静态的分布是表示已经不能满足要求
哎嘿嘿,时间到了2018年大家是不是感觉时间点很熟悉,对这正是潘达张毕业的那一年,咳咳咳说错了,这一年是新纪元Bert横空出世,词表示模型此后研究就少了很多,但是ELMO正是在Bert之前问世,这是一个生不逢时的模型。
预训练词向量的历史从NNLM开始进入新时代,但是后续的一切发展都只能是获得一个固定的词义表示,也就是说做不到一词多义的表示信息,这些词向量和当前所处的语境是不相关的。
ELMo也就是语言模型向量表示,也是收到了词形信息的启发,采用了字符卷积来获得词的形态特征。ELMo的词表示是整个输入序列的函数形式,通过使用上下文语义来消解词性和词义的歧义,获得一种上下文相关的词表示方式,这个时候的词表示随着真实的上下文分布来变化的。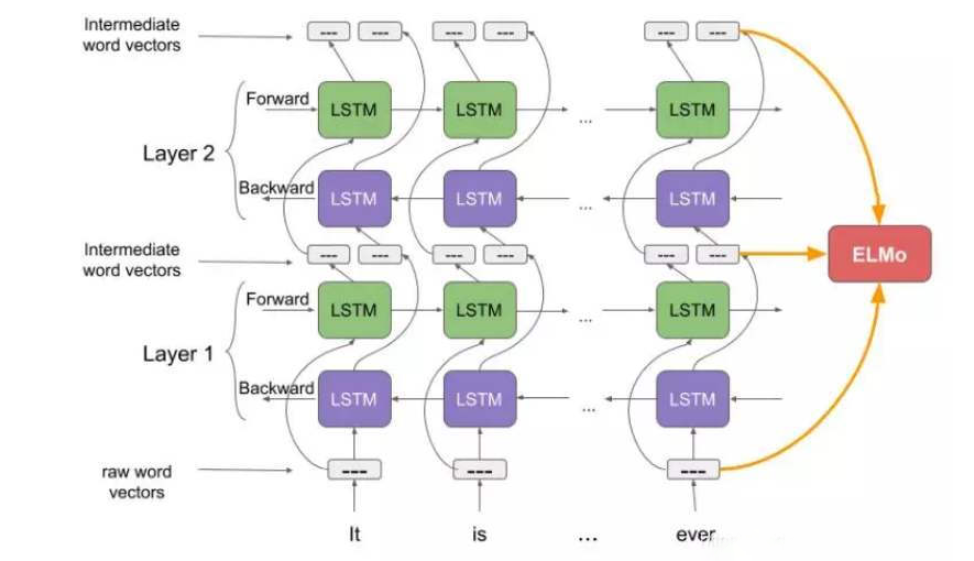
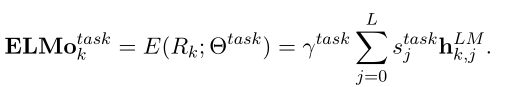
这部分就是将模型的表示向量直接做转换之后接入到下游任务之中,是下游任务对词向量的缩放系数,是softmax的规范权重也就是对各个层的加权,后面还研究了各类任务上适合的加权数值。
这部分模型能够将原生的词向量经过双层的BiLSTM网络得到多层词表示,上图中灰色的部分就是训练得到的词向量,所以这个是预训练语言模型,不是预训练词向量,一般来说经过第一层的L层(简称),就能够得到词性句法的信息,更上一层的L层会获得词意的相关表示,ELMo会联合使用多层的表示向量,这类表示向量中简单使用最顶层的表示形式就能轻易超出当时最先进的词向量表示的性能。简答的使用多层向量均值能够获得更高的性能增益。同时论文提出对于数据样本量比较少的语料,ELMo带来的性能增益是相当可观的。
所以这个模型对词表示影响也是比较大的,利用原有的预训练的词向量、还有这些词的字符卷积特征和当前的上下文分布,得到适应当前语境的多层分布表示,将这些词表示用在下游任务上,同时为了使得这个模型更加适合用作预训练的词表示特征输入,论文还给出了很多的预训练建议,可以看到这时候语言领域对于预训练模型的追求已经很明显了,就是要降低语言任务的成本,就像是论文题目一样这是一个高质量的深层上下文相关的表示方法,很创新的一点就是利用多层级的整体性能还研究了各个层级对语义和句法上面的影响。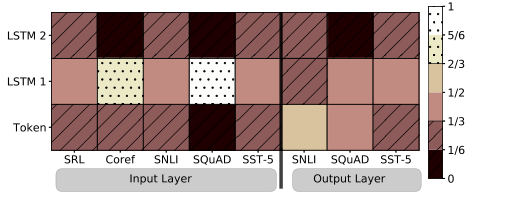
这张图感觉是一个很有意思的图,SRL(语义角色标注)、SST-5(情感分析)、SNLI(自然语言推理)
SQuAD(问答数据集)几乎完全不重视语义信息更重视语法相关信息,coref(共指消解)重视语法,词义也有部分影响。
但是可以看到有一点部分任务在

若有收获,就点个赞吧
0 人点赞
