卷积神经网络的结构:
常用的卷积技术通常是:“卷积”,“批量标准化”,“激活”,“drop out”,“池化”
这些卷积层一般是用来提取特征的,将“低层”的特性转化成“高层”的抽象的特性,然后卷积层上的全连接层一般是用来进行特性相关组合的判断。
卷积是数学上的一种运算,
其在连续上的定义就是: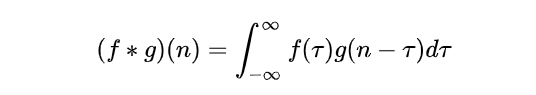
实质是将二元函数 变成一元函数
变成一元函数
在cnn上来说更像是用一个滤波器将张量转化成一个标量(卷积核),使用不同的滤波器会得到不同的处理结果。
也就是说卷积操作过程中对图片区域的像素进行加权处理(滤波器),也就是尽量在空间上进行全局考虑,而卷的步骤更像是限制图像处理的空间范围,是在指明是对哪个像素周边进行处理,对于边角区域
实际上在cnn中卷积运算更像是窗口的滑动,在信号上看起来更是一个低频滤波器,能够滤除高频噪声,使得图像更平滑,同时能够映射更多的感受野,反映的是不同滤波器处理后图像的特性,处理后的图像会更模糊同时边缘更清晰。
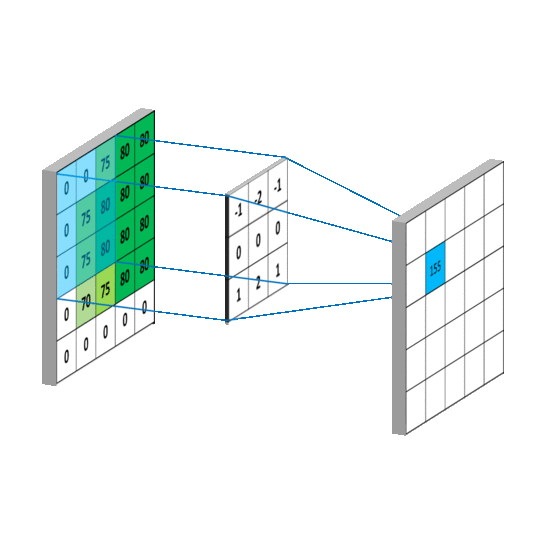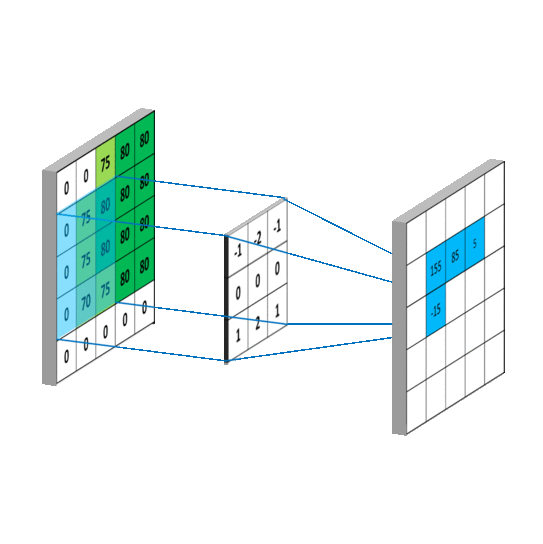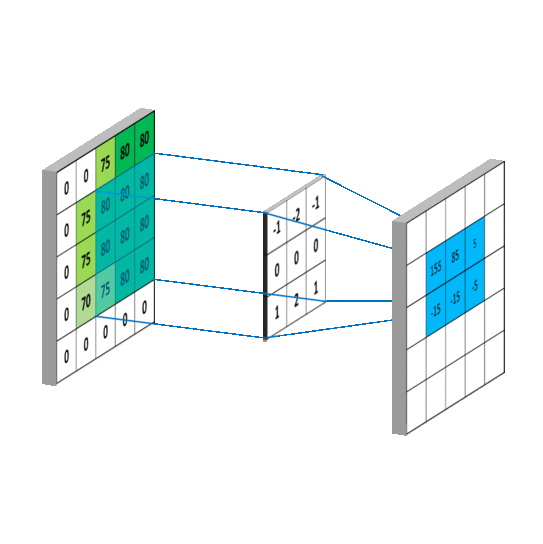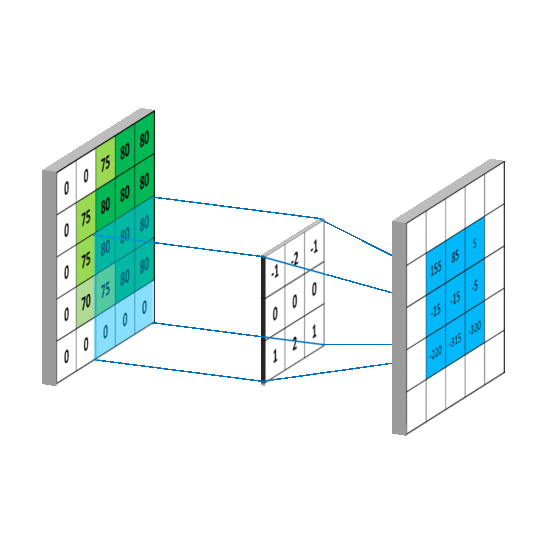
通常在处理的时候也会用上填充技术(padding),用来处理图片区域边界,因为边界效应边界上的区域不能作为中心生成对应图块,所以可以对其进行填充用来生成维度相同的特征图·
在卷积层有对应参数:
1.图片中提取出来的图块尺寸。
- 输出特征图的深度(卷积使用的滤波器数量,一般是32或者64)
- 步幅(默认是1,步幅为2意味着2倍下采样,实际上基本很少采用这一办法)
- 填充(一般来说图片中心一般比较重要,边界上效益比较少)
卷积在一些时间上的处理也是较为优秀的,通过将时间视作空间进行处理,能够取得更高的效率。
下面是我从信号的角度来看卷积神经网络的;
一、卷积的意义:
卷积是数学上的一种运算,
其在连续上的定义就是:
CNN中的卷积原理:
图1-1
在3D输入的特征图上滑动(slide)这些33,55的窗口,在每一个可能的位置上停止并提取周围特征的3D图块,(形状是(window_height,window_width,input_depth))然后每个3D图块与学到的同一个权重矩阵[叫做卷积核]做张量积,转化为形状为(out_shape)的1D向量。然后对所有的这些向量进行空间重组,使其转换为形状为height,width,output_depth的3d特征输出图,如上图1-1。输出特征图的每个空间位置都对应于特征图中的相同的位置。
在CNN上来说更像是用一个滤波器将张量转化成一个标量(卷积核),使用不同的滤波器会得到不同的处理结果。卷积对是对图像像素的对应加权和运算,同时因为sliding window是一个filter在图像空间上的移动,其对应的权重矩阵在CNN之中权值共享,通过对权重的反向梯度计算,来自动选择适合的滤波器,而学习到的权重矩阵往往能够获得对目标函数较为有利的过滤器,更多的滤波器意味着不同的特征选取。
更小的卷积核会引入更多的非线性结构和参数的减少:
可变形卷积:两个顺序叠加的卷积结构,一个是正常的自更新卷积核,另一个是控制卷积核偏移量的更新卷积。
实际上在CNN中卷积运算更像是窗口的滑动,在信号上看起来更是一个滤波器,对于常用的低通滤波能够滤除高频噪声,使得图像更平滑,同时能够映射更多的感受野,反映的是不同滤波器处理后图像的特性,其他的滤波器有的是锐化图像,还有些能过滤图像的边缘信息,一般人类关注的是图像中低频信息,同时低频信号占据着图像中的绝大多数能量,到混杂噪声的高频信息,所以实际中的边缘信息提取过程中,通常会使用低通滤波进行平滑降噪之后,使用高通滤波器进行高频滤波,获得图像的边缘信息,如下图2-1和图2-2,在使用高斯平滑之后使用了拉普拉斯滤波器,将图像的边缘信息提取出来。
图2-1 灰度图 图2-2 边缘特征
卷积神经网络中较为底层的卷积获得的是图像的局部的细节的特征,比如有弧线,三角形,高层的卷积层是用来对低层的特征图进行细节上的抽象组合,实现对目标的拟合过程。
二、卷积神经网络中的频域意义:
从神经网络的计算过程来说,低频信息往往比起高频信息更容易学习,因为往往在CNN中只要几个简单的卷积层就能获取图片的低频信息,同时在训练过程中低频分量的学习优先度比较高,但是根据后来的研究成果高频结果和图像的语义之间有着一定的相关性,往往模型的预测结果是几乎完全取决于图片的高频分量,而与图片原图几乎完全相同的低频分量对模型的预测结果会得到不相符的结果。
而根据2019年的一项关于图像识别的研究中的结果:研究了图像数据的频谱与卷积神经网络(CNN)泛化行为之间的关系。研究人员注意到CNN捕捉图像高频成分的能力。这些高频成分对人类来说是最容易察觉的。根据观察结果研究人员提出了与CNN泛化行为相关的多种假设,包括对对抗性例子的潜在解释,研究人员认为CNN的非直观泛化行为是人类和模型之间感知差异的直接结果:CNN可以以比人类更高的粒度查看数据。
从上述频谱能量分布和特征图中频域信息可见,CNN会利用高频信息来减少损失,因为高频信息中往往包含人类无法识别的关键信息,同时另一篇论文中指出CNN对高频信息同样有着偏好,往往倾向于对图片的纹理特征来识别图片的语义,而对于特定问题来说的边缘轮廓信息反而其次,研究人员在猫的轮廓之中插入大象的纹理,汽车的轮廓上使用时钟纹理,这些方式和使用最大化某个类别激活值所得出的高层特征图一样,对模型都有着愚弄的效果,这个也是说明了下表中高频信息会导致泛化性下降,当神经网络遭受对抗性扰动的时候自然训练得出的模型中高频域反而更容易被影响,但是使用了对抗性训练的神经网络在高频分量上有着更好的抗扰动性,可以选择牺牲精确度来提高模型的泛化性能。
神经网络的训练:
神经网络的训练过程中较小的批量似乎在提高培训和测试准确性方面表现出色,而较大的批量似乎在缩小泛化差距方面表现突出,同时进行梯度计算优化的优化器之中SGD对高频分量有明显捕获趋势。而启发式算法之中mix-up往往会捕获到图片之中的高频信息。同时CNN训练过程会先采用低频语义信息进行降低loss,当继续训练无法降低loss时候会额外考虑高频成分进一步降低loss,而由于label被shuffle掉导致无法利用低频语义信息,则出现刚开始acc为0的现象,但是因为后期利用了高频成分,故最终还是能够完全拟合数据。
需要特别强调的是:高频成分可以分成两部分:和数据分布相关的有用高频成分A、和数据无关的噪声有害高频成分B。在natural label数据训练过程中,CNN可能会利用AB两种高频成分进行过拟合,而且由于利用的AB比例无法确定,故而就会出现CNN模型存在不同的泛化能力,如果噪声成分引入的多,那么对应的泛化能力就下降。
通过上述现象,我们很容易解释早停止手段为何可以防止过拟合,因为越到训练后期其可利用的和数据相关的有用高频成分就越少,为了降低loss,就只能进一步挖掘样本级别的特有的噪声高斯信息,。
总结:
关于信号方面的知识还是有些欠缺,不过深度学习的可解释性还是一个大问题,有待我们去探索。

若有收获,就点个赞吧
0 人点赞
