就不会发生这种事情了?用输出指导标注是不是不太靠谱?感觉和毕设的时候犯得蠢很像但又不一样,毕设的时候是隐式地用了test的结果指导train的过程。
论文When Does Label Smoothing Help?中作者表示,使用平滑标签能够减小类内距离,并鼓励不正确类的样本在类间均匀地以相同距离分离(Therefore, label smoothing encourages the activations of the penultimate layer to be close to the template of the correct class and equally distant to the templates of the incorrect classes.)
除此之外,平滑标签还能解决模型过于“自信”的问题,也就是模型softmax后的最大值远小于模型在测试集上的预测准确率。使用Temperature scaling同样可以解决这个问题(就是FC后softmax前把FC结果全部除以T),以平滑模型输出,避免极端值。
5.3 知识蒸馏
知识蒸馏具体就懒得在这里展开讲了。
稍有不同的是作者提出的构造教师网络和学生网络之间loss的方法:

其中超参数代表温度,用于使得softmax的输出更为平滑从而更好地蒸馏得到老师网络的知识。
论文When Does Label Smoothing Help?表示知识蒸馏中的教师网络不应该采用smooth lable方法训练,否则会造成学生网络最终准确度的下降。使用平滑标签进行训练的教师网络丢失了FC输出结果(logits)中类间的相互信息。作者对类间相互信息通过以下公式进行了近似,并做了实验测试是否使用平滑标签训练教师网络时,教师网络所包含的相互信息量。
其中 是用于计算经验均值的蒙特卡洛模拟中使用的样本数,
是用于计算经验均值的蒙特卡洛模拟中使用的样本数, 是用于估算相互信息量中用到的训练样本数。估计得到的相互信息的值应该位于0与log(N)间。
是用于估算相互信息量中用到的训练样本数。估计得到的相互信息的值应该位于0与log(N)间。
5.4 mixup
这倒真的是个新奇的方法,虽然让人第一感觉怀疑这到底靠不靠谱。
混合训练中训练的输入不再是每一张数据集中的图片,而是按随机的比例将随机从数据集中抽取的两张图、及这两张图对应的lable,做像素级别的加权叠加后输入网络。训练阶段时,网络的每一个输入都必然来自两个样本的叠加(没有单样本输入)。
其种 ,且抽样自Beta分布
,且抽样自Beta分布 。
。
另外mixup的时候不需要做标签平滑!
后面实验中说了使用混合训练时需要增加训练的epoch数。
5.5 实验结果
实验中取平滑标签,知识蒸馏温度 ,混合训练中Beta分布
,混合训练中Beta分布 。知识蒸馏中教师网络为使用了上面提到的所有优化方法(除了知识蒸馏)的ResNet152-D。由于使用了混合训练,需要将训练的epoch数从120增加到200。
。知识蒸馏中教师网络为使用了上面提到的所有优化方法(除了知识蒸馏)的ResNet152-D。由于使用了混合训练,需要将训练的epoch数从120增加到200。
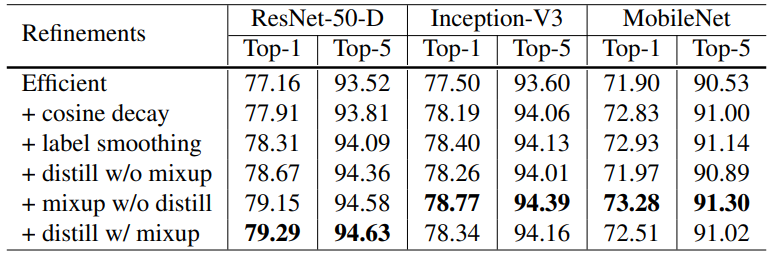
其中余弦学习率衰减、标签平滑、混合训练对ResNet、Inception、MobileNet均十分有效,但知识蒸馏对Inception和MobileNet的效果较差,可能因为教师网络和它们的结构不同导致了输出的分布不同从而阻碍了学习。
自己做的实验结果
数据集:CIFAR100
网络:Wide ResNet26 (k=6)
下采样中的短连接从stride=2的1x1conv改为2x2avgpool+1x1conv有明显提升
zero_init_residual有明显提升(但是ResNet v2结构不可用)
平滑标签
bs=250,lr=0.4(线性增长warm up 2epc),[100, 150]x0.1,共200epc
SGD(model.parameters(), lr=learning_rate, weight_decay=0.0005, momentum=0.9, nesterov=True)
zero_init_residual=True
所有情况连续跑三次实验(动态标签参见5.2中的危险想法)
| eps | best acc | worst acc |
|---|---|---|
| 0.00 | 79.99 | 79.57 |
| 0.01 | 79.99 | 79.90 |
| 0.03 | 80.40 | 80.03 |
| 0.1 | 80.63 | 80.28 |
| 0.2 | 80.47 | 80.09 |
| 0.3 | 80.22 | 79.43 |
| 0.5 | 79.13 | 79.03 |
| 0.1 动态标签 | 80.05 |
学习率调控方法
bs=250,共200epc,平滑标签eps=0.1
对于Multistep:lr=0.4(线性增长warm up 2epc),[100, 150]x0.1
对于CosDecay:lr=0.4(线性增长warm up 2epc),余弦衰减
对于CosCycle:lr=0.64
4cycle32epc(lr_rate:1/6~1)
3cycle16epc(lr_rate:1/36~1/6)
3cycle8epc(lr_rate:1/216~1/36)
对于CosCycleA:lr=0.64
12cycle16epc(lr_rate:1/200~1)
cool down 8epc(lr_rate:1/200)
SGD(model.parameters(), lr=learning_rate, weight_decay=0.0005, momentum=0.9, nesterov=True)
zero_init_residual=True
所有情况连续跑三次实验
| method | best acc |
|---|---|
| MultiStep | 80.63 |
| CosDecay | 81.20 |
| CosCycle | 80.04 |
| CosCycleA | 78.65 |
比较神奇的事情:CIFAR100上使用cosdec学习率调控策略时,smooth label完全没用,用不用都比砍两刀好,不管砍两刀用不用smooth label。
Wide ResNet26 (k=4)
| method | best acc |
|---|---|
| CosDecay | 80.14 |
| CosDecay+smtLB | 80.08 |
| MultiStep | 79.02 |
| MultiStep+smtLB | 79.78 |

若有收获,就点个赞吧
0 人点赞
