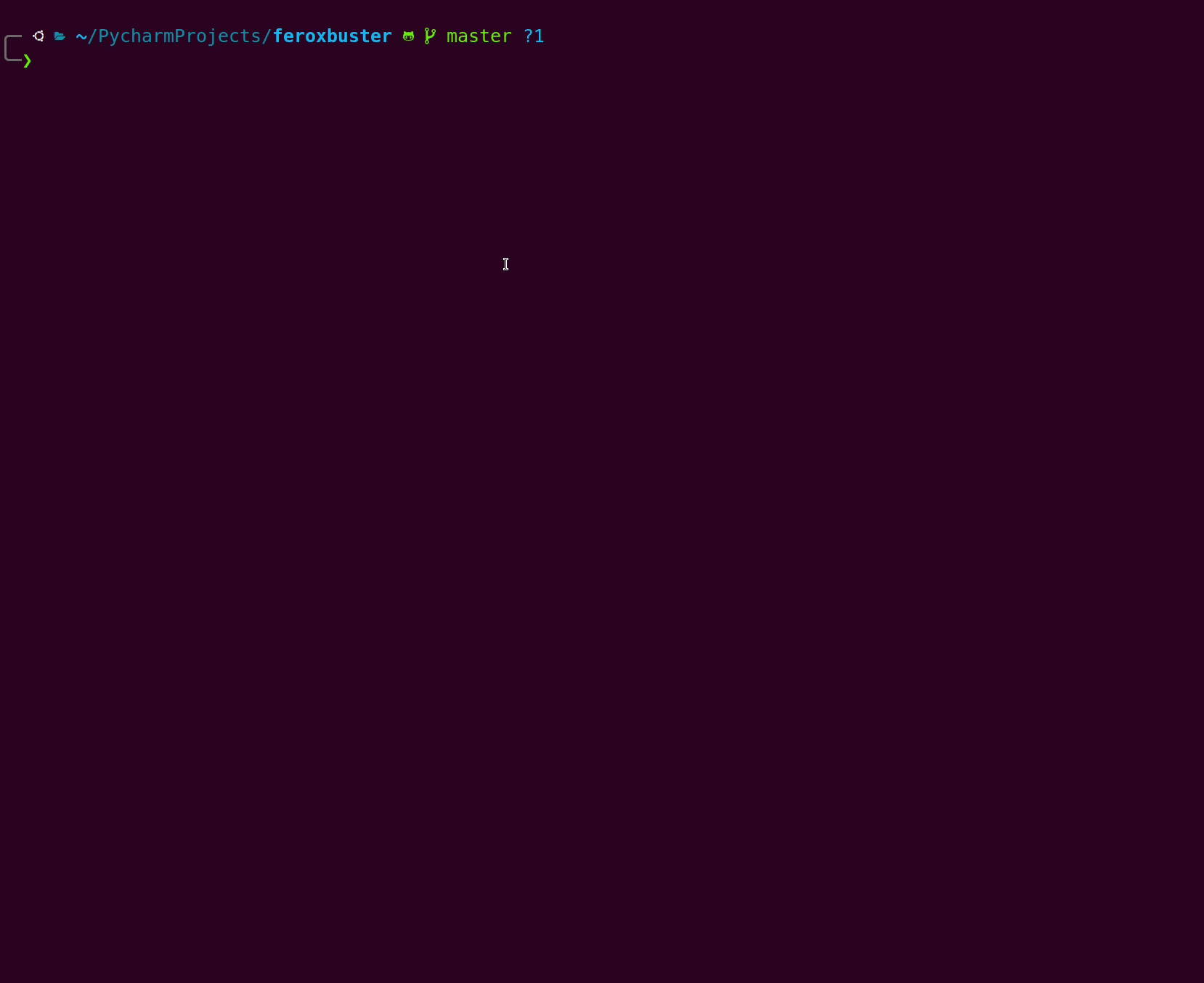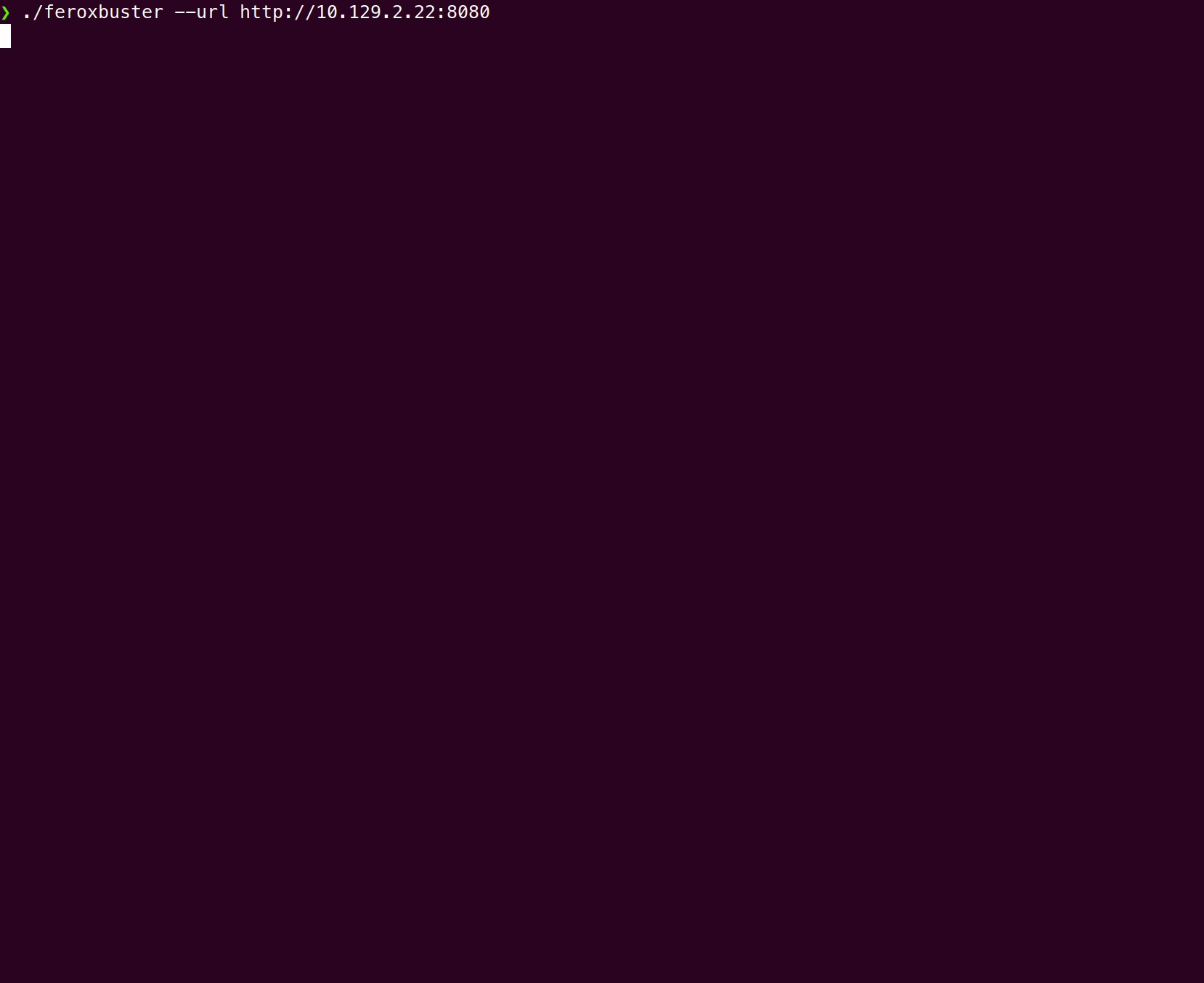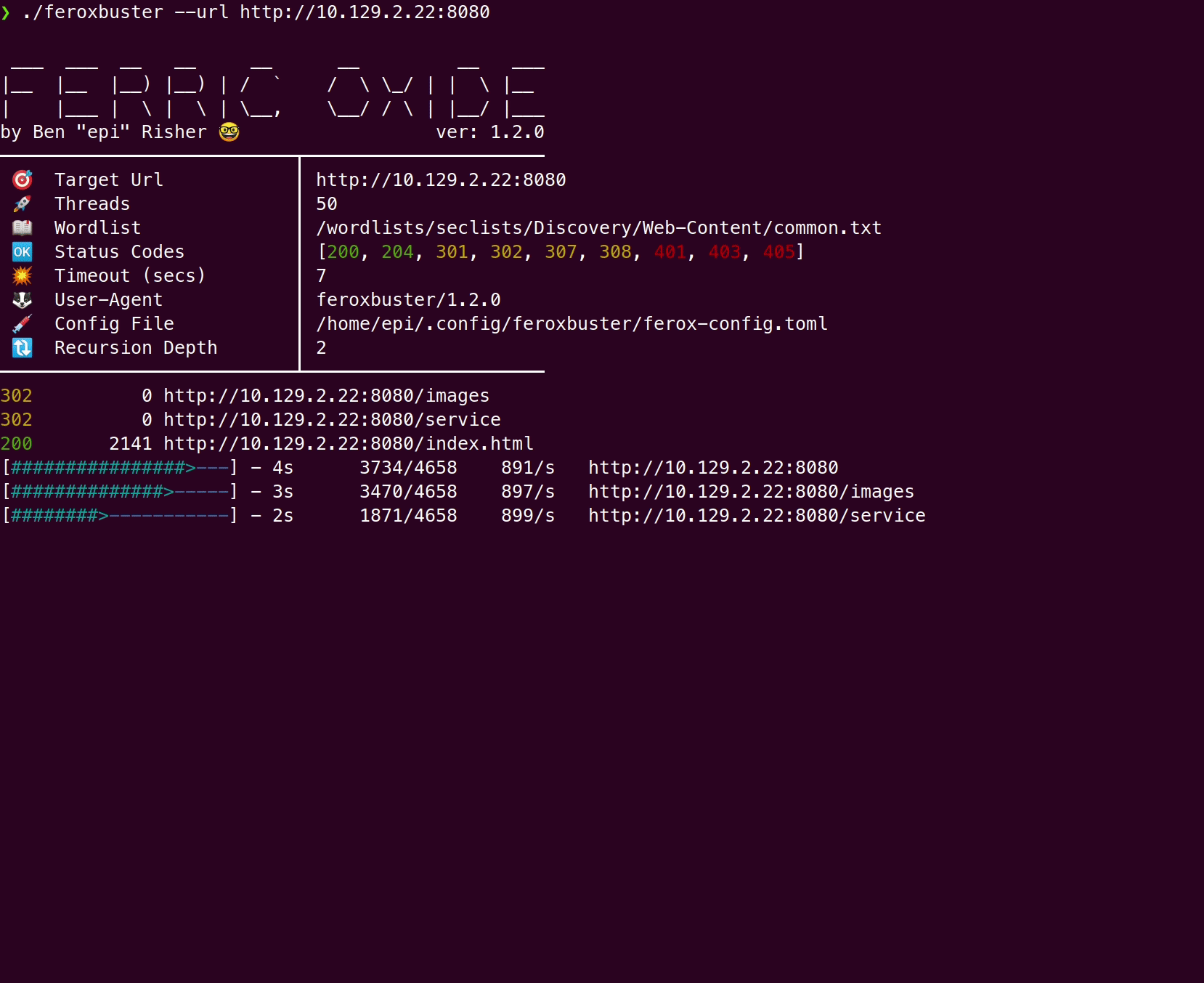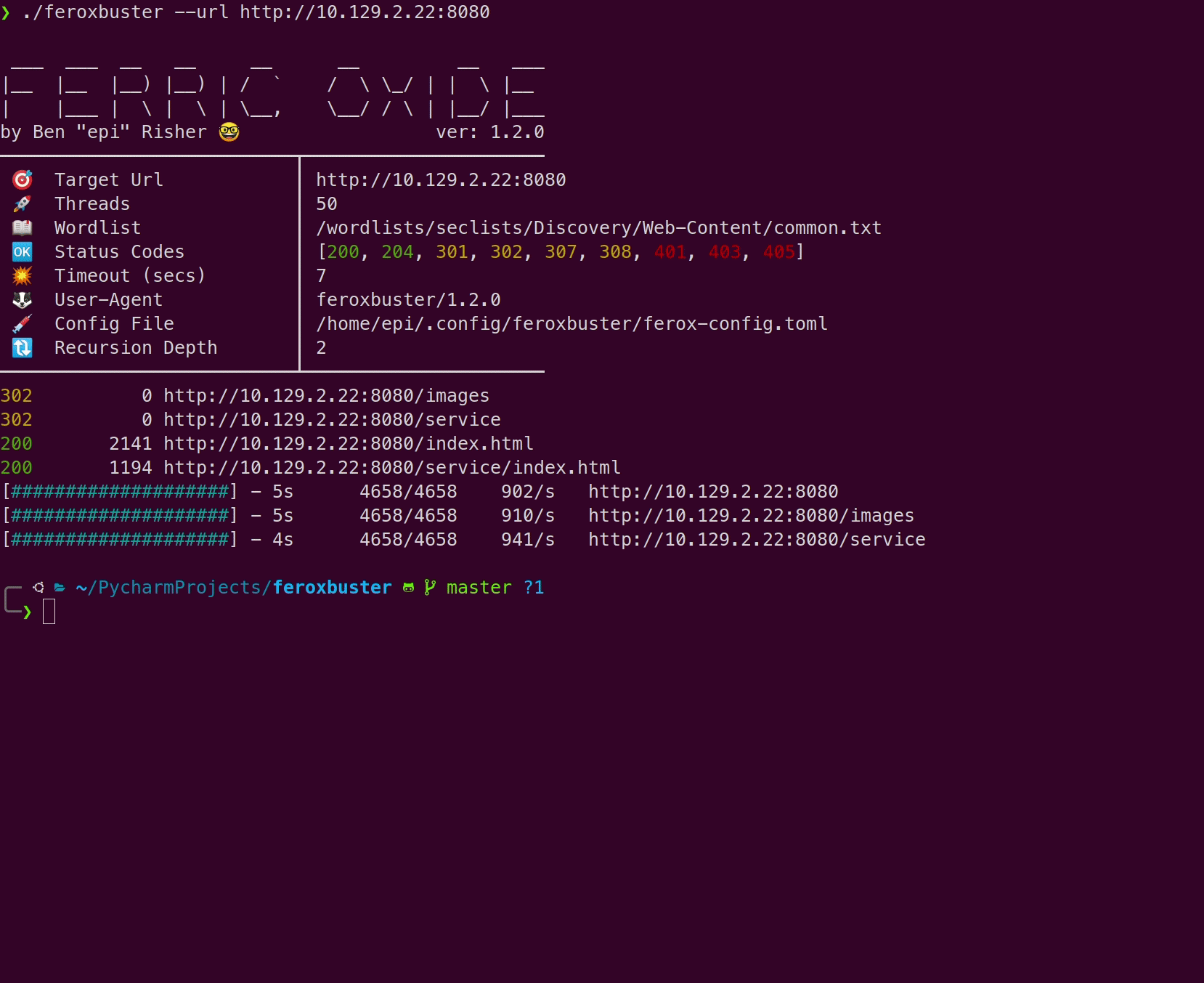
- 运行示例
- ⚙️ 配置
- ? 扫描显示解释
- 用法示例
- 多个值
- 包括标题
- IPv6,非递归扫描,启用了INFO级日志记录
- 阅读来自STDIN的网址;仅将产生的网址传递到另一个工具
- 通过Burp的代理流量
- 通过SOCKS代理的代理流量(包括DNS查找)
- 通过查询参数传递身份验证令牌
- 从响应主体中提取链接(v1.1.0)
- 限制并发扫描总数(新增v1.2.0)
- 按状态码过滤响应(新增v1.3.0)
- 暂停活动扫描(新增功能v1.4.0)
- 根据状态码重播对代理的响应(新增v1.5.0)
- 按字数和行数过滤响应(新增v1.6.0)
- 使用正则表达式过滤响应(中的新增功能v1.8.0)
- 停止并恢复扫描(—resume-from FILE)(新增v1.9.0)
- 限制扫描时间(v1.10.0)
- 从robots.txt中提取链接(v1.10.2)
- 按与给定页面的相似性过滤响应(模糊过滤器)(新增v1.11.0)
- 交互式取消递归扫描(新增功能v1.12.0)
- 带类似工具的比较
- ? 常见问题/问题(FAQ)
原文: feroxbuster强制浏览工具|预测资源位置|文件目录资源枚举GitHub - epi052/feroxbuster: A fast, simple, recursive content discovery tool written in Rust.
feroxbuster是旨在执行强制浏览的工具。
强制浏览是一种攻击,其目的是枚举和访问Web应用程序未引用但仍可被攻击者访问的资源。
feroxbuster使用暴力结合单词列表在目标目录中搜索未链接的内容。这些资源可能存储有关Web应用程序和操作系统的敏感信息,例如源代码,凭据,内部网络地址等。
此攻击也称为可预测资源位置,文件枚举,目录枚举和资源枚举。
运行示例
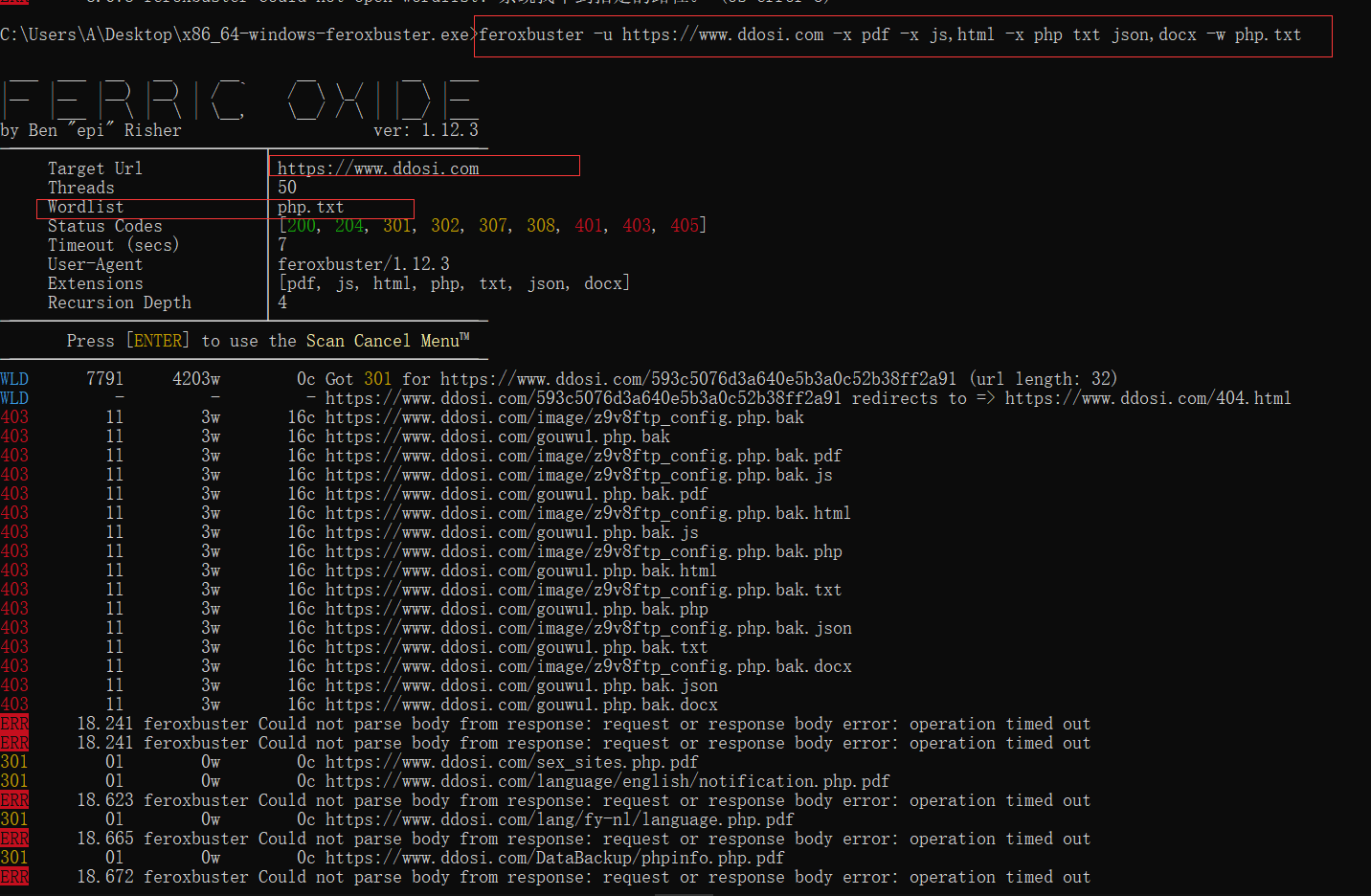
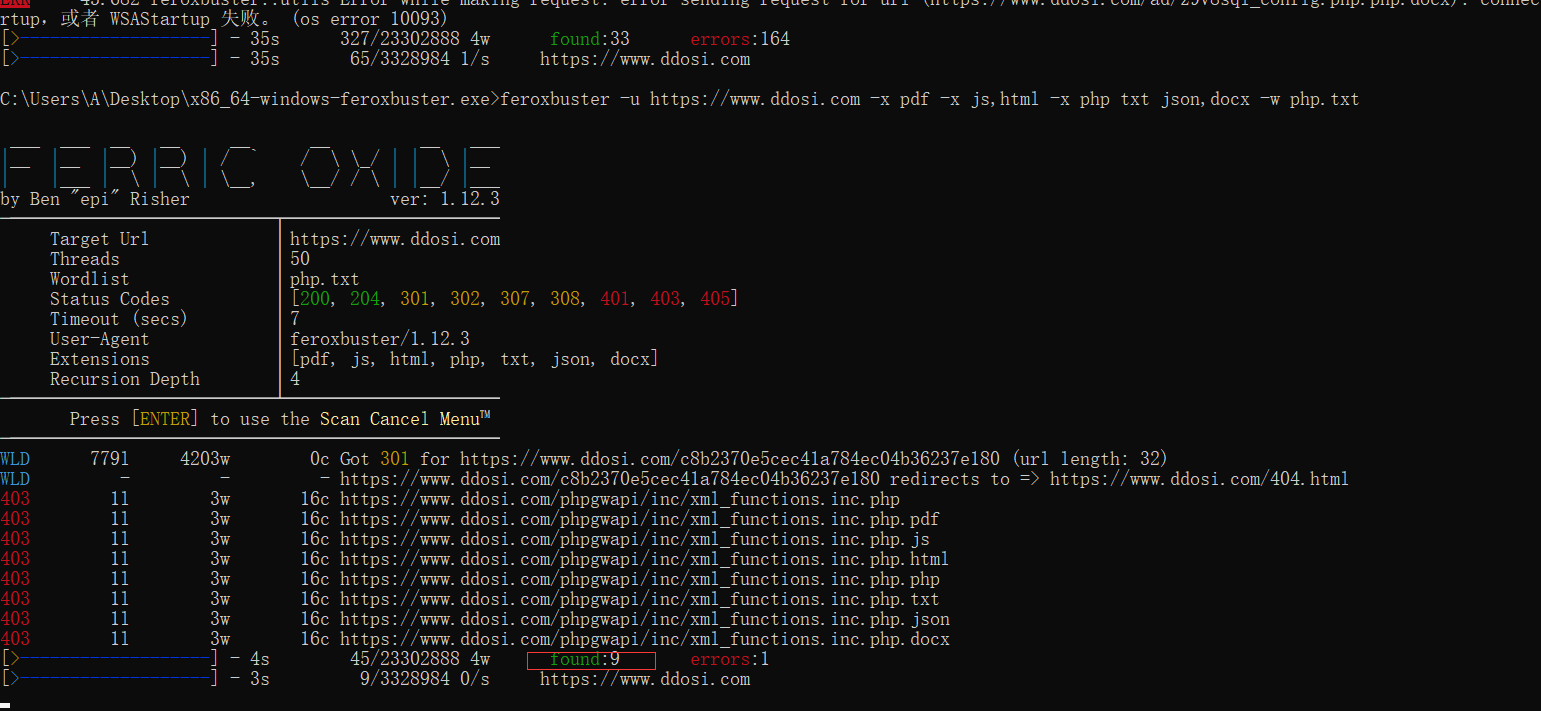
⚙️ 配置
默认值
配置从以下内置于二进制文件中的默认值开始:
- 超时:7秒
- 按照重定向: false
- 密码表: /usr/share/seclists/Discovery/Web-Content/raft-medium-directories.txt
- 线程: 50
- 详细程度:(0未启用日志记录)
- scan_limit :(0并发扫描没有限制)
- status_codes: 200 204 301 302 307 308 401 403 405
- 用户代理: feroxbuster/VERSION
- 递归深度: 4
- 自动过滤通配符- true
- 输出: stdout
- save_state :(收到true时在cwd中创建状态文件Ctrl+C)
高层的线程和连接限制
本节说明-t和-L选项如何共同确定扫描的整体积极性。这些选项设置的两个值的组合确定了目标受到打击的程度,并且在某种程度上还决定了本地计算机上将消耗多少资源。
关于绿色线程的说明
feroxbuster与传统的内核/ OS线程相比,使用所谓的绿色线程。这意味着(从高层次上)线程是在单个运行的进程中完全在用户空间中实现的。结果,对操作系统而言,具有30个绿色线程的扫描在操作系统看来将是一个单独的进程,就内核而言,没有与此相关的其他轻量级进程。因此,nproc为指定更大的值时,不会对process()限制产生任何影响-t。但是,这些线程仍将占用文件描述符,因此nlimit在增加线程数量时,需要确保您拥有合适的集合。有关设置适当nlimit值的更多详细文档,请参见“没有可用的文件描述符”。 常见问题解答部分
线程和连接限制:实现
- 线程:此-t选项指定扫描期间每个目录的最大活动线程数
- 连接限制:该-L选项指定每个线程的最大活动连接数
线程和连接限制:示例
在任何给定时间真正只有30个活动请求到站点-t 30 -L 1是必要的。使用该位置-t 30 -L 2将导致该站点在任何给定时间最多处理60个请求。等等。有关此内容的对话,请参见问题#126,该问题可能会提供更多(或更少)的清晰度?
ferox-config.toml
设置内置默认值后,ferox-config.toml配置文件中定义的任何值都将覆盖内置默认值。
feroxbusterferox-config.toml在以下位置搜索(按显示的顺序):
- /etc/feroxbuster/ (全球)
- CONFIG_DIR/ferxobuster/ (每用户)
- 与feroxbuster可执行文件相同的目录(每用户)
- 用户的当前工作目录(每个目标)
CONFIG_DIR 定义如下:
- Linux的:$XDG_CONFIG_HOME或$HOME/.config即/home/bob/.config
- MacO:$HOME/Library/Application Support即/Users/bob/Library/Application Support
- Windows:{FOLDERID_RoamingAppData}即C:\Users\Bob\AppData\Roaming
如果找到多个有效的配置文件,则每个文件都将覆盖先前找到的值。
如果未找到配置文件,则在此阶段没有任何反应。
例如,假设我们在扫描时更喜欢使用其他单词列表作为默认列表;我们可以wordlist在配置文件中设置该值以覆盖默认设置。
有兴趣的注意事项:
- 可以只指定要更改的值,而无需指定其他任何内容
- 中的变量名称ferox-config.toml必须与命令行中的变量名称匹配
# ferox-config.tomlwordlist = “ /wordlists/jhaddix/all.txt ”
包含所有可用设置示例的预制配置文件可在中找到ferox-config.toml.example。
# ferox-config.toml# Example configuration for feroxbuster## If you wish to provide persistent settings to feroxbuster, rename this file to ferox-config.toml and make sure# it resides in the same directory as the feroxbuster binary.## After that, uncomment any line to override the default value provided by the binary itself.## Any setting used here can be overridden by the corresponding command line option/argument## wordlist = "/wordlists/jhaddix/all.txt"# status_codes = [200, 500]# filter_status = [301]# threads = 1# timeout = 5# proxy = "http://127.0.0.1:8080"# replay_proxy = "http://127.0.0.1:8081"# replay_codes = [200, 302]# verbosity = 1# scan_limit = 6# quiet = true# json = true# output = "/targets/ellingson_mineral_company/gibson.txt"# debug_log = "/var/log/find-the-derp.log"# user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0"# redirects = true# insecure = true# extensions = ["php", "html"]# no_recursion = true# add_slash = true# stdin = true# dont_filter = true# extract_links = true# depth = 1# filter_size = [5174]# filter_regex = ["^ignore me$"]# filter_similar = ["https://somesite.com/soft404"]# filter_word_count = [993]# filter_line_count = [35, 36]# queries = [["name","value"], ["rick", "astley"]]# save_state = false# time_limit = 10m# headers can be specified on multiple lines or as an inline table## inline example# headers = {"stuff" = "things"}## multi-line example# note: if multi-line is used, all key/value pairs under it belong to the headers table until the next table# is found or the end of the file is reached## [headers]# stuff = "things"# more = "headers"
命令行解析
最后,在解析了可用的配置文件之后,命令行上给出的任何选项/参数都将覆盖设置为内置或配置文件值的所有值。
用法:feroxbuster [FLAGS] [OPTIONS] --url <URL>...FLAGS:-f, --add-slash 追加/到每个请求-D, --dont-filter 不要自动过滤通配符响应-e, --extract-links Extract links from response body (html, javascript, etc...); make new requests based onfindings (default: false)-h, --help Prints help information-k, --insecure 禁用TLS证书验证--json Emit JSON logs to --output and --debug-log instead of normal text-n, --no-recursion 不递归扫描-q, --quiet 只输出url;不输出状态码,响应大小,运行配置等…-r, --redirects 遵循重定向--stdin 从stdin读取url-V, --version 输出版本信息-v, --verbosity 增加详细程度(使用-vv或更大的效果。[注意]4 -v可能太多)参数:--debug-log <FILE> Output file to write log entries (use w/ --json for JSON entries)-d, --depth <RECURSION_DEPTH> 最大递归深度,深度为0表示无限递归(默认值:4)-x, --extensions <FILE_EXTENSION>... …要搜索的文件扩展名(例如:-x php -x pdf js)-N, --filter-lines <LINES>... Filter out messages of a particular line count (ex: -N 20 -N 31,30)-X, --filter-regex <REGEX>...通过在响应体上匹配正则表达式过滤掉消息(例如:-X '^ignore me$')--filter-similar-to <UNWANTED_PAGE>...过滤掉与给定页面相似的页面(例如——Filter -similar-to http://site.xyz/soft404)-S, --filter-size <SIZE>... 过滤掉特定大小的消息(例如:-S 5120 -S 4927,1970)-C, --filter-status <STATUS_CODE>... 过滤掉状态码(拒绝列表)(例如:-C 200 -C 401)-W, --filter-words <WORDS>... 过滤掉特定单词计数的消息(例如:- w312 - w91,82)-H, --headers <HEADER>... 指定HTTP报头(例如:-H报头:val 'stuff: things')-o, --output <FILE> 要写入结果的输出文件(json项使用w/——json-p, --proxy <PROXY>用于请求的代理(例如:http(s)://host:port, socks5(h)://host:port)-Q, --query <QUERY>... 指定URL查询参数(例如:-Q token=stuff -Q secret=key)- r, replay-codes < REPLAY_CODE >…-R, --replay-codes <REPLAY_CODE>...发现时通过重播代理发送的状态码(默认值:——Status - Codes值)-P, --replay-proxy <REPLAY_PROXY>仅通过重播代理发送未过滤的请求,而不是所有请求--resume-from <STATE_FILE>要恢复部分完成扫描的状态文件(例如——resume-from ferox-1606586780.state)-L, --scan-limit <SCAN_LIMIT> 限制总并发扫描数(默认:0,即没有限制)-s, --status-codes <STATUS_CODE>...要包含的状态码(允许列表)(默认值:200 204 301 302 307 308 401 403 405)-t, --threads <THREADS> 并发线程数(默认为50)--time-limit <TIME_SPEC> 所有扫描的总运行时间(例如:——time- Limit 10m)-T, --timeout <SECONDS> 请求超时前的秒数(默认为7秒)-u, --url <URL>... 目标URL(必需的,除非使用——stdin)-a, --user-agent <USER_AGENT> 用户代理(默认:feroxbuster/VERSION)-w, --wordlist <FILE> 密码字典的路径
? 扫描显示解释
feroxbuster 尝试做到直观且易于理解,但是,如果您想知道扫描的任何输出及其含义,那么这是适合您的部分!
发现资源
当feroxbuster找到尚未过滤的响应时,将在进度条上方报告该响应,并且其外观类似于下图。
此处显示的行数,字数和字节数可用于过滤这些响应
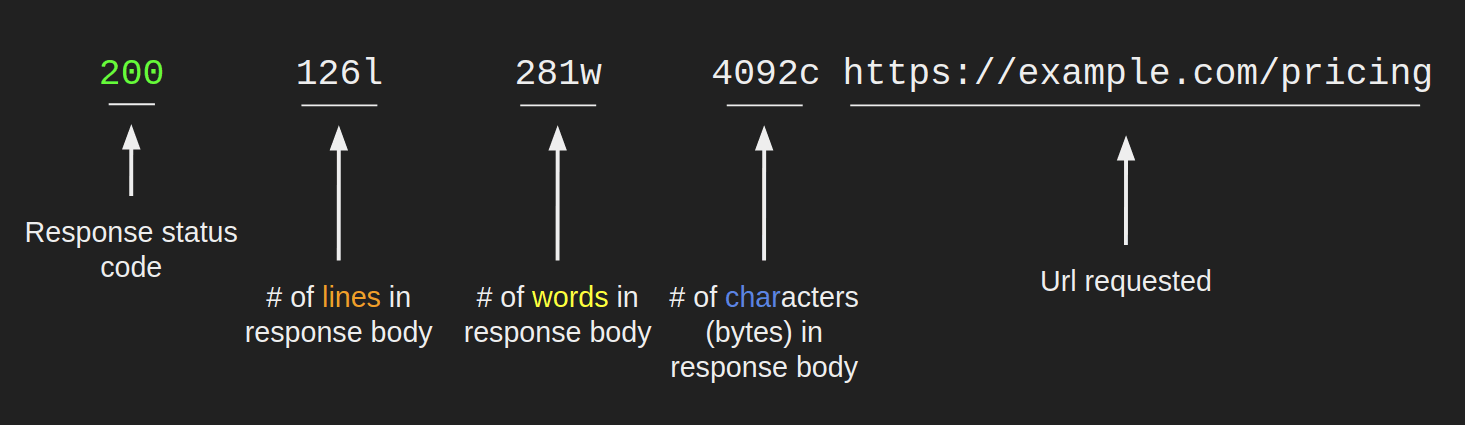
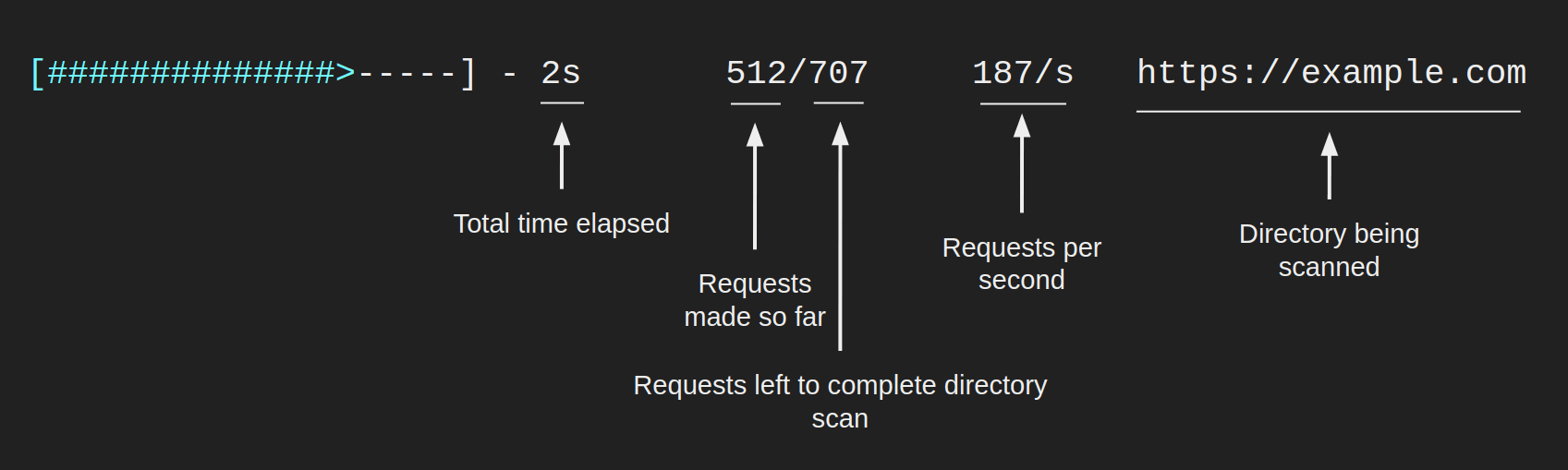
整体扫描进度栏
顶部进度条(黄色)跟踪整个扫描状态。下图描述了其字段。
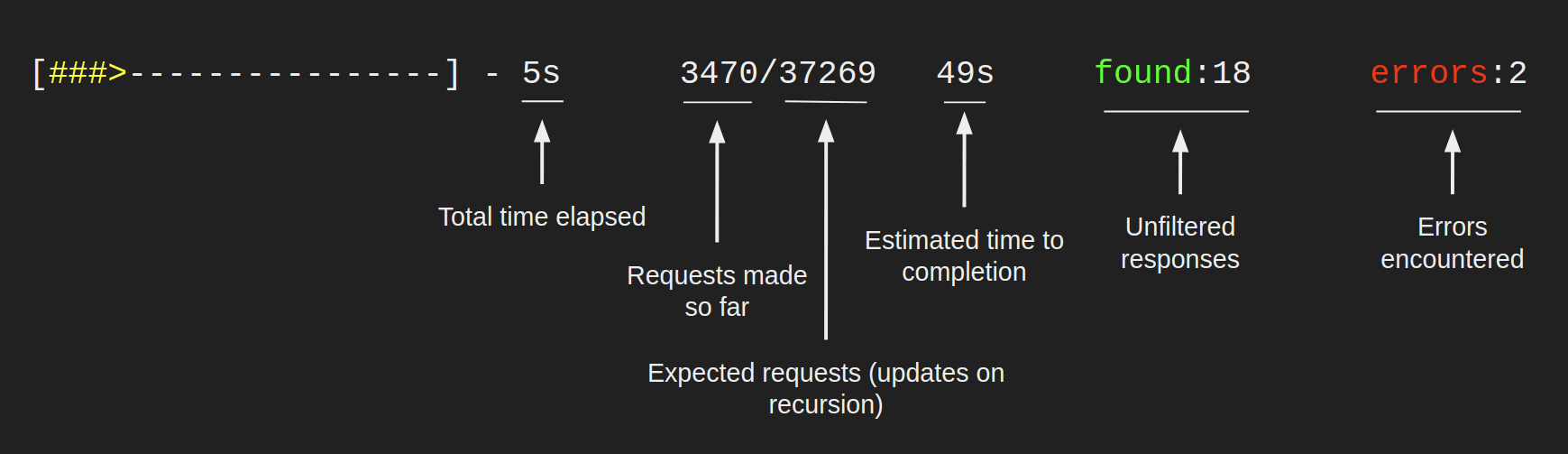
目录扫描进度栏
所有其他进度条(青色)表示对一个特定目录的扫描,其外观类似于以下内容。
用法示例
多个值
具有多个值的选项非常灵活。考虑以下指定扩展名的方法:
./feroxbuster -u http://127.1 -x pdf -x js,html -x php txt json,docx
上面的命令将.pdf,.js,.html,.php,.txt,.json和.docx添加到每个网址
上面的所有方法(多个标志,空格分隔,逗号分隔等)都是有效且可互换的。网址,标头,状态代码,查询和大小过滤器也是如此。
包括标题
./feroxbuster -u http://127.1 -H Accept:application/json "Authorization: Bearer {token}"
IPv6,非递归扫描,启用了INFO级日志记录
./feroxbuster -u http://[::1] --no-recursion -vv
阅读来自STDIN的网址;仅将产生的网址传递到另一个工具
cat targets | ./feroxbuster --stdin --quiet -s 200 301 302 --redirects -x js | fff -s 200 -o js-files
通过Burp的代理流量
./feroxbuster -u http://127.1 --insecure --proxy http://127.0.0.1:8080
通过SOCKS代理的代理流量(包括DNS查找)
./feroxbuster -u http://127.1 --proxy socks5h://127.0.0.1:9050
通过查询参数传递身份验证令牌
./feroxbuster -u http://127.1 --query token=0123456789ABCDEF
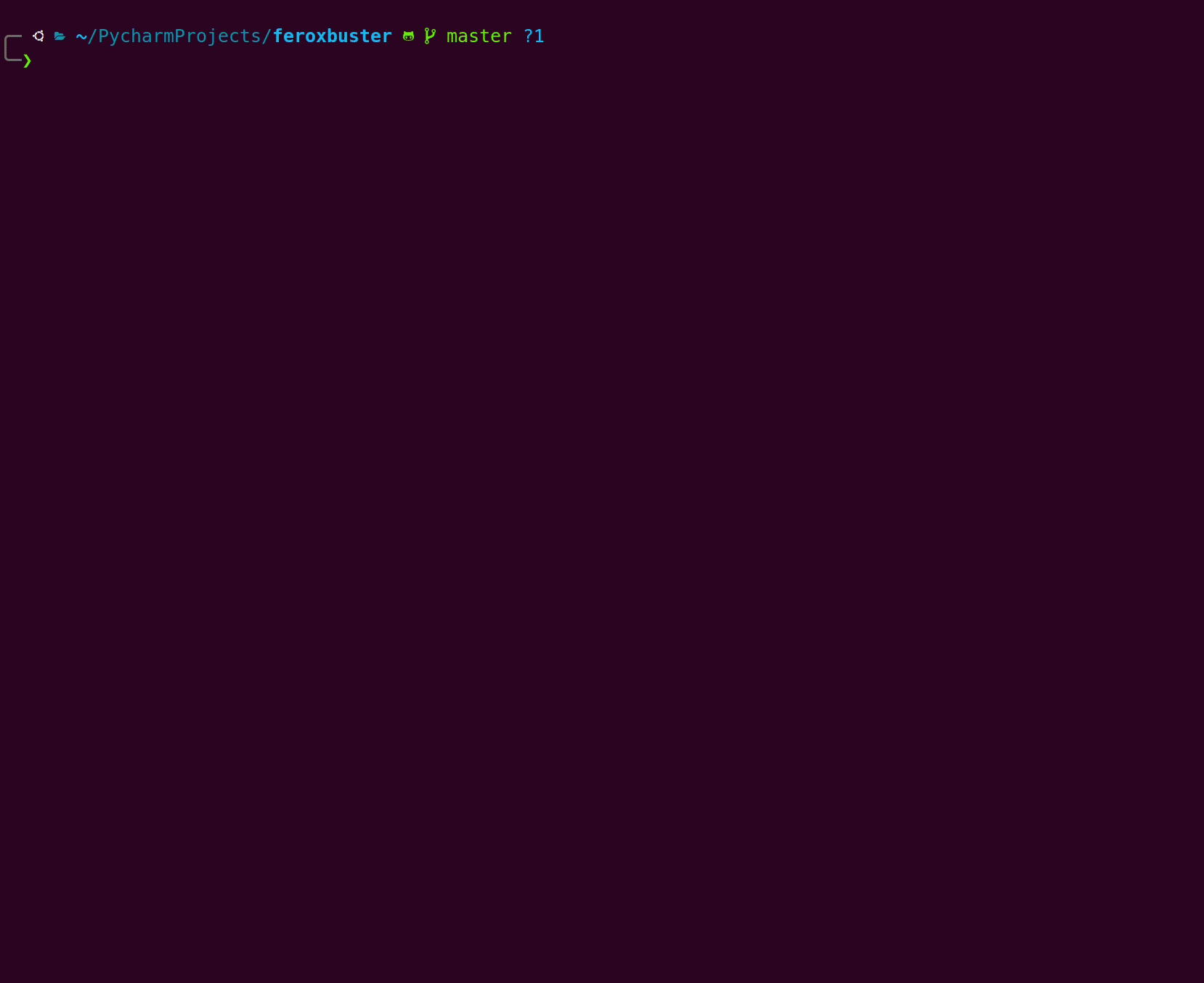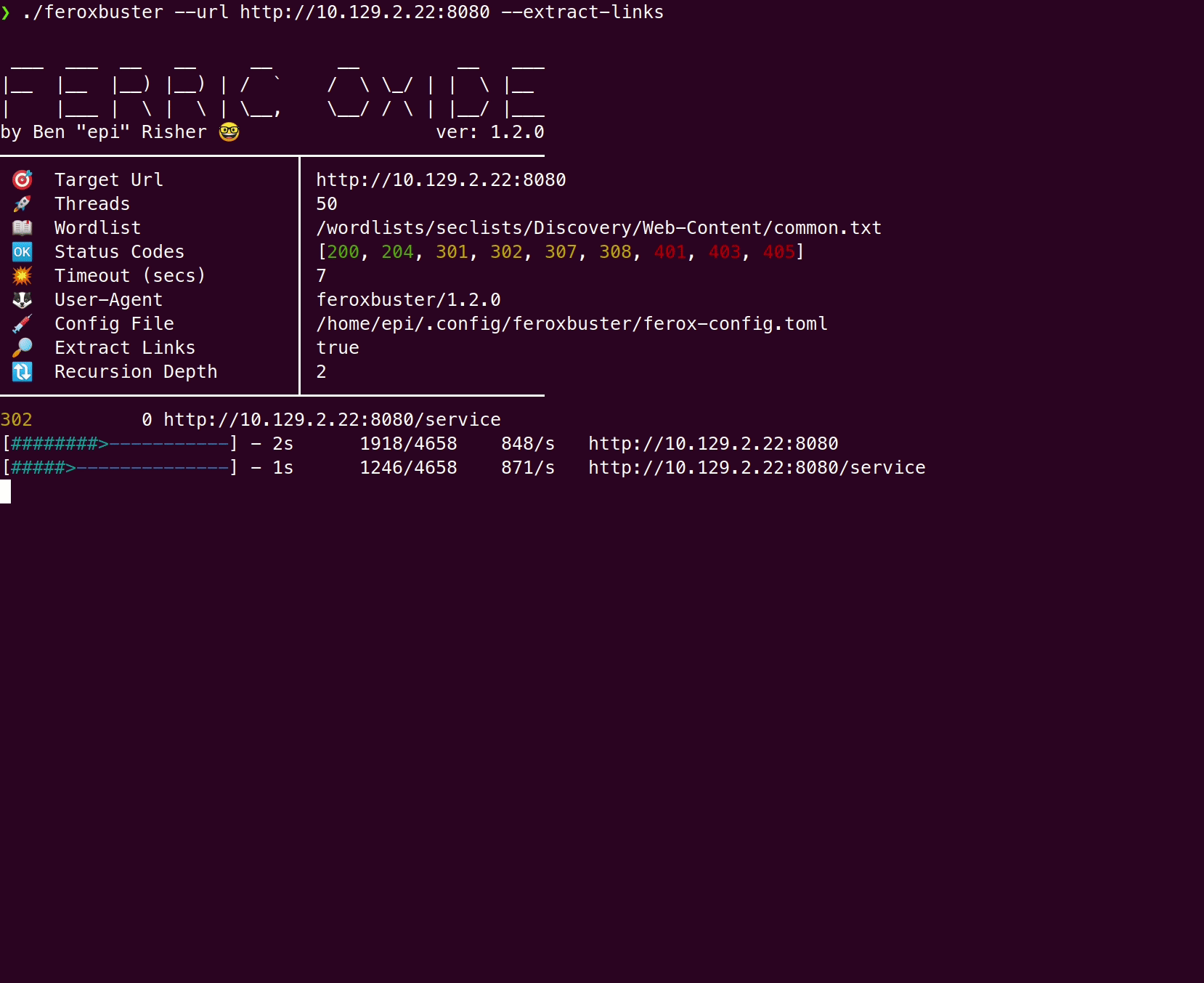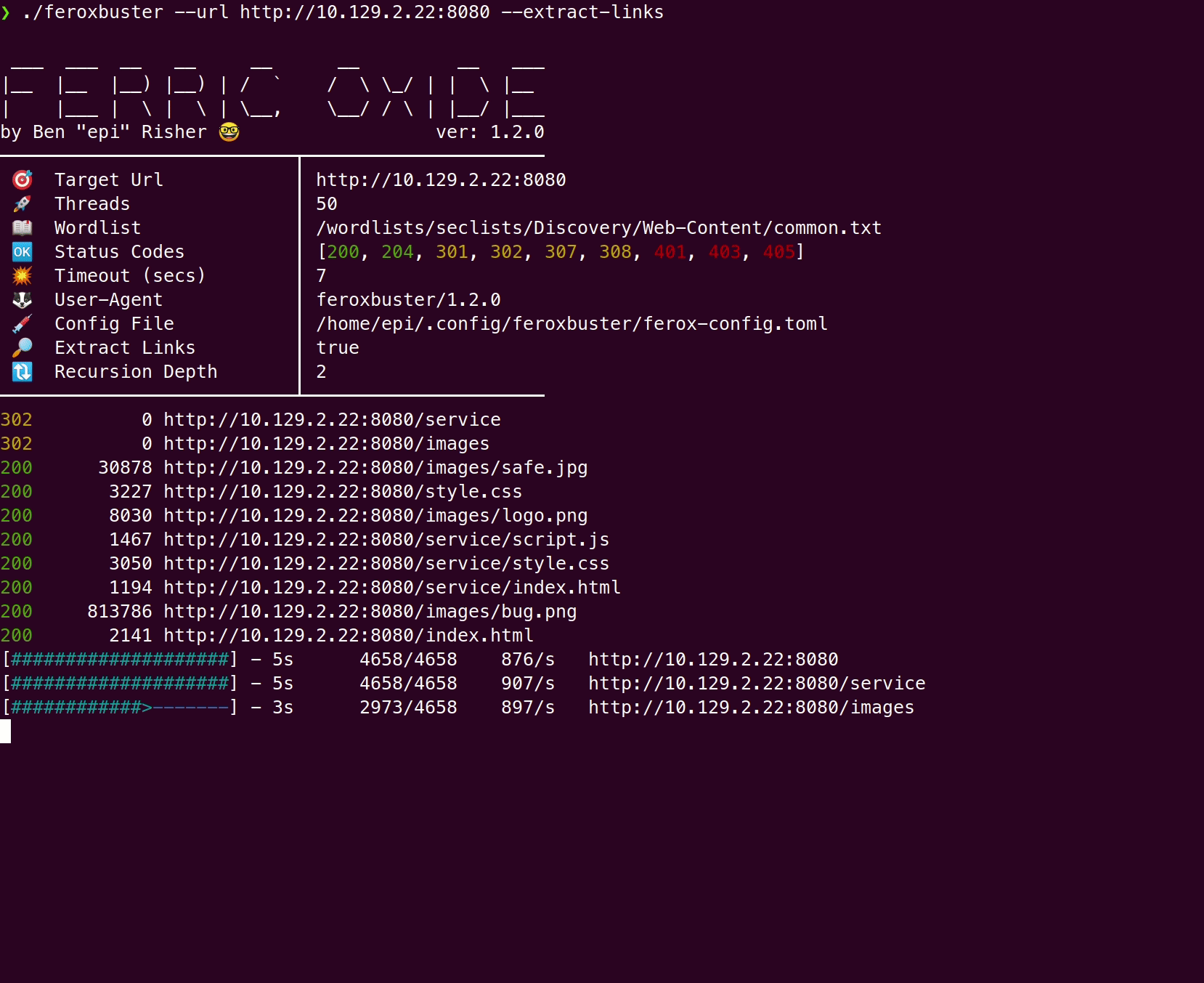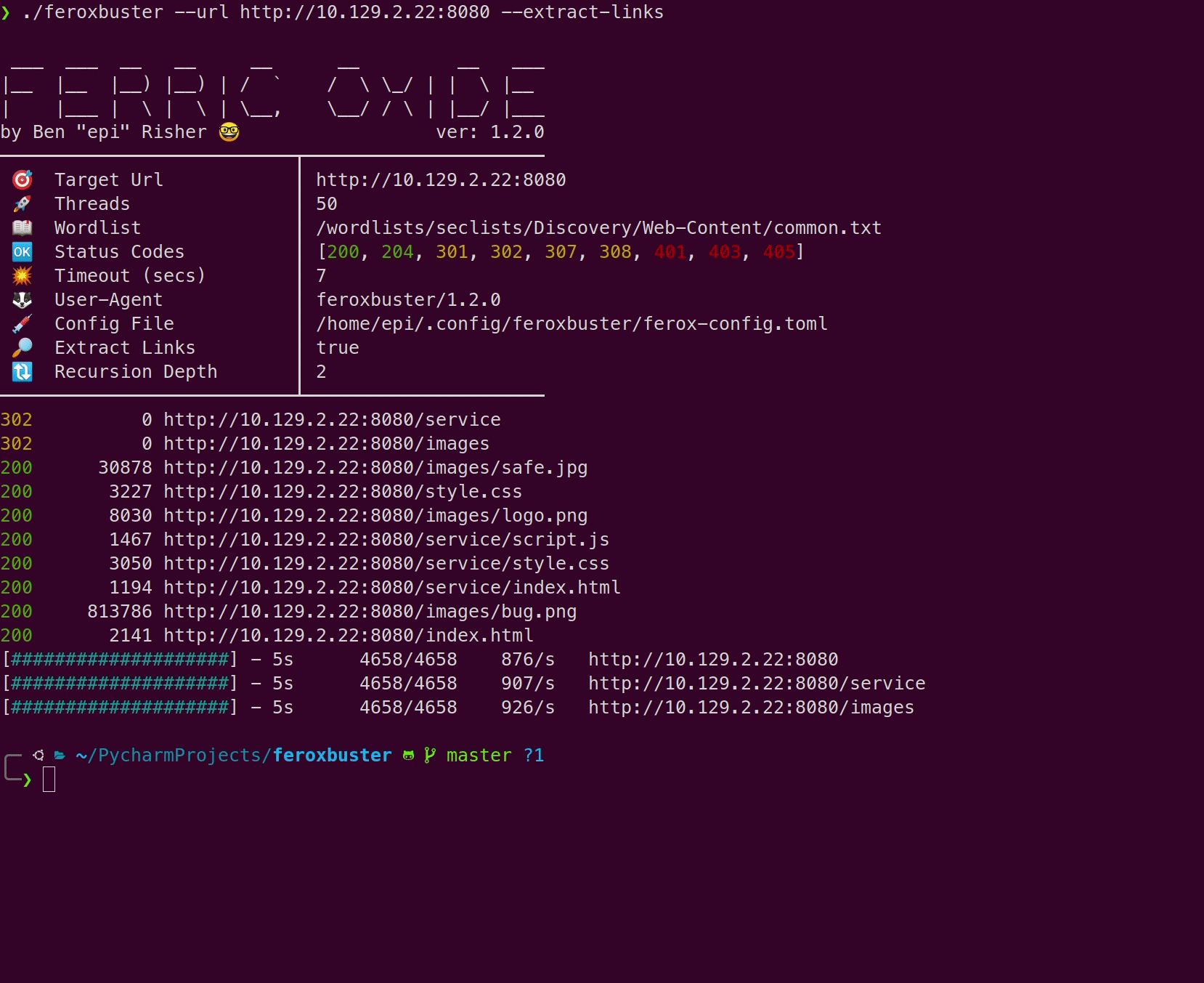
从响应主体中提取链接(v1.1.0)
在有效响应的正文(html,javascript等)中搜索要扫描的其他端点。这就变成 feroxbuster了同时查找链接和未链接内容的混合文件。
已—extract-links启用的示例请求/响应:
- 提出请求 http://example.com/index.html
- 接收并读body入响应
- 搜索的body绝对链接和相对链接(即homepage/assets/img/icons/handshake.svg)
- 添加以下目录以进行递归扫描:
- 发出一个请求 http://example.com/homepage/assets/img/icons/handshake.svg
这是仅单词列表扫描与—extract-links 使用Hack the Box中的Feline的比较:
仅密码表
用 —extract-links
限制并发扫描总数(新增v1.2.0)
限制允许在任何给定时间运行的扫描数量。递归仍将识别新目录,但是新发现的目录仅在活动扫描总数降至传递给的值以下时才能开始扫描 —scan-limit。
按状态码过滤响应(新增v1.3.0)
1.3.0版对过滤系统进行了大修,这将允许您以最小的努力添加各种过滤器。第一个这样的过滤器是状态代码过滤器。当响应从扫描的服务器返回时,将对照已知过滤器列表检查每个响应,并根据设置的过滤器显示是否显示。
./feroxbuster -u http://127.1 --filter-status 301
暂停活动扫描(新增功能v1.4.0)
注意:v1.12.0向暂停/恢复功能添加了一个交互式菜单。活动扫描仍可以暂停,但是,现在您可以选择取消扫描,而不仅仅是看到微调器。
可以通过按ENTER键来暂停和恢复扫描(如下所示,请参见v1.12.0的条目以获取最新的视觉效果)
根据状态码重播对代理的响应(新增v1.5.0)
在—replay-proxy和—replay-codes选项加入,以此来只发送有选择的几个应对的代理。与—proxy每个请求的代理形成鲜明对比。
想象一下,您只关心代理具有状态代码200或302(或者只是不想弄乱burp历史)的响应。这两个选项将使您可以微调哪些是代理,哪些没有。
./feroxbuster -u http://127.1 --replay-proxy http://localhost:8080 --replay-codes 200 302 --insecure
注意:这意味着对于每个符合重播条件的响应,您最终都会发送第二次生成该响应的请求。根据目标和您的参与度(如果有),从产生流量的角度来看可能没有意义。
按字数和行数过滤响应(新增v1.6.0)
除了过滤响应的大小外,版本1.6.0还增加了基于响应正文中包含的行数和/或单词数来过滤响应的功能。此更改还导致更改了向用户显示的信息。本节将详细介绍新信息以及如何通过提供的新过滤器使用新信息。
输出示例:
200 10l 212w 38437c https://example-site.com/index.html
上面有五列输出:
- 第1栏:状态代码-可以使用 -C|—filter-status
- 第2列:行数-可以使用 -N|—filter-lines
- 第3栏:字数-可以用过滤 -W|—filter-words
- 第4列:字节数(总大小)-可以使用 -S|—filter-size
- 列5:找到资源的网址
使用正则表达式过滤响应(中的新增功能v1.8.0)
1.3.0版对过滤系统进行了大修,这将允许您以最小的努力添加各种过滤器。最新添加的是正则表达式过滤器。当响应从扫描的服务器返回时,将根据过滤器的正则表达式检查响应的主体。如果在正文中找到该表达式,则将过滤掉该响应。
注意:使用正则表达式过滤较大的响应或许多正则表达式可能会对性能产生负面影响。
./feroxbuster -u http://127.1 --filter-regex '[aA]ccess [dD]enied.?' --output results.txt --json
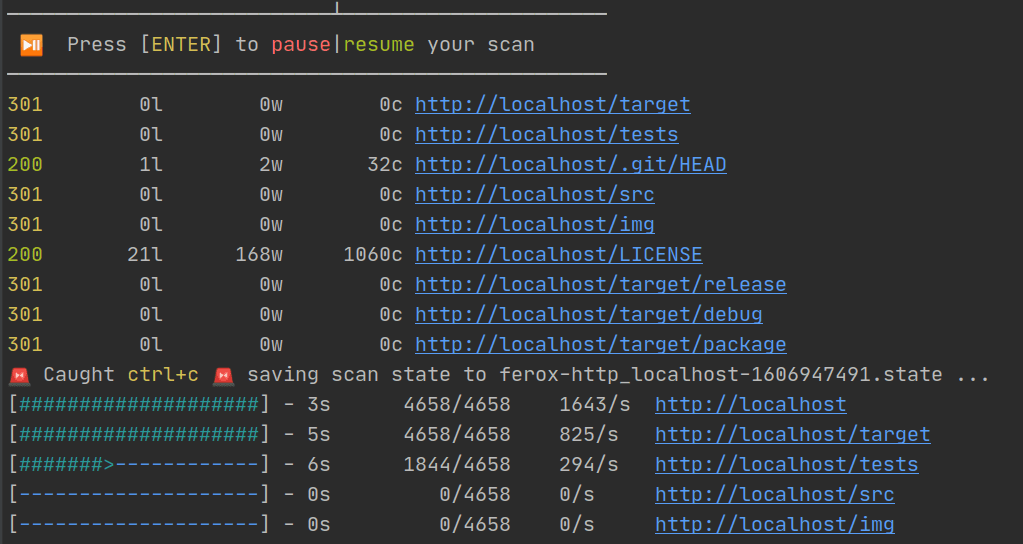
停止并恢复扫描(—resume-from FILE)(新增v1.9.0)
1.9.0版增加了一些功能,可以完全停止扫描,并从磁盘上的文件恢复相同的扫描。
Ctrl+C扫描过程中的简单操作将创建一个文件,其中包含有关已取消的扫描的信息。
//状态文件的示例片段{"scans": [{"id": "057016a14769414aac9a7a62707598cb","url": "https://localhost.com","scan_type": "Directory","complete": true},{"id": "400b2323a16f43468a04ffcbbeba34c6","url": "https://localhost.com/css","scan_type": "Directory","complete": false}],"config": {"wordlist": "/wordlists/seclists/Discovery/Web-Content/common.txt","...": "..."},"responses": [{"type": "response","url": "https://localhost.com/Login","path": "/Login","wildcard": false,"status": 302,"content_length": 0,"line_count": 0,"word_count": 0,"headers": {"content-length": "0","server": "nginx/1.16.1"}}]},
根据上面的示例图像,可以使用来恢复相同的扫描feroxbuster —resume-from ferox-http_localhost-1606947491.state。不会重新扫描已经完成的目录,但是将从头开始部分完成的扫描。
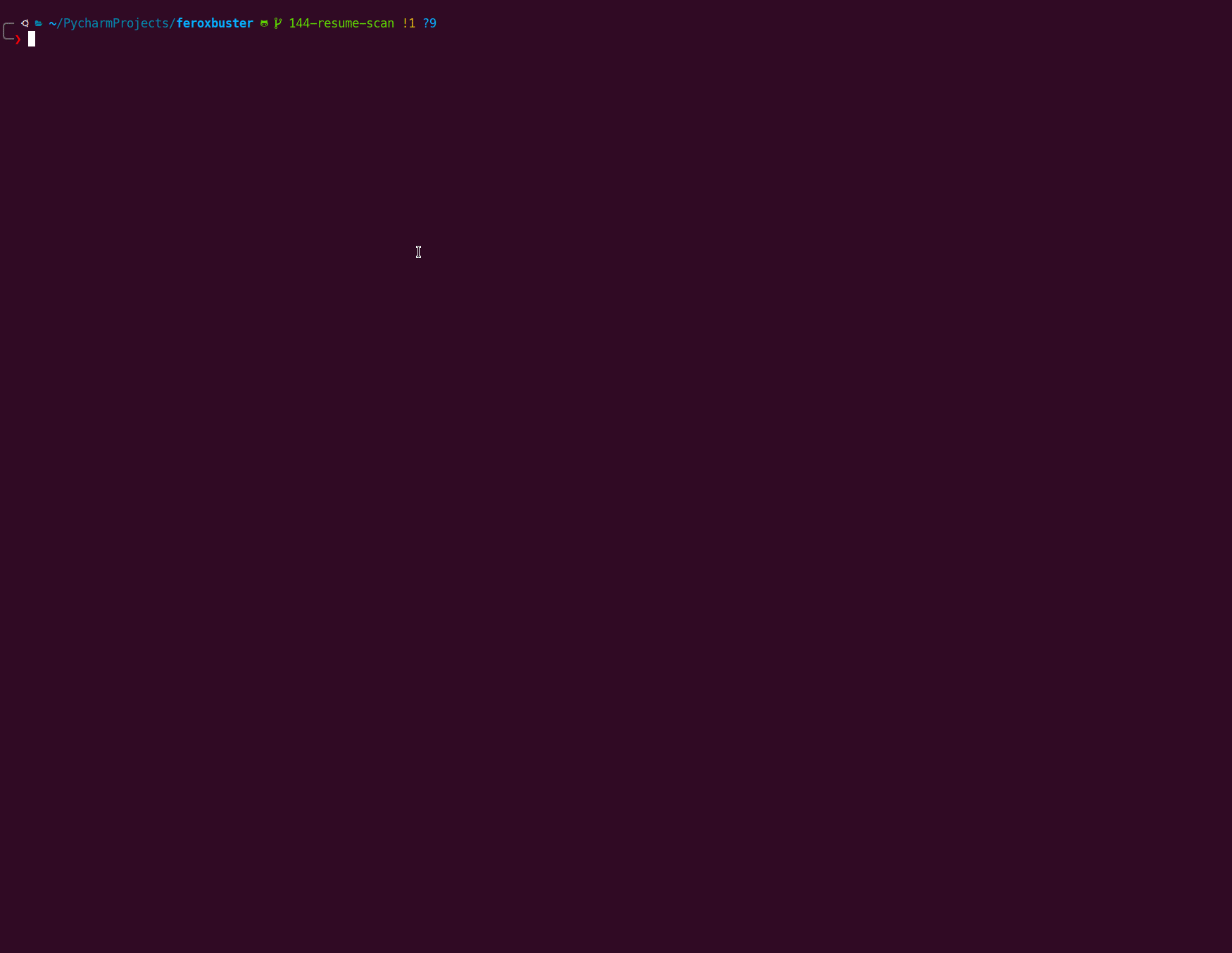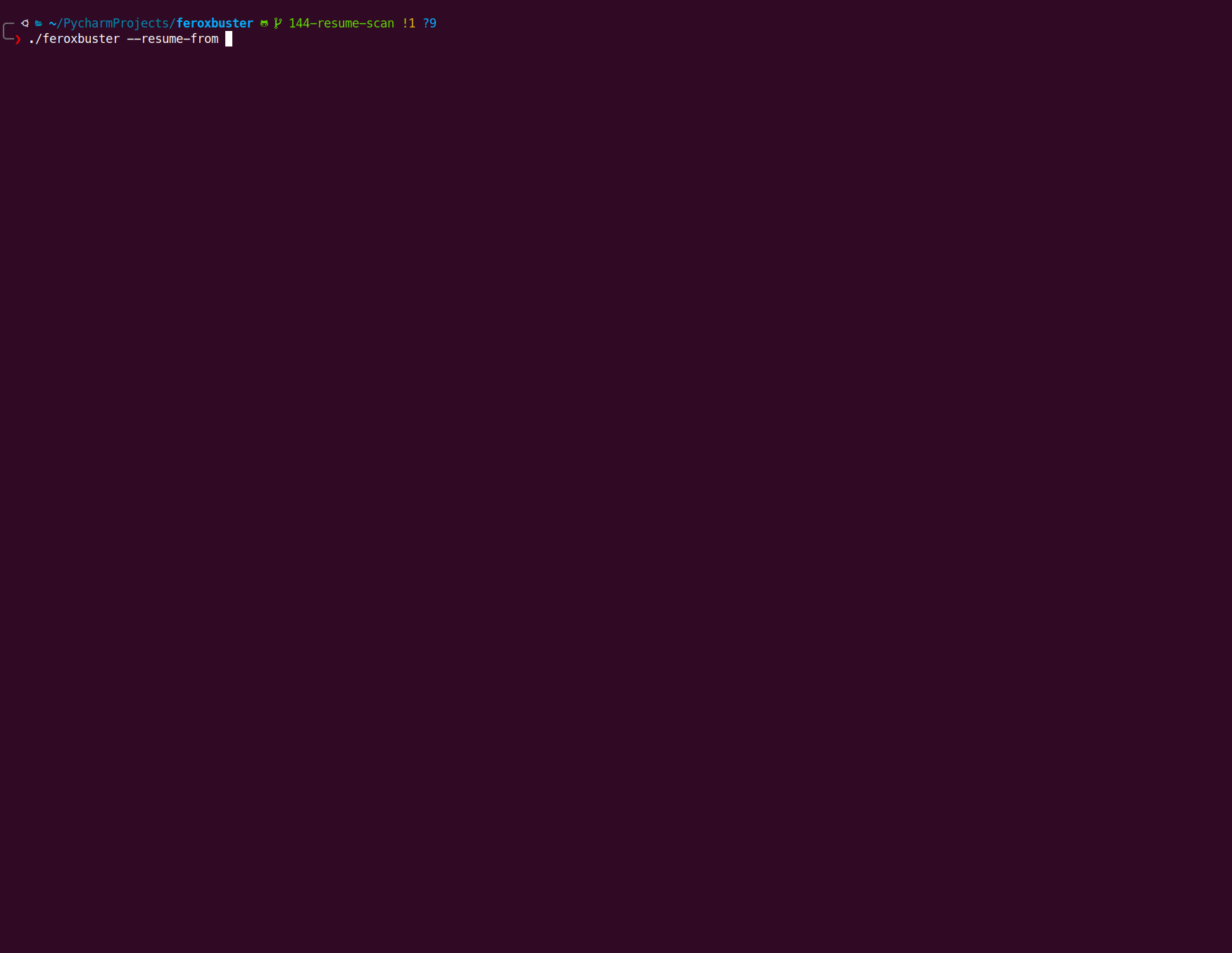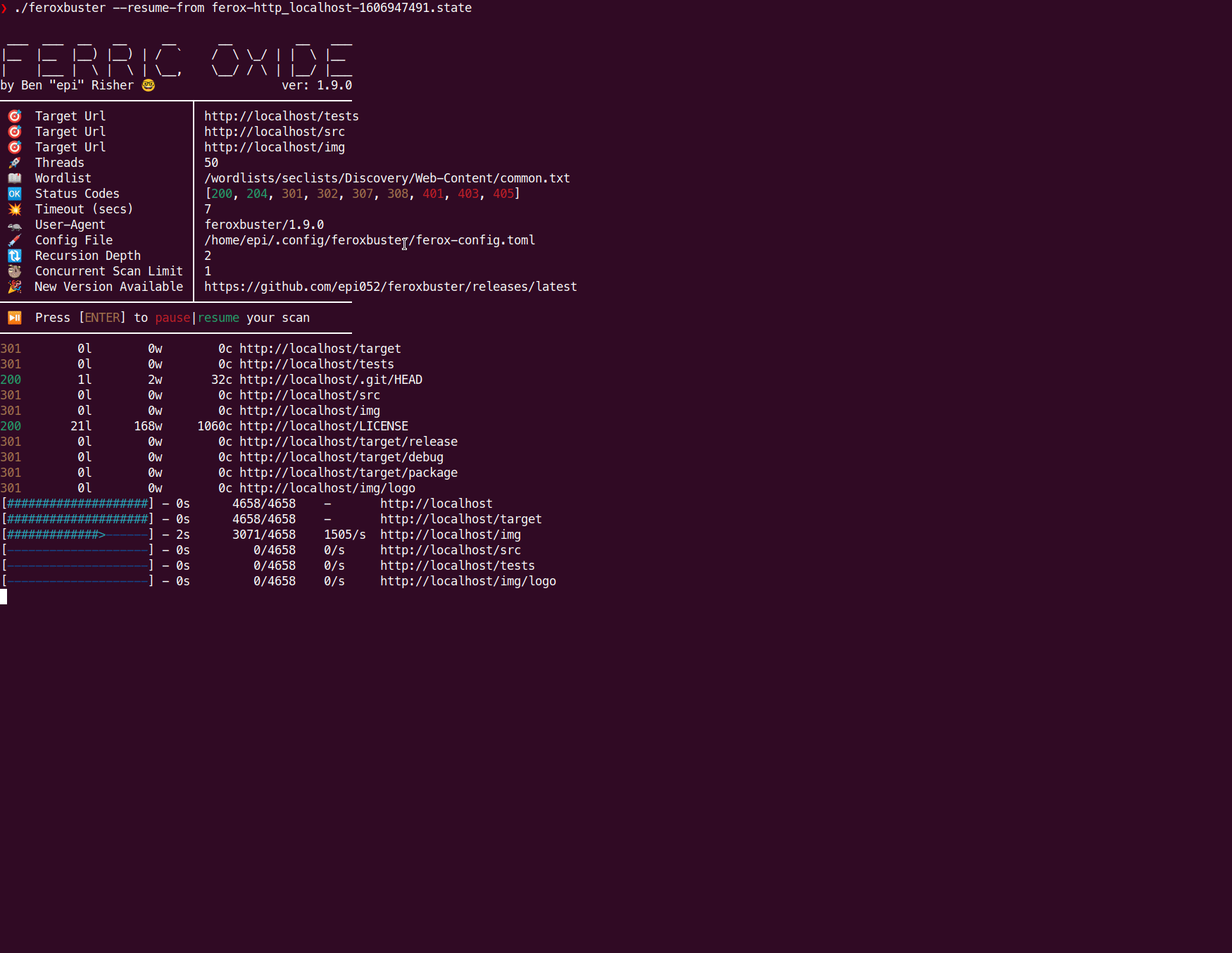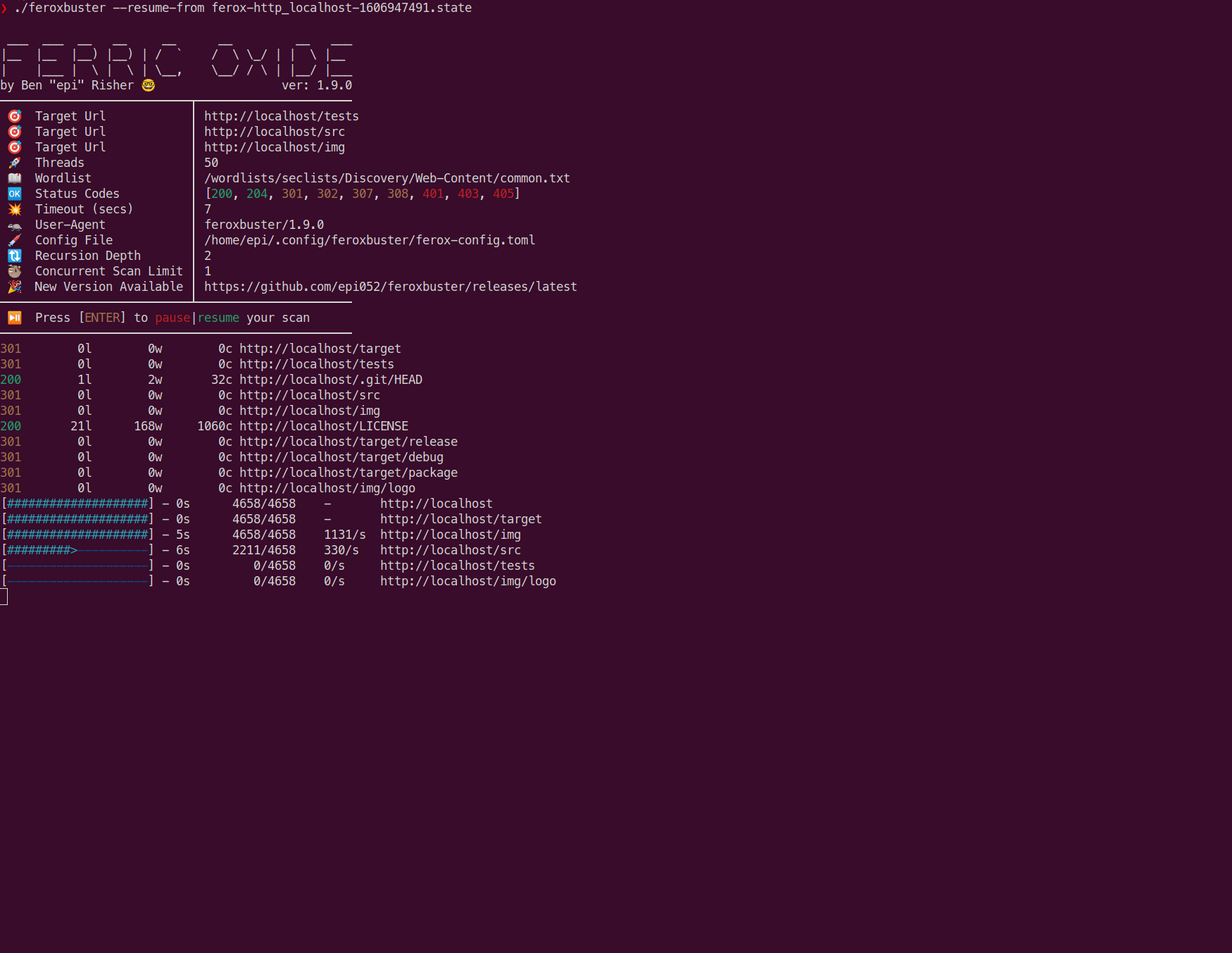
为了防止在Ctrl+C按下状态文件时创建状态文件,您只需将以下条目添加到中即可ferox-config.toml。
# ferox-config.tomlsave_state =false
限制扫描时间(v1.10.0)
1.10.0版增加了在扫描中设置最大运行时间或时间限制的功能。用法非常简单:数字后面直接跟一个代表秒,分钟,小时或天的单个字符。 feroxbuster将此组合称为time_spec。
可能的time_specs的示例:
- 30s – 30秒
- 20m – 20分钟
- 1h – 1小时
- 1d -1天(为什么?)
可以传递一个有效的time_spec—time-limit以便在给定时间过去后强制关闭。
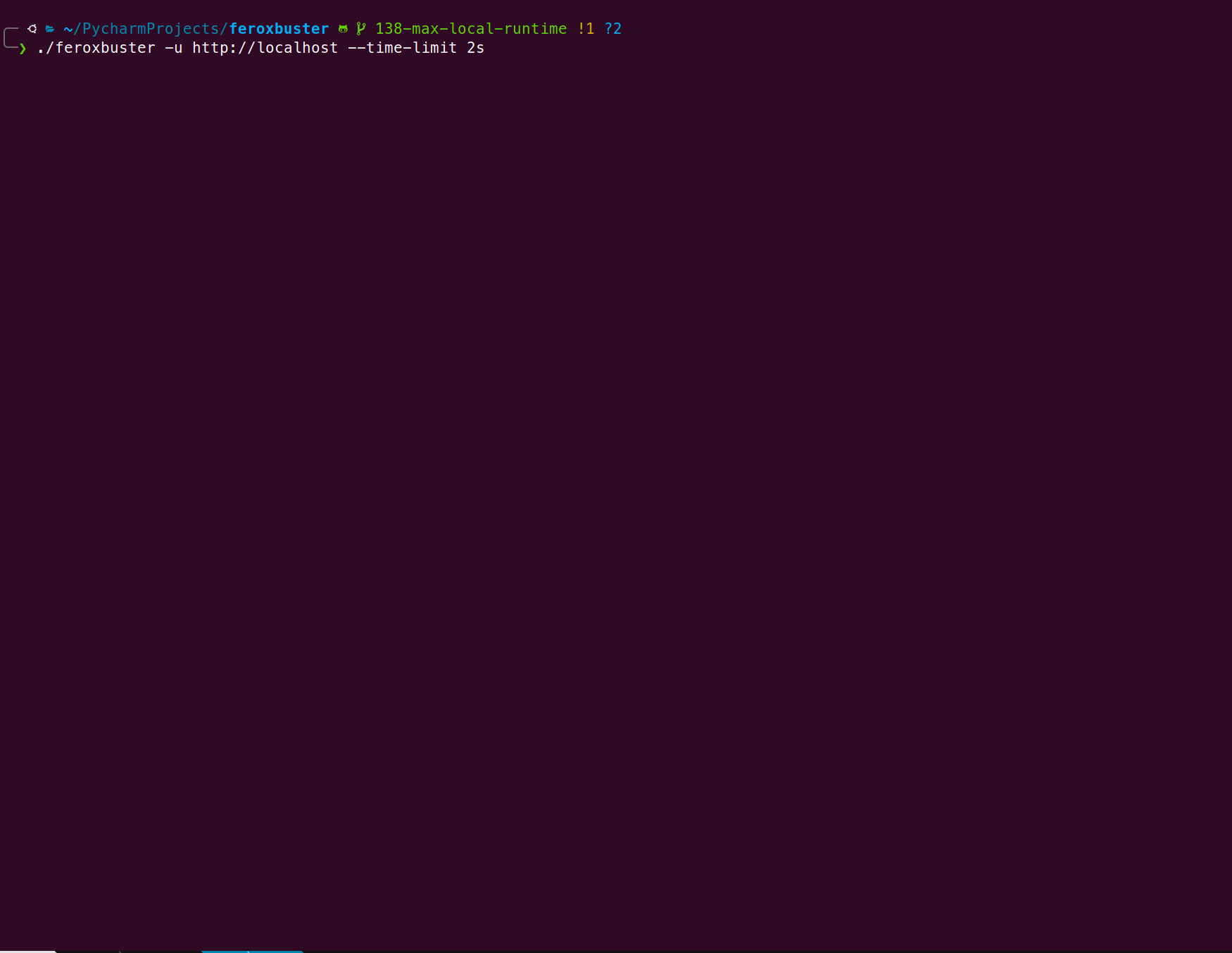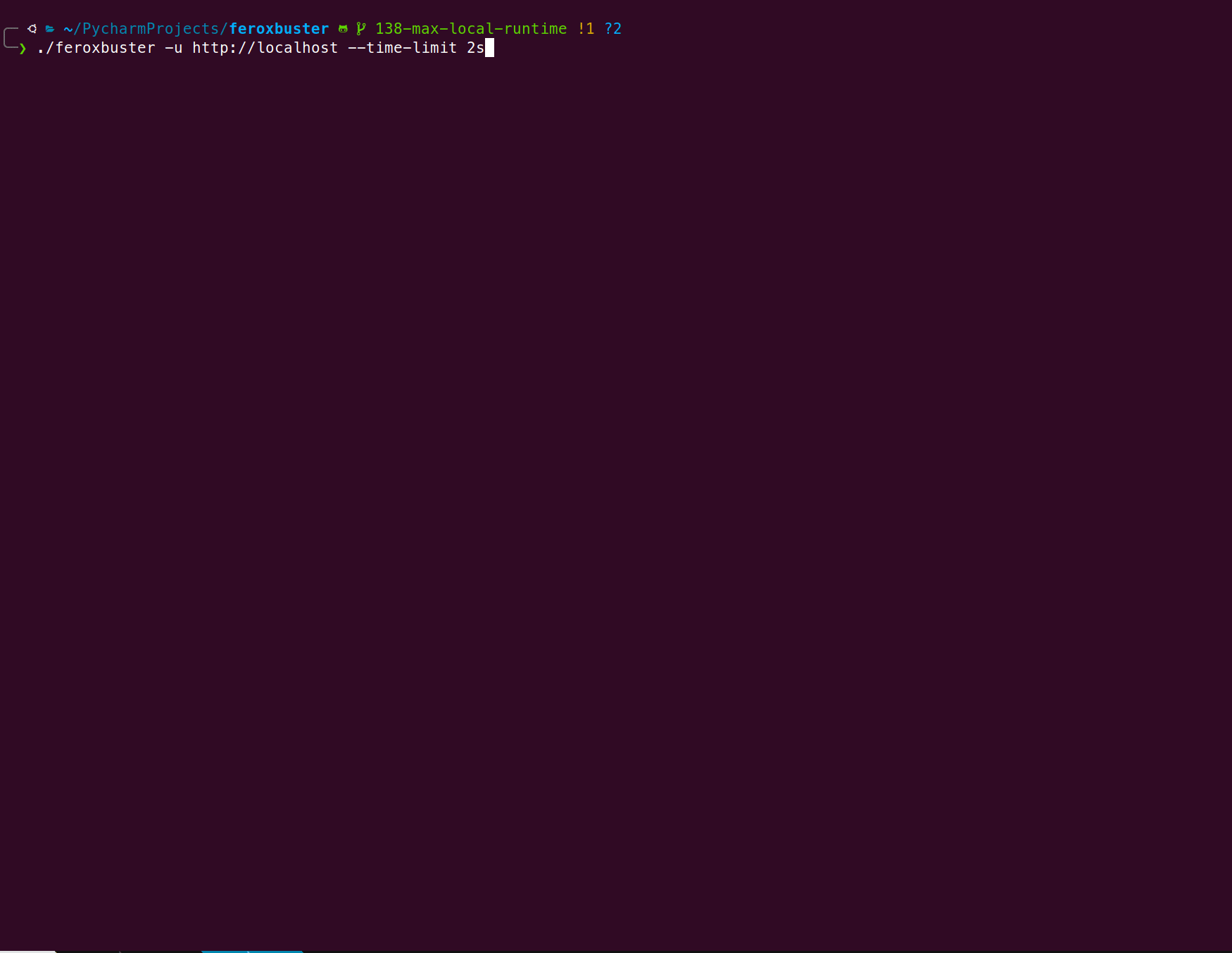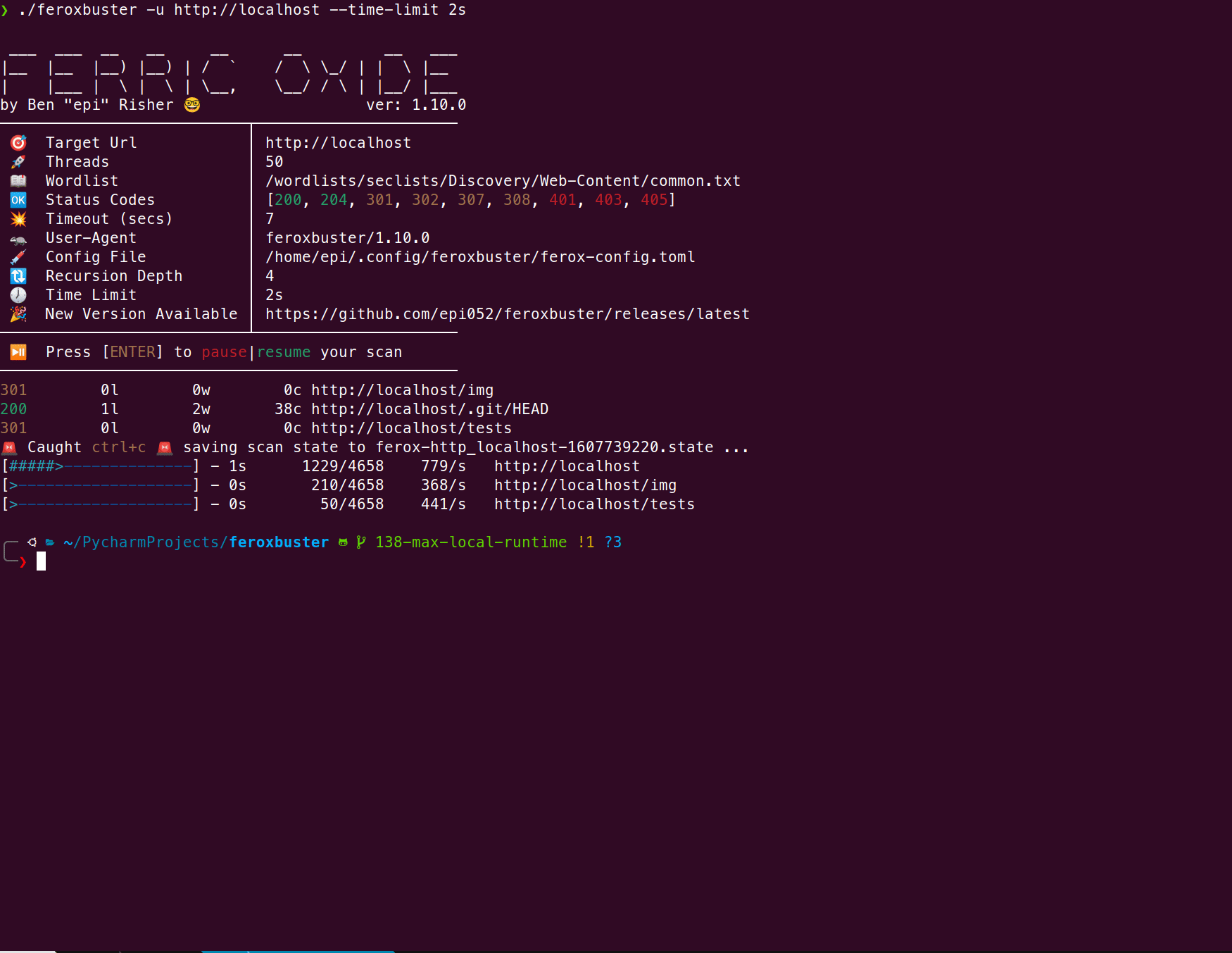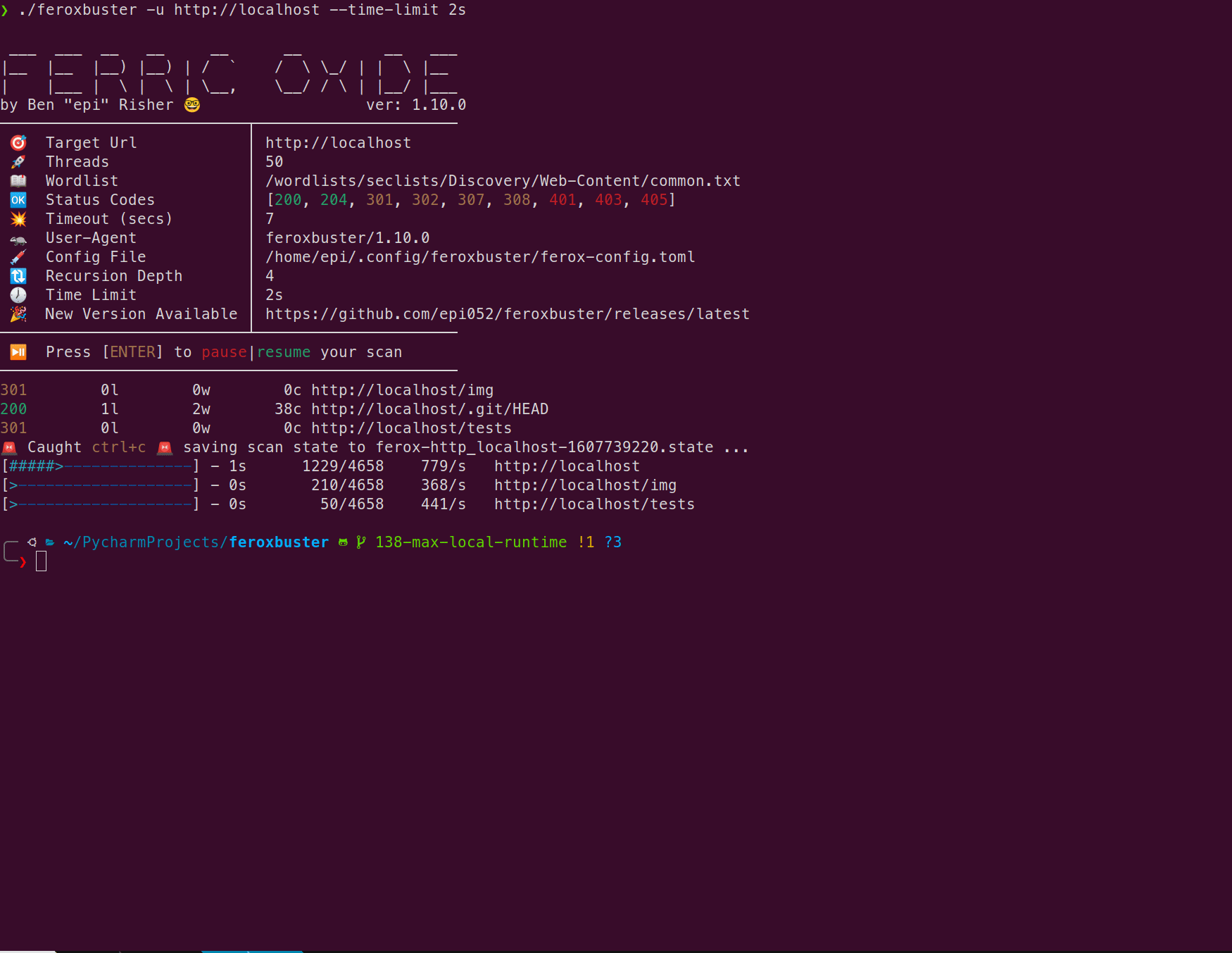
从robots.txt中提取链接(v1.10.2)
除了提取响应正文链接,使用 —extract-links使得对请求/robots.txt和检查所有Allow和Disallow条目。目录条目被添加到扫描队列,同时请求文件条目,然后在适当时进行报告。
按与给定页面的相似性过滤响应(模糊过滤器)(新增v1.11.0)
1.11.0版增加了指定示例页面以过滤与给定示例相似的页面的功能。
例如,考虑一个试图将新用户重定向到/register端点的站点。该/register页面具有CSRF令牌,该令牌会随着每个新请求而稍微更改页面的响应(有时会影响总长度)。这意味着简单的行/字/字符过滤器将无法过滤所有响应。为了滤除这些重定向,可以使用如下命令:
./feroxbuster -u https://somesite.xyz --filter-similar-to https://somesite.xyz/register
选择SSDeep的原因是,一旦内容长度达到一定大小,它就能很好地识别几乎重复的页面,同时保持性能。测试了其他算法,但是却导致了巨大的性能下降(每秒请求数个数量级变慢)。
注意
- SSDeep /—filter-similar-to不能很好地检测非常小的响应的相似性
- 缺乏准确性和非常小的响应被认为是公平的权衡,因为它不会对性能产生负面影响
- 使用大量—filter-similar-to值可能会对性能产生负面影响
交互式取消递归扫描(新增功能v1.12.0)
版本1.12.0扩展中所介绍的暂停/恢复功能V1.4.0增加一个交互式菜单,从中当前正在运行的递归扫描可以被取消,而不会影响整体的扫描。仍然可以通过按无限期地暂停扫描ENTER,但是,
通过扫描启动-u或传递的—stdin扫描无法取消,只有通过扫描—extract-links或递归找到的扫描才有资格。
以下是“扫描取消菜单”的示例。
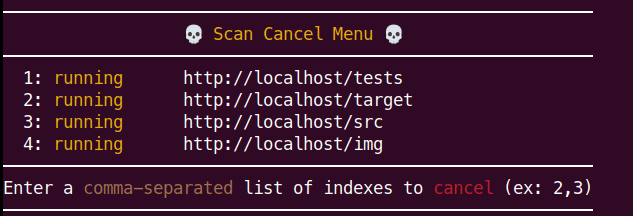
使用菜单非常简单:
- 按下ENTER即可查看菜单
- 通过输入扫描索引(1) 选择要取消的扫描
- 可以使用逗号分隔的列表(1,2,3…等)选择多个扫描
- 确认选择,之后所有取消的扫描将恢复
这是取消通过递归发现的两个正在进行的扫描的简短演示。
带类似工具的比较
有很多类似的工具可用于强制浏览/内容发现。Burp Suite Pro,Dirb,Dirbuster等。但是,在我看来,有两个设定标准:gobuster和 ffuf。两者都是成熟,功能丰富且令人难以置信的全方位工具。
那么,为什么您要在ffuf / gobuster上使用feroxbuster?在大多数情况下,您可能不会。特别是ffuf可以完成feroxbuster可以做的绝大多数事情,同时仍然为船载提供更多功能。在以下一些用例中,feroxbuster可能更合适:
- 您想要简单的工具使用经验
- 您希望能够将内容发现作为一些疯狂的12命令Unix管道盛会的一部分运行
- 您想浏览一个SOCKS代理
- 您希望默认情况下自动过滤通配符响应
- 您想要集成的链接提取器/robots.txt解析器来增加发现的端点
- 您需要递归以及上面提到的其他功能(ffuf也会递归)
- 您需要一个配置文件选项来覆盖扫描的内置默认值
| 功能 | feroxbuster | gobuster | uf |
|---|---|---|---|
| 快速 | ✔ | ✔ | ✔ |
| 允许递归 | ✔ | ✔ | |
| 可以指定查询参数 | ✔ | ✔ | |
| SOCKS代理支持 | ✔ | ||
| 多目标扫描(通过stdin或多-u) | ✔ | ✔ | |
| 默认值覆盖的配置文件 | ✔ | ✔ | |
| 可以通过STDIN接受URL作为管道的一部分 | ✔ | ✔ | |
| 可以通过STDIN接受单词表 | ✔ | ✔ | |
| 根据响应大小,字数和行数进行过滤 | ✔ | ✔ | |
| 自动过滤通配符响应 | ✔ | ✔ | |
| 执行其他扫描(vhost,dns等) | ✔ | ✔ | |
| 时间延迟/速率限制 | ✔ | ✔ | |
| 从响应主体中提取链接以增加扫描范围(v1.1.0) | ✔ | ||
| 限制并发递归扫描的数量(v1.2.0) | ✔ | ||
| 按状态码(v1.3.0)过滤响应 | ✔ | ✔ | ✔ |
| 交互式暂停和恢复活动扫描(v1.4.0) | ✔ | ||
| 将仅匹配的请求重播到代理(v1.5.0) | ✔ | ✔ | |
| 按行和字数过滤掉响应(v1.6.0) | ✔ | ✔ | |
| json输出(ffuf也支持其他格式)(v1.7.0) | ✔ | ✔ | |
| 用正则表达式(v1.8.0)过滤掉响应 | ✔ | ✔ | |
| 将扫描的状态保存到磁盘(可以在中断的地方进行提取)(v1.9.0) | ✔ | ||
| 最长运行时间限制(v1.10.0) | ✔ | ✔ | |
| 使用robots.txt增加扫描范围(v1.10.2) | ✔ | ||
| 使用示例页面的响应来模糊过滤相似的页面(v1.11.0) | ✔ | ||
| 交互式取消递归扫描(v1.12.0) | ✔ | ||
| 大量其他选择 | ✔ |
值得注意的是,还有另一个生锈的内容发现工具rustbuster。当我命名我的工具时,?)。我没有使用它的经验,但是它似乎能够使用HTTP正文执行POST请求,具有SOCKS支持,并且具有8.3短名称扫描程序(除了vhost dns,目录等)。简而言之,它看起来确实很有趣,并且可能正是您在寻找的东西,因为它具有某些类似工具中没有的功能。
? 常见问题/问题(FAQ)
没有可用的文件描述符
为什么会出现很多No file descriptors available (os error 24)错误?
此错误有一些潜在原因。最简单的是,您的操作系统将打开文件限制设置得过低。通过个人测试,我发现这4096是一个合理的打开文件限制(这将根据您的确切设置而有所不同)。
有很多解决此特定问题的选项,下面显示了其中的少数几个。
增加打开的文件数
我们将从增加操作系统允许的打开文件数开始。在我的Kali安装中,默认值为,1024我知道某些MacOS安装会使用256 ?。
编辑 /etc/security/limits.conf
上限的一种选择是进行编辑/etc/security/limits.conf,使其包含下面的两行。
- 代表所有用户
- hard并soft指出操作系统的硬性限制和软性限制
- nofile 是“打开文件数”选项。
/etc/security/limits.conf-------------------------...* soft nofile 4096* hard nofile 8192...
ulimit直接使用
较快的选项(不是持久性的)是简单地使用ulimit命令来更改设置。
ulimit -n 4096
其他调整(可能不需要)
如果您仍然发现通过上述更改达到了文件限制,则可以进行一些其他调整。
这部分是从stackoverflow答案中偷偷偷走的。该帖子中包含更多信息,如果您最终需要使用本节,则建议阅读。
✨特别感谢HTB用户@sparkla在确定这些其他调整方面的帮助✨
增加临时端口范围,并减小tcp_fin_timeout。
外围端口范围定义了主机可以从特定IP地址创建的最大出站套接字数。fin_timeout定义这些套接字将保持TIME_WAIT状态的最短时间(使用一次后将无法使用)。通常的系统默认值为
- net.ipv4.ip_local_port_range = 32768 61000
- net.ipv4.tcp_fin_timeout = 60
这基本上意味着您的系统无法始终保证(61000 - 32768) / 60 = 470每秒提供更多的套接字。
sudo sysctl net.ipv4.ip_local_port_range="15000 61000"sudo sysctl net.ipv4.tcp_fin_timeout=30
处于TIME_WAIT状态时允许套接字重用
这可以使套接字在time_wait状态下快速循环并重新使用它们。请务必阅读文森特·伯纳特(Vincent Bernat)的“应对TCP TIME-WAIT”一文,以了解其含义。
sudo sysctl net.ipv4.tcp_tw_reuse=1
进度条一次输出一行
feroxbuster为了正确进行进度条输出,需要的终端宽度至少要等于正在输出的内容。如果宽度太小,可能会看到如下所示的输出。
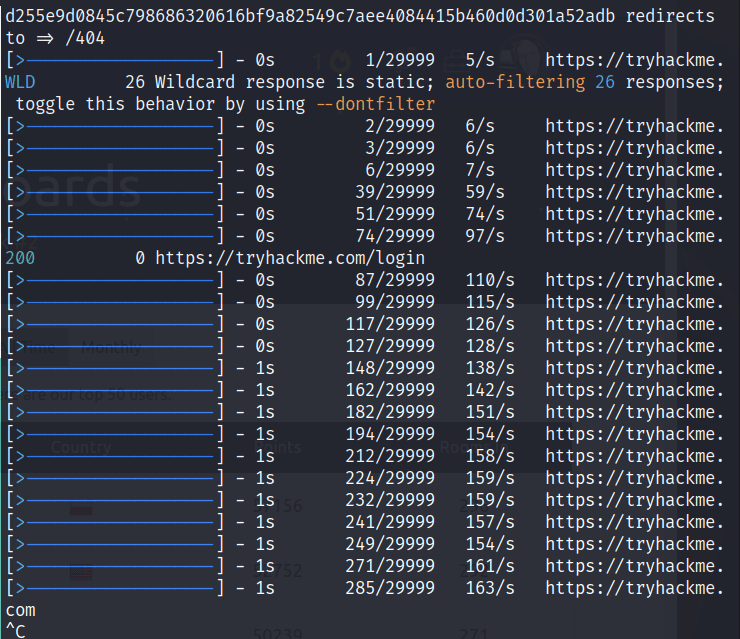
如果可以的话,只需将终端加宽并重新运行即可。如果您无法扩大终端的范围,请考虑使用-q 抑制进度条。
URL旁边的每个数字是什么意思?
请参考本节,其中讨论了每个数字的含义以及如何使用它来过滤响应。
消息完成前连接已关闭
有问题的错误可以归结为“网络东西”。feroxbuster 使用reqwest,后者使用hyper向服务器发出请求。超级项目的此问题报告解释了正在发生的事情(下面引用以节省您的单击时间)。这不是一个错误,而是一个特定于目标的调整问题。降低该-t值时,不会发生错误(或发生的频率要低得多)。
这不是错误。只需降低扫描速度即可。-t选择默认值50作为合理的默认值,该值仍然非常快。但是,当客户端和/或服务器变得过饱和时,可能会发生与网络相关的错误。“高级线程和连接限制”部分详细介绍了如何完成每个目标的调整。
这仅仅是由于网络的活泼性。
hyper有一个空闲连接的连接池,它选择了一个发送请求。大多数情况下,hyper会接收服务器的FIN并从其池中删除死连接。但是有时,将从池中选择一个连接,并在服务器决定关闭该连接的同时将其写入。由于hyper已经写了一些请求,因此它不能真正在新连接上自动重试,因为服务器可能已经采取了行动。
SSL错误例程:tls_process_server_certificate:证书验证失败
如果您看到类似的错误
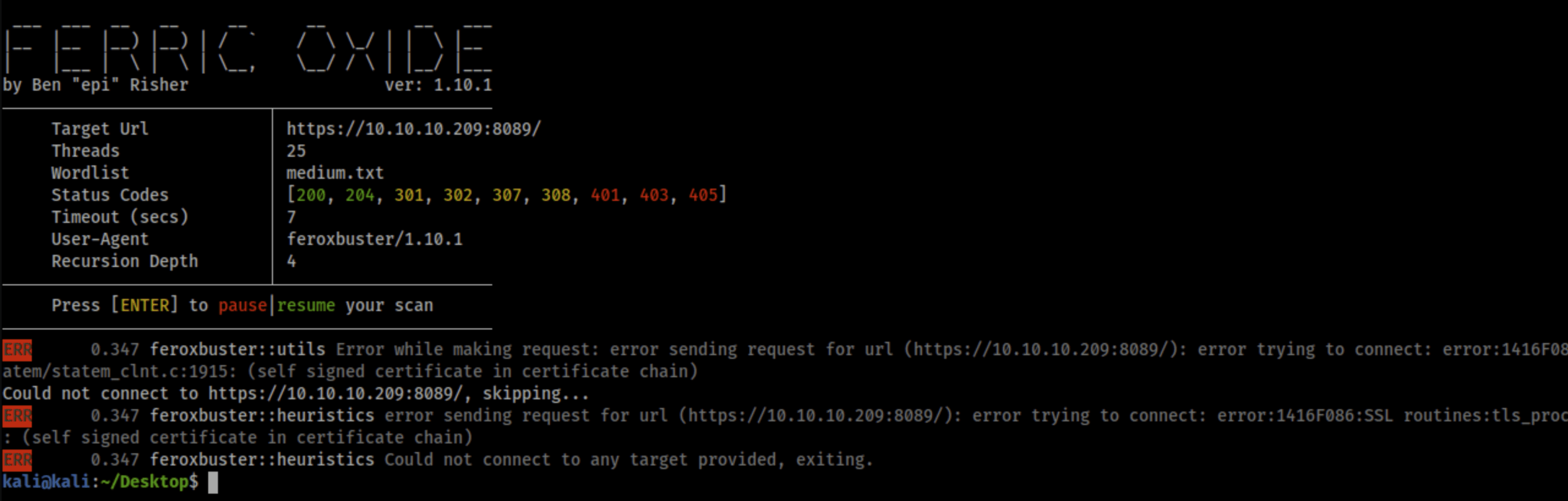
error trying to connect: error:1416F086:SSL routines:tls_process_server_certificate:certificate verify failed:ssl/statem/statem_clnt.c:1913: (self signed certificate)
您只需要将-k|—insecure标志添加到命令中即可。
feroxbuster默认情况下,拒绝自签名证书和其他“不安全”证书/站点配置。您可以通过告诉feroxbuster忽略不安全的服务器证书来选择扫描这些服务。

若有收获,就点个赞吧
0 人点赞

{kind=link}