将简化进行到底的W2V
从上一篇文章大家可以看出来计算量如此之大的模型也正是早期神经网络不受人待见的问题,计算量大,成本高,训练时间长,有这个时间统计学习的研究者们又鼓捣出新模型了。所以说生产力决定生产关系,成本决定科研走向,大家也是要考虑到模型的实用性的嘛。
于是Mikolov的W2V的首篇论文先是提出两种模型架构,CBOW 和Skip-gram,特点是比起之前的NNLM是真正使用了上下文的信息,之前是只考虑前文,毕竟大家都是按照序列生成的时序来的,这下一转换思路,直接就类似于做起了完形填空,可以利用的信息就更多的。其次是简化了投影层,以及不对隐层做非线性映射(这点是W2V向量能够线性推理的关键),这些简化的计算量不是很多,但是模型结构确实简单了不少,毕竟输入层到隐层最复杂的CBOW也只是对对应权重矩阵行做了加权平均这部分也就N x D,对于隐层到输出层的计算使用了分层softmax计算,这种计算的复杂度从原来的O(v)变为了现在的O(log(V))这下子看起来计算量确实减少很多,其实这时候模型加上后年提出的二次采样(按照概率丢弃高频词),性能还是超出后来的负采样的,(Mikolov原文)。
简单的来说因为成本问题,简单模型在大量数据上训练的结果是要超出复杂模型在少量数据上训练的结果的,所以要将简化进行到底,这里有两个核心算法得讲一下,分层softmax和负采样。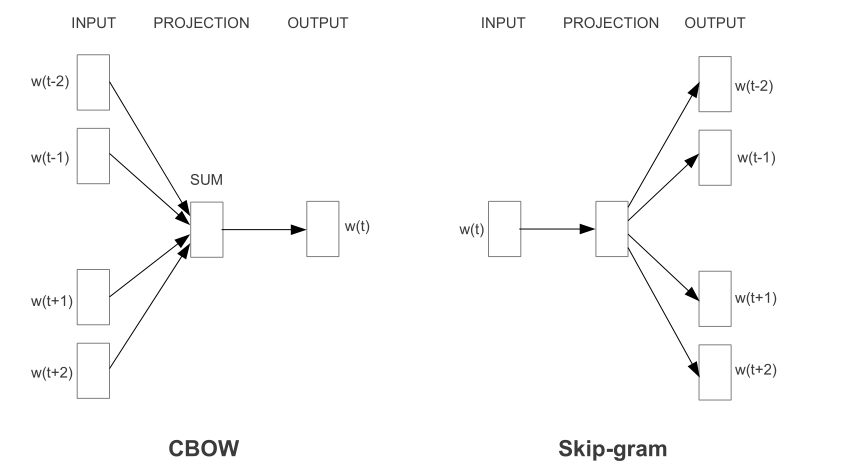
这里得说一下这个模型本身就是为了学习词的分布式表示形式的,它的预测任务其实不是它的目标任务其实就是个假任务(fake task ),这点对Skip-gram尤其是,预测是为了能够找到一个真实分布来间接去拟合,因为Skip任务本身就是一个很难的任务,一个词的语义真的包含了所有语境中上下文词的信息吗?同时要知道一件事,Skip-gram模型的输出矩阵对隐藏层是共享参数的,也就是说预测的结果实际上是一个词,只不过是通过和真实分布的交叉熵进行多次更新。这真是足够大胆的想法。
现在来讲一讲这个分层softmax的核心思想,我们通过词频信息来构建一个哈夫曼二叉树,词频高的放在靠近根节点的位置,这样相对的生成概率高,然后陆续构建这个树。现在树已经构建好。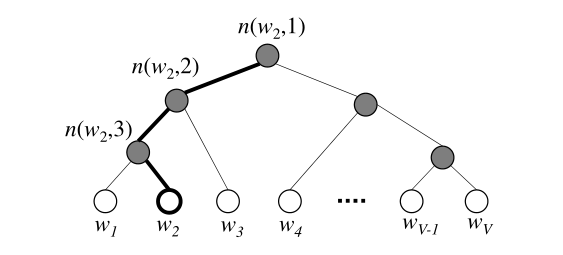
简单的softmax的结构基本如图,叶子节点是词表中的词使用二进制哈夫曼树来进行表示,这里假设构建的哈夫曼树是一个完美二叉树,当类别数量巨大是线性分类器做softmax的成本是的级别,但是使用哈夫曼树的形式可以降到的级别,其实可以看作是理想的二分查找。也能够极大的降低训练成本。原本的隐层到输出层的权重矩阵被转化为二叉树的内部节点,经过每个节点是往左还是往右是通过一个逻辑回归来判断的,也就是说通过一个理想状态下的logV次sigmoid运算就能确定一个词的生成概率,这个二叉树的内部节点会在更新中调整自己的输出向量,使得路径选择的结果也就是生成的词可以尽量接近于真实情况: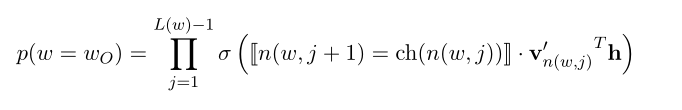
这里可以看出来在到达叶节点前的路径(L(w)是路径长度),要经过L(W)-1的内部节点(得去掉根节点,毕竟是出发端)。向左就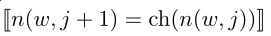 =1,否则就是-1,通过这中方式可以在反向传播中正确的这些输出向量使得后续训练生成概率接近真实情况,同时因为多个堆叠的逻辑回归,训练时激活的也只有层数等值的数量,这样这种级别的计算量就小了很多,毕竟逻辑回归的梯度计算是真的简便。
=1,否则就是-1,通过这中方式可以在反向传播中正确的这些输出向量使得后续训练生成概率接近真实情况,同时因为多个堆叠的逻辑回归,训练时激活的也只有层数等值的数量,这样这种级别的计算量就小了很多,毕竟逻辑回归的梯度计算是真的简便。
现在来讲一讲剩下来的二次采样和负采样。
大家一听这名字就感觉有关联,其实关系不大,负采样是一种思路,通过对原本的样本引入噪声,将原本的多分类模型划成正确分类和随机组合的负分类两项,这样就将原来至少要更新logV级别的向量变成是只要对正负分类的样本向量更新,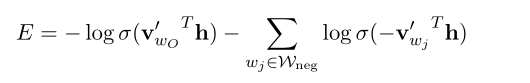
原本的目标函数变成了两部分,使得模型预测真实分布的概率尽可能高,预测随机的错误分布的概率尽可能低。这种简单形式的负采样方式按照作者所说的“简单的方法产生高质量的结果”,所以说什么是好模型,这就是好模型,胆大包天,秒到毫巅。
那么托马斯老师另外还做了什么?对,是二次采样,这点就是我前面提到的: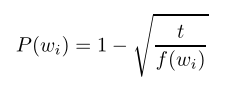
对就是对训练集中的词按照词频计算上面的这类概率来随机丢弃,这里类似轮盘赌,词频高的当然被丢弃的概率就会高,t是一个控制阈值,是一个超参数。
所以说这里也可以说是一种加权采样,尽量使得词的更新平均。

若有收获,就点个赞吧
0 人点赞
