文本生成的一些文献的研究:
中国诗歌是中国传统文化的瑰宝。千百年来,诗歌一直被中国人视为人类智慧和博学的结晶,从精神和文化的角度深刻影响着中国历史。一般来说,中国古典诗歌是形、声、意三个方面的完美结合。首先,它必须严格遵循一种特定的形式,即规定诗中的行数(即句子)和每行中的字符数。其次,它必须严格遵循一个特定的声音模式,该模式规定了诗歌中每个位置的每个字符的声音要求。最后,它必须是有意义的,即每一行的语法和语义形式良好,主题连贯性和完整性贯穿始终。这三点构成了人类诗人创作中国古典诗歌的普遍原则。中国古典诗歌可分为诗和词两大类。根据CCPC1.0的统计数据,中国古典诗歌语料库共收录诗歌834902首(我们认为这几乎是中国古典诗歌的全集)。CCPC1.0中92.87%的诗歌属于诗的范畴,7.13%的诗歌属于词的范畴。诗和词在形式上又可分为许多不同的类型。下面简要介绍一下相关的背景知识。
诗歌是有着严格的格式规范的,包括声韵,起承转合
以五言绝句为例:律诗对后半阙有着严格的对仗要求
词赋是格式更加多样的诗歌形式,文本中的字词也是遵循着齐普夫定律,古体诗中大量的词汇是很少被使用到的,常用的词汇反而不是很多。
另外词的词牌也有只有很少的实例,是难以作为样本进行研究的,不能纳入数据集
古体诗生成的最大挑战就是使生成的诗歌的格式能够合乎诗人创作的一般要求,
另外容易理解的一点是诗歌的长度和生成难度是成正比的,所以比较常见的古诗生成器都是五言诗或者七言诗,对于词这一复杂形式的诗歌的研究还是在初始阶段,
比较著名的诗歌生成工作就有清华大学的九歌
之前做的比较好的工作是基于条件变分自编码器和注意力seq2seq模型架构的,清华的九歌是基于GPT2,诗歌的历史信息是能够加强诗歌本身的主题连贯和完整性。
转换器架构的提出很大程度上推动了自然语言处理研究的进步,
2019基于GPT的古诗生成模型首先在2.35亿句的中文新闻语料上进行了训练,将CCPC中词频少于3的字符统一用低频词标志[unk]处理,然后在25万句古诗进行了微调,通过对诗词的形式结构进行定义,【形式,标识符,主题,标志符,主体】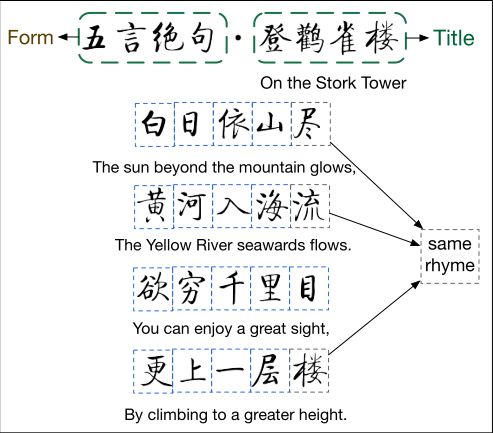
古文语料的获取还是比较困难的一件事,GPT2加上格式约束也不能解决词上面的生成的复杂性,他们是使用汉字作为基本的语言模型的,生成的单个句子在语义的音韵上的表现都是比较好的,根据论文所说的GPT2这种体量庞大的预训练模型也没法解决生成诗文的流畅性和连贯性
对生成的每个文字的损失评估使用的是交叉熵
通过加大格式字符的权重,能够提高对于格式控制的能力
架构就是GPT2使用4个1080TI的工作站进行了40万次训练,
目前诗词生成模型弊病就是无法生成比较长的合乎创作规律的诗词
这个清华的论文工作就是在廖等人的工作上做了格式上的规范的加权调整,
第二篇文献 是把前人的两种方式进行了结合,也就是在诗歌上INSERT and UPDATE
来自IJCNN(神经网络国际联合会议)2020
使用下一步生成的句子的内容来扩展精炼文本的空间,能得到更多语义上有相关性的词,选择更多,理论上效果会好上一些
使用前人句子生成的诗歌内容上是难以保证诗歌语义的一致性,
使用注意力机制对编码器进行改进,在原先和HEMM理论近似的lstm的输入部分加入注意力状态
使用生成过程的时候是最好不要使用
GPT-2模型是模型巨兽,最小的模型存储起来也是需要500M,最大的模型甚至是要超过6.5g
轻量级的GPT2是12层transform结构,最大的模型是它的四倍
自回归机制,使用生成的状态作为下一步的输入,这一点是rnn有效性的来源
检索过程使用实时搜索引擎ElasticSearch
使用TextRank提取每一句的关键字(探索子主题)用的是Jaccard(雅卡尔距离)和句子长度来选择近似度比较好的段落,然后和原本生成的句子一起进行TFIDF(关键词)进行降序排列后合并(简单的说就是引用前人诗句中的某些部分来提高生成的诗文的质量)
生成任务中只能使用自回归方式,从前项单词来预测后续生成的单词。
这篇文献因为是先生成草稿,在草稿上进行精修,绕开生成模式下的限制,同时对句子语境的上下文进行检索,使得在润色的时候能够更大程度上保证连贯性,可以看到这是针对文本生成任务上通过自然语言理解模型来进行精修,理解上下文的关联,并在候选集上选取印象词来对生成的样稿进行润色;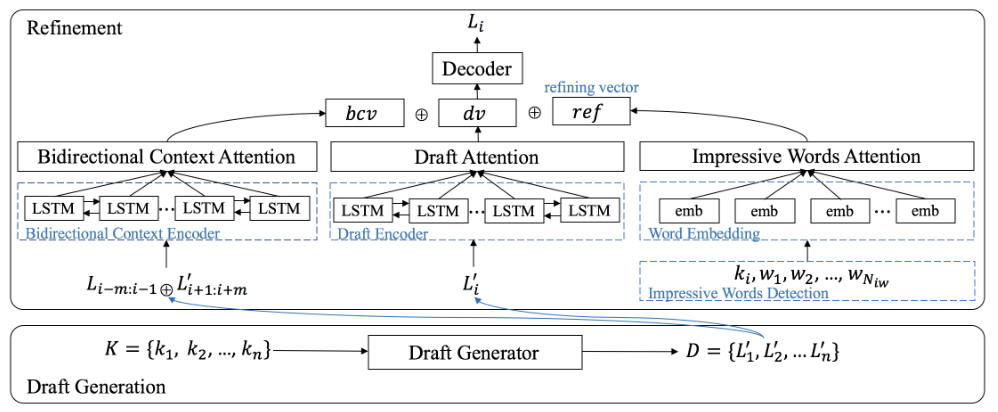
对候选词的词向量进行注意力加权
数据集的处理 采用TextRANK处理出诗歌中的关键词,作为预处理的步骤
这篇文献将研究延伸到格式自由的现代诗歌
使用神经记忆来提高诗歌的创造性
使用工作记忆,根据生成诗文的历史来提高诗歌的连贯性,使用了5w4k的高频词来做词汇表,词汇表之外的全部当做低频次处理,因为不具有代表性,学习上下文向量的时候,要考虑前面和后面两个句子,首尾句子应该是有设置的,候选的印象词集大小是2个,
这里提出了一种束搜索来进行参数搜索,这是一种贪心算法和穷举算法的折中,束为1就是贪心,束为参数集大小就是穷举
背景起源: 诗歌生成这一部分早期研究是基于语法规则、遗传算法或者统计机器翻译方法
近些年基于神经网络的诗歌生成也取得的巨大的发展
近期研究: 更强的格式约束、连贯性和连续性
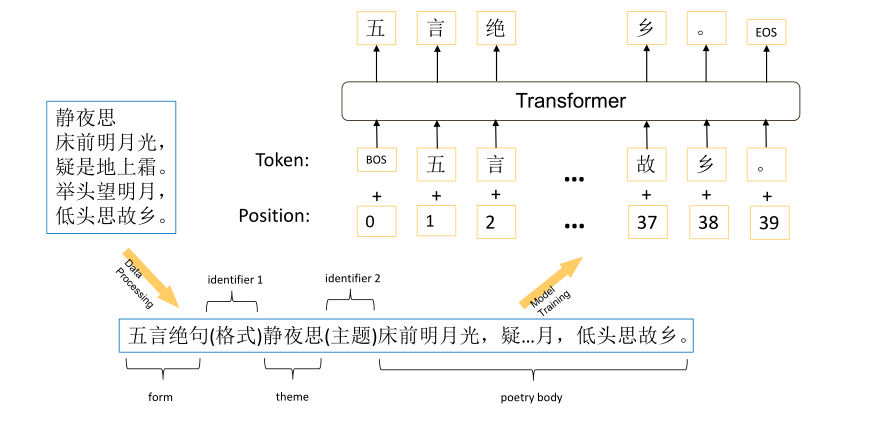
这就是比较基本的诗词生成模式,他的改进就是换成了GPT同时把格式也考虑进去了。
第三篇 探索中文古诗中的线索机制 出版在自然语言研讨会上 CONLL2018
提出用关键字之间的关联取代上下文信息指导诗歌生成(质疑?这个真的有效?是不是在特定数据集上比较好)
子主题指导生成带来了较强的约束,生成诗歌的创造性比较低
作者在这里提出质疑,上下文表示向量真的能够很好表示上下文语境关系?
所以这篇论文是在探索一种更好的表示语境信息的方式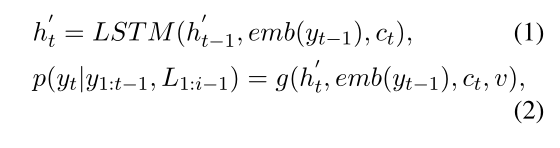
对生成下一个词的预测是通过当前句子之前的词和之前的句子的信息得来的
通过ht(解码器的隐藏状态)emb(yt-1)(上一个生成词的表示向量),ct是局部注意力向量,v是全局注意力向量,
<诗中的前几行,诗中的一行>
这是一种经典的指导序列
作者提到用来指导诗句生成的指导序列行数越多,能够利用更多的全局信息,但是训练对的数量就会减少,最后生成模型的泛化性能就会减弱
作者通过实验发现使用全局注意力会使得生成第四行诗的时候,70%的注意力都会集中在第三行,
另一种全局信息是通过一个向量来表示
缺点就是单个向量表示全文的信息的时候,包含了很多不加分辨的噪声 因此真正有价值的信息可能就被隐藏起来或者和噪声信息一起被使用,
要是出现前文句子中词汇之间的显著性不够明显的时候采用前文和当下句子的TFIDF(基于文档独有词)对注意力对齐矩阵进行加权计算
TFIDF SSal
SDU 显著线索同时由上一个显著线索和当前句子的显著词的相对隐藏状态决定
TopK -SDU 在显著性水平较高的K个线索中随机选一个
SSal -SDU 选择显著性水平大于平局值一半方差的显著线索
tfidf 使用关键字分数加权
SSI 显著性敏感标识 ,不把几个当前句子的显著词的隐含状态进行融合,而是独立表示
intent 这方面是用户意图 ,通过对用户意图进行非线性映射产生一个用户意图向量

若有收获,就点个赞吧
0 人点赞
