是快速分类还是派生词向量
fasttext模型可以被用在两个不同的任务:
- 有效文本分类
- 学习词向量表示
不过我这里讲的还是词向量模型,毕竟是一个词向量专题汇报的内容。
这篇是比较近期的词向量表示的论文,始发于2017年,话说回来还有Mikolov这个大佬,大佬看来这时期已经跳槽到脸书了。
之前的W2V在NNLM上提出了三种简化模型的技术,在大多数类似于英文的语系中,词并不是最基础的单位,单词的内部也存在丰富的语义表示结构,按照论文上说的这种名叫做屈折语的词缀和词形是存在着丰富的形态。这里简单的讲一下,可以理解成 英语里边 love ->lovely->…这类派生规则, 为了引入词形的信息,这里将单词表示为N元字符,同时将一个单词表示为一个N元向量的和,然后对W2V做了扩展。
和这个论文相关的工作主要有两个,一个是形态学词表示:人们通过引入词的形态学特征,使得对罕见词和训练中的未出现词能够有更好的表示效果,毕竟你这个词很罕见,它的上下文也少见,训练集中可能没有,但是组成这个词的词形结构可能在语料里面不是一种罕见词。
另一种就是字符级的语言模型,这类模型直接从字符中学习语言表示。这时期大家都开始使用递归神经网络和卷积神经网络建立字符级的语言模型来解决一些实际任务。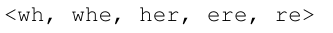
可以看到这里就是对‘where’通过加上前后缀符号得到的三元词形,这里面的词形信息‘’和单词her是完全不同的两样特征。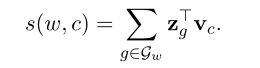
这里可以看见通过对所有的词形N元组构建了一个字典之后,一个词本身也可以看做是n元字符分布的形式,通过对这种分布信息进行加权和计算之后就能得到一个形态表示信息。
为了降低对内存成本的需求这里对N元字典使用了哈希存储的方式,这样一个哈希值可以对应多个N元对象,现在一个词可以用在字典中的索引和包含的n元字符散列集合来表示。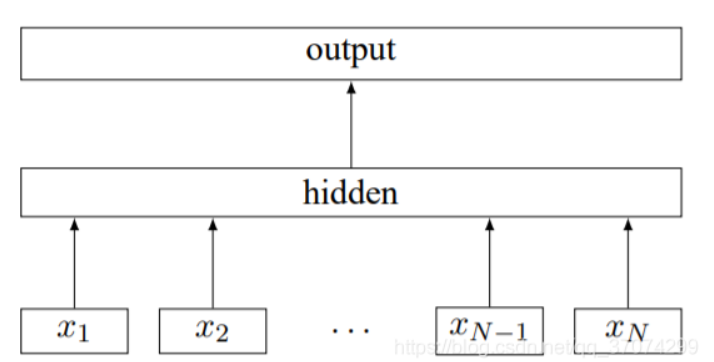
看上图的架构还是很像CBOW的但是这两者存在很大不同,fasttext是将一个词序列作为输入,而不是将一个词的背景词作为输入,同时模型预测的是这个词序列对应的分类标签,而不是原本的中间词。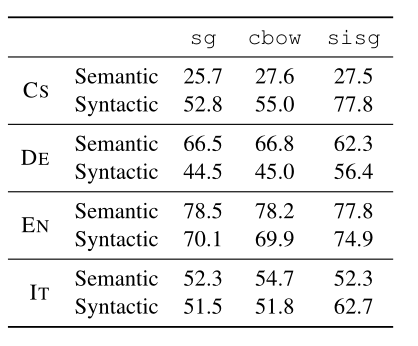
这个就是在捷克语,德语,英语,意大利语上的词义和语法上的类比任务上。
可以看到单纯引入词形信息在常用词的类比上其实性能比不上原本的Cbow,这就更别说skip-gram但是有一点清奇的是,如果对未训练词使用训练后的形态向量和表示,在类比任务上性能就upup了,当然语义表示也相应的有了一些损失。
所以看起来这项技术能够在一些形态表意比较强的语言上使用起来,能够有效的解决未登录词的表示,找了一下在中文领域里面的应用大多数都是用来做文本分类的,看上去中文使用这个学习词向量应该说不是很适合。

若有收获,就点个赞吧
0 人点赞
