第三周计划
语言学结构:依存分析
- 句法结构:一致性和依赖性
- 依赖语法和依存树
- 基于语法依存的翻译方式
- 神经网络依存分析
对于语言结构存在这两种看法:
- 短语结构语法
- 上下文无关语法
从单个原子结构上来看,词是存在词性的(POS),从更高的结构上来看,短语也是规则关系的,从词性模式上来看,单个词也是存在很多的句法结构,一般来说短语的结构通常是一种嵌套的语法规则,这些语法依存关系可以看作是一种符号规则,仅仅从词性上来看使用这种生成规则的语法是真实文本的超集,听起来还是很不错的,但是真实语言模型应该是一个约束严格的架构。
使用语法树来描述这一系列的语法依赖关系,这个是计算语言学中的一项主流研究范式。
介词是语言理解中存在歧义的重要来源,出现多介词是会使得歧义更加的多。
使用依存分析来理解语言会导致对于长文本和长序列会存在很高的计算度,同时语言消歧的部分的问题也会很严重。使用依存关系树的时候歧义会出现在树的每个位置,同时这种歧义增长的级别是指数级的。指代歧义和并列状态歧义也是语言理解中歧义出现的一个重要来源。
动词短语附加结构也会带来很多的语义歧义状态,也许 
残肢和rio海滩都可以是后面的动词短语的依存主体。
所以这些依赖路径表示了语义关系,这种依存关系中存在的模式可以看作是一种基于语言统计的符号规则。
依存语法有着很长的历史,帕尼尼研究梵语的时候就采用了这种技术,乔姆斯基的语言方式仍然是基于依赖语法关系的。
普遍依赖关系树库;随着注数据的增多。以前人们通过手工编写的语法规则使用解析器来获得相应结构,与之相比从数据中获取这类句子的支撑结构是一个更好的做法,一个可以重用的语法依存库是一个很实用的技术,以前基于规则的技术由于定制者设置的规则是千奇百怪,所以重用性是比较差的一项。
依存库技术:
意味着大量可以复用的技术
很多的语法,部分语音标注,可以使用树库来建立
多样化的语言学资源是可以利用的
使用频率和分布信息
标准弧转换解析器:
- 依存树建立开始只有根节点是存在与堆栈里面的,其他的语料数据是存在与缓冲或者说是缓存里面的。
- 从缓存中取词构建一个概率最大的依赖,当找不到的时候将堆栈的依赖的词退出来,说明该词所有依赖已经建立起来了。
- 当缓存为空的时刻,就是说明了现在所有的依存关系已经被建立起来了
- 过去的人们使用动态编程的方式来建立一个合理的解析器
- 使用机器学习方式建立一个分类器来决定是要做移位还是建立依赖
- 简单的使用分类器来建立语法依赖树可以达到很高的精度,同样的来说,这种分类模型的性能是比不上依存解析器的
- 但是这种使用机器学习模型的方式提出了一种快速的线性时序解析器,同时性能也是相当不错的
如何评估一个依存解析器:
通过有标注的依赖关系来评估这个依赖解析器的精准度:
一般来说是类似于错误份分类的占比来进行评估的,尽量使用带标签的解析器来进行学习,因为比较难的学习任务会使得模型有着更高的性能。
解析器的工作时间的95%是花在特征计算上的,使用神经网络构建的依存解析器可以使依存关系的计算更快,同时不会受到稀疏问题的困扰。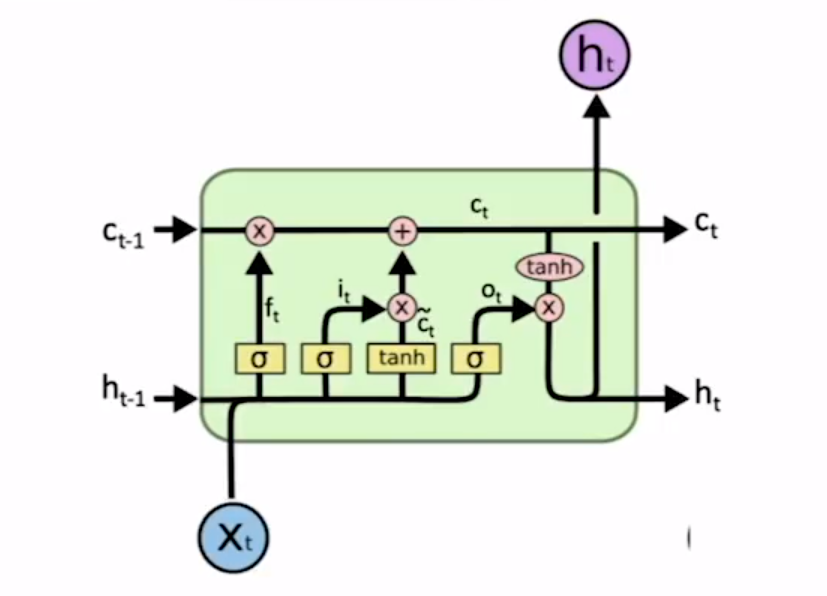
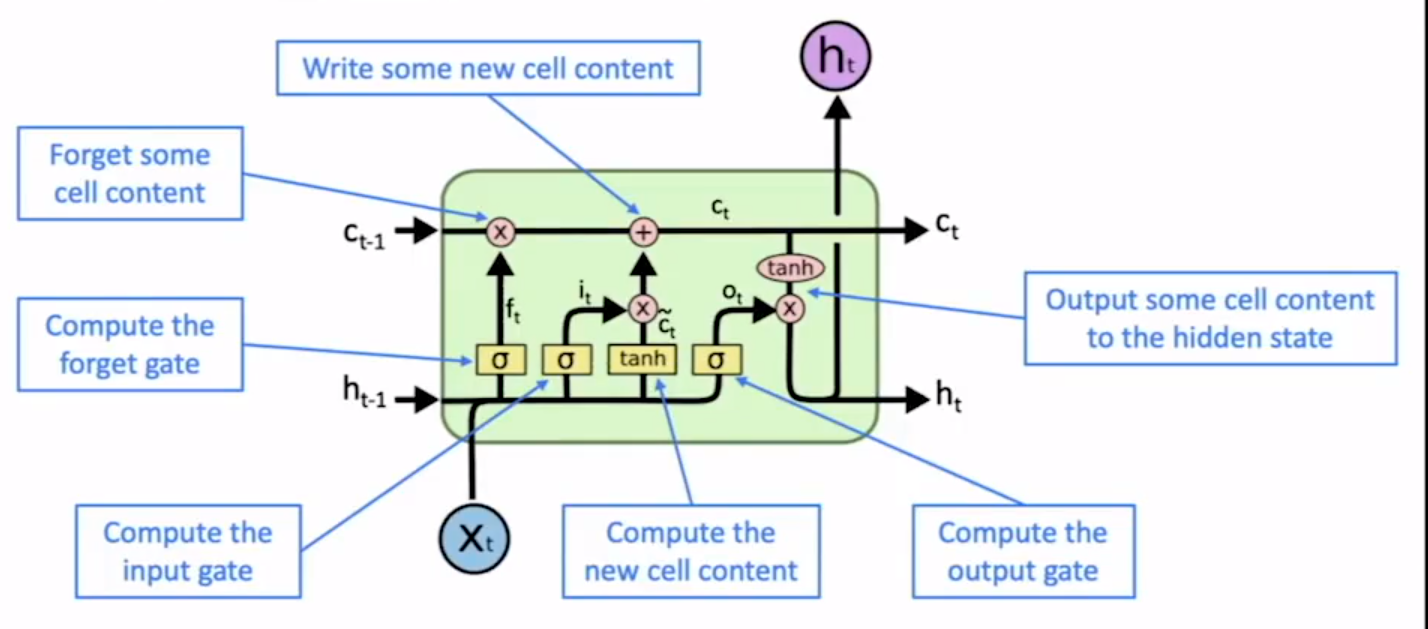
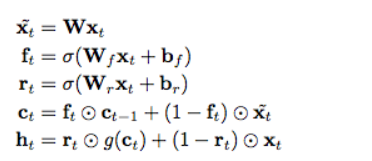
这个是更加激进的SRU单元的数学模型,放弃了前后时序的依赖性,但是仍然保留了细胞单元的设置,好处是计算在gpu上可以并行了,但是模型没法表示时序相关约束。
使用TensorFlow写的srulayer层

2018年这两个模型的陆续提出就进一步提高了nlp任务的基线水准
这本书还是比较新的耶。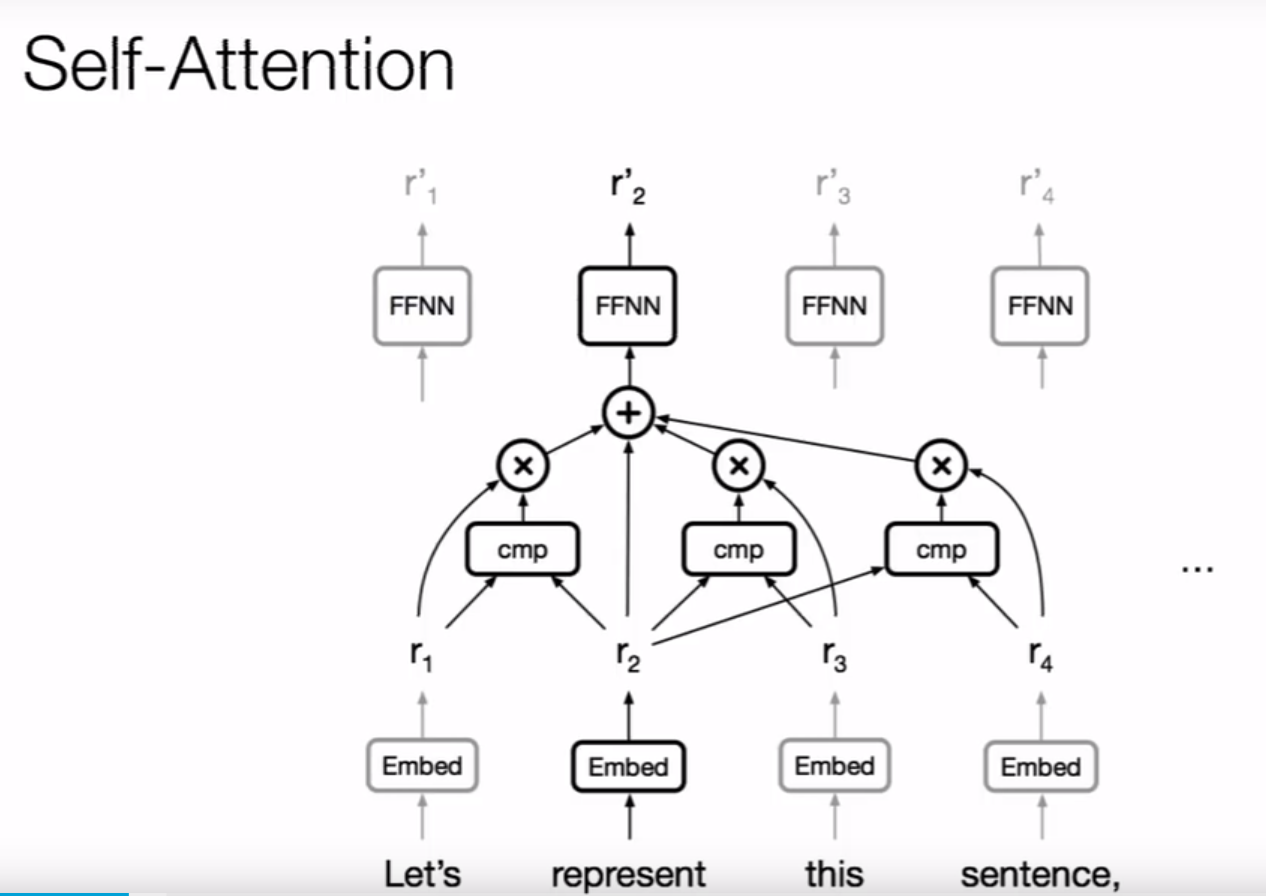
这个是自注意力的早期结构
一个单词的分布式表示是和上下文的其他词的注意力计算得出的
后续增加的前馈层就是为了更好地捕获基于自注意力的表示的特征结构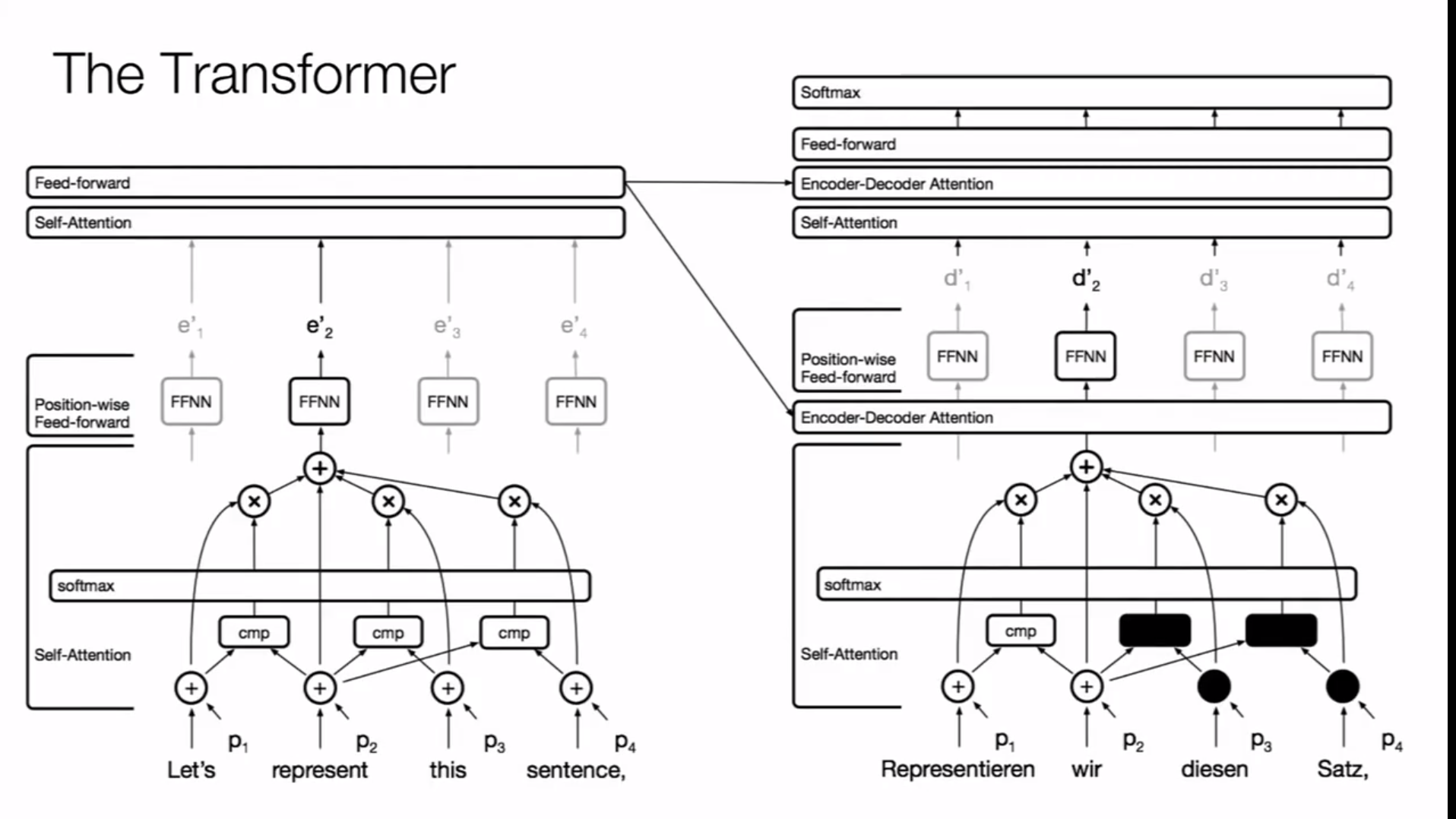
这就是转换器结构的简图,这点感觉还是比较清晰的
主要的几个点就是键值对是怎么来的,为什么注意力中qk的内积会随着dk维度上升,不对这个内积做缩放就会使得梯度越来越小,还有前馈网络是不是两层线性连接层,
位置编码和分段编码表示的内在机制是什么?
使用掩码表示的语言输入是为了模仿语言模型的生成预测的机制,转换器结构并行计算十分良好,因为不依赖前后的计算结果,只需要对输入做个位移就能实现下一个序列的计算,同时这下一个序列的计算其实可以和当前这些序列同时进行编码计算来获得对应的语义表示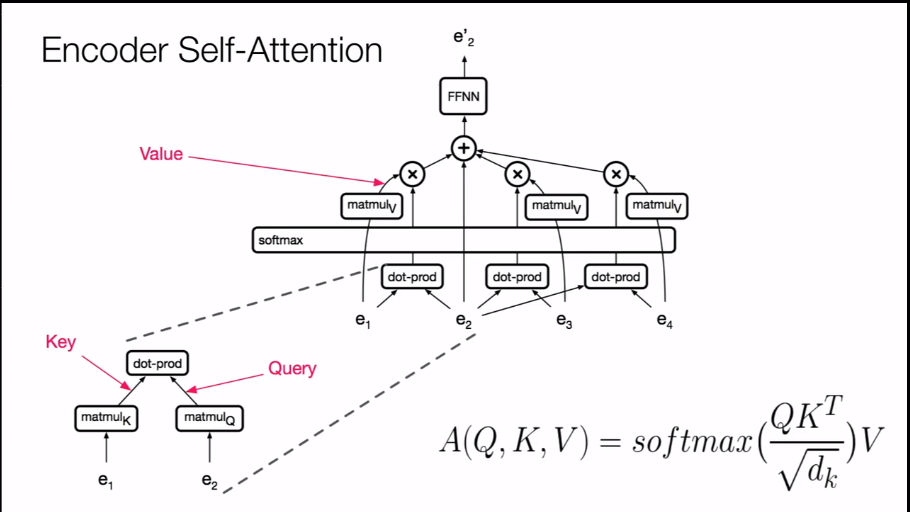
点积计算是数量积,外积是叉乘计算是两个向量按着线性代数计算来得到一个向量积,key值和value组成了一个键值对关系组,
这些key,value,query都是对两个token的编码表示进行线性乘法变换得到的向量表示,这些向量表示在某些程度上被视为是一种浅层特征,点积运算是相似度的很好的表示形式,因为可以视作是两个向量表示之间的夹角,负相关就是负的,正相关的值是正的,正交就是零值
也就是说一个向量的表示是和与其有着某种相关模式的其他词向量表示来决定的,通过多头注意力可以捕获这种关联模式,自注意力在捕获这中相关性之后通过softmax来进行概率归一化,得到的概率作为权重对上下文词向量的线性变换表示进行加权和计算,这就是自注意力得到的词表示情况,这些计算可以用两个矩阵乘法来表示出来,之所以使用是为了避免计算不会爆炸或者说是消失,是起到规范因子作用,使得在计算时不会因为的维度增长,对softmax计算产生影响,毕竟相似性应该是具有维度无关性,这种计算表示的方式是有着相当好的地方,首先这几个是可以并行计算的,在计算自注意力的部分也只有两个矩阵乘和一个softmax,在解码器部分的对数概率计算中存在着一点点不同就是在对数计算里加上了微小的增量,使得计算良好。
三种在nlp上进行表征学习的结构的计算复杂度对比:
- 为什么说自注意力计算成本比较低?
- 因为序列长度是远远低于输入向量的维度的,所以维度上的复杂度才是绝对最终计算成本的因素
- 另外为什么这里看着卷积计算成本是比RNN高但是计算快,因为CNN能够依靠GPU进行高效的并行化计算
- 另外除了RNN其他都能并行化计算,哭了呀老北鼻

可以看到在序列长度和词向量维度相等的情况下,复杂度还是自注意力比较低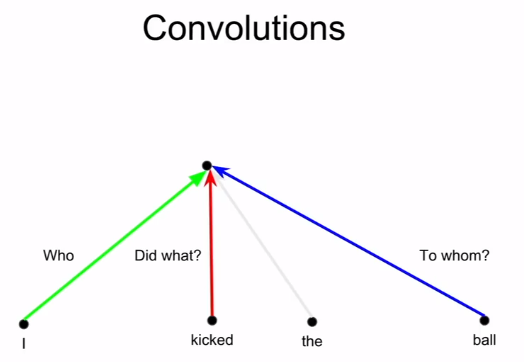
在序列上使用卷积计算的情况下可以看出来,卷积在不同位置上做了不同的线性变换,可以从词的向量表示中得到很多不同的表示信息。从卷积结构中得到启发:
因此如果将注意力视作是某种特征检测器的话,使用多头注意力可以从词的表示信息中获得更多不同的表征,但是多头也带来了额外的开销,每个头都得计算softmax,所以为了降低计算成本,可以降低注意力计算的维度,在低纬度空间中并行计算多个注意力,这样的话,对自注意力的计算不是在一个很高的向量维度上进行计算,而是通过降低纬度来维持相应的复杂度。
但是注意力机制并不是完全替代了LSTM因为lstm可以对任何函数进行建模,只不过注意力机制有利于GPU通过SGD来并行化计算模型权重,注意力通过显式建模方式可解释性会比LSTM更加的好,
归纳偏差;归纳偏置;inductive bias
解释:归纳是基于数据或者样本寻找或者说是总结出一种经验乃至规则的过程;偏置是我们对模型的一种偏好,结合起来说就是,我们总结经验学习出一个更加符合我们需求的模型,英文里面出现,我个人感觉可以理解成一种构建模型的经验技术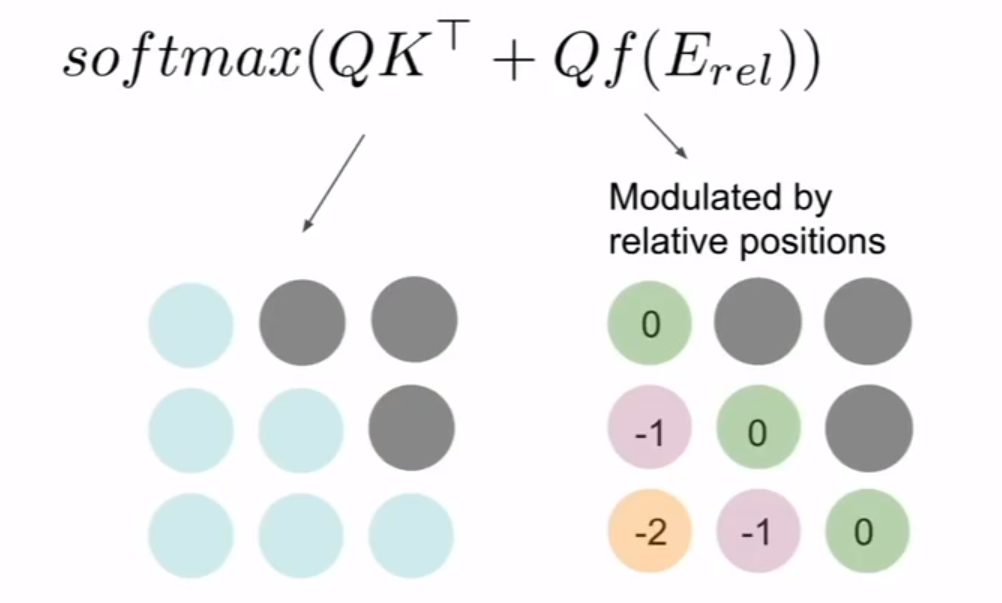

相对注意力也是一个很有效的计算机制,图像上应用相对位置信息是一种比较好的方式。

若有收获,就点个赞吧
0 人点赞
