过拟合的原因:
过拟合有很多产生的原因,但是基本上可以归属于三类:
- 样本过少
- 训练过度
- 数据存在噪声
决策树中还存在因为没有剪枝产生了单纯的事件数据和非事件数据,神经网络模型中一种是因为选择了过于复杂的决策平面,一种总归还是因为迭代次数过多导致的过度拟合。
正则化分为三种: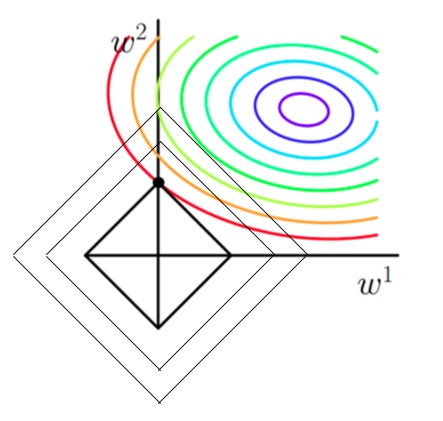
L1: 套索回归(lasso) 就是在代价函数中引入权重的范数,能够使得L1的特征解稀疏化,也叫做 最小绝对收缩 和 选择算子回归 如图可知代表代价函数的椭圆等高图和菱形等高图的交线一定是引入L1正则的代价方程的解,因为两者交点容易出现在坐标轴上,于是解的其他维度容易出现0,得到的解矩阵就成了稀疏矩阵,这一点经常用在特征选择上,剔除出多余的特征减少过拟合的程度
SKlearn 中使用是通过 linear_model import 对应的 Lasso 来使用,其目标函数为: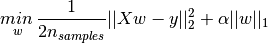
Lasso(alpha =1.0,fit_intercept= True,normalize=Flase,precompute=Flase,copy_x =True,warm_start=Flase,/ positive=Flase,tol=1e-7,random_state=None,seletion=’cyclic’)
参数参考:
:目标函数中的加罚系数, 是否存在截距:没有就过原点,就是“是否加入常数项” 预训练: 复制数据集进行 热启动:要是设置成真每次都会从上次结果继续 强制正值 容忍误差:(精度) 随机种子:保证每次产生的随机数据一样
2.岭回归(Ridge):
岭回归是线性回归的正则化版本:在成本函数中添加一个权重平方的正则项,使得模型的权重尽量保持最小,防止部分特征权重过大,造成对结果的过度影响。
# 进行岭回归前必须对数据进行缩放,因为它对输入特征大小很敏感,过大的特征即是权重较小也会产生过度的影响。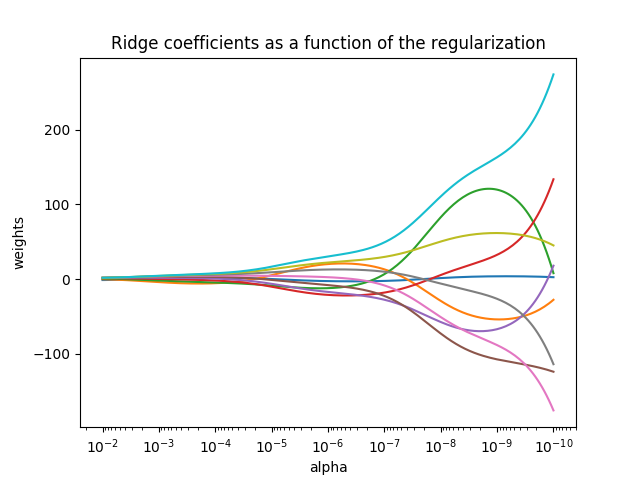
3.弹性网络:
弹性网络是岭回归和Lasso回归之间的中间地带,其正则项就是L1和L2的混合项。通过r系数来控制混合比例。当r=0的时候,弹性网络就是岭回归,r=1时就是套索回归
一般情况下尽量使用岭回归,当有用的特征只有几种的时候可以使用套索回归或者是弹性网络,一般来说弹性网络总是比套索回归要好,因为要是特征之间存在强相关是L1比较不稳定,同时在特征数量大于训练样本时Lasso不是好选择。
4.早期停止法:
在验证误差达到最小的时候停止训练,这一技巧简单且有效,类似“肘方法”
神经网络中使用“drop out”,决策树中使用不纯度来剪枝,也是对过拟合问题的解决方案。
神经网络中解决过拟合问题的最简单方案就是减小模型大小,深度模型善于拟合但是问题的关键是实现更好的泛化
神经网络中正则并不是一个很好的方式因为大部分深度神经网络可能有成千上百万个神经元,使用正则化带来的减小方差可能带来更大的偏差,同时在泛化上并没有很好的收益。

若有收获,就点个赞吧
0 人点赞
