CS224N:第二周
- week 2: we learn neural net fundamentals
- [] week3: we learn some natural language processing
CS224N:第二周
摘要
正文:
分类器设置和表示
神经网络分类器
命名实体识别
摘要
第二周任务:
我们关键要理解神经网络和它们是怎样通过反向传播来训练的
我们要学习通过窗口内的上下文内容来对中心词进行分类(实体识别)
第一项任务是要学习微积分和偏导梯度知识,
HW1:是使用Ipython Notebook 来应用一段language model 的analogy function
HW2:编写一个使用numpy实现一些简单的梯度计算,以及实现一个word2vec模型的计算
课程3:窗口分类器,神经网络,还有计算
- 更新一些课程信息
- 回顾并介绍分类器模型
- 神经网络的介绍
- 命名实体识别
- 文本二分类
- 矩阵计算介绍
😄wow, um, I am learning markdown form while writing the note for CS224N.
正文:
分类器设置和表示
- 一般来说我们会有一些由样本组成的训练集
- 是输入,可能是词或者是句子,文档等等
- 是标签,是我们试图预测的,例如:情感分类,命名实体,交易决策
简单的案例:
固定的2维词向量进行分类
使用softmax或者是逻辑斯蒂回归
线性决策边界(是线性可分的)
- 传统的机器学习或者统计方法:
假定输出是固定的,训练一个softmax/logistic 回归权重来确定一个决策边界或者说是超平面(hyperplane) - 方法对于每一个输入,预测概率。
- softmax分类的细节:
对不同的输入使用加权和来计算
然后对这个加权和应用softmax来获得正则化的概率,其实一开始的概率肯定是不准的,后边经过若干轮迭代可以得到很高的精度。 对于每个训练样本(x,y)我们的目标是最大化正确分类的概率,也就是黑话‘极大似然估计’。或者我们最小化负的对数概率。
信息论部分:
- 信息量一个随机变量的信息量是,信息量的期望就是熵,也可以说是包含信息的平均程度
- 就是熵的定义形式
- 相对熵又被称作是KL散度,相对熵的定义形式
- 可以看出前面是 也就是说用作损失函数的时候由于-S(A)是真实分布的负熵,后半部分的交叉熵是变化的,因为我们要调整假设的概率分布。
- 由于独热码的使用,正确分类剩下来的就是负的对数概率也就是信息量
- 在数据集上是使用整个分类的平均交叉熵
- 很多时候人们都想使用半监督学习,通过监督训练来猜测标签
神经网络分类器
- 单独的Softmax效果并不是很好
- Softmax给出的仅仅是线性决策边界,这产生的效果相当有限
- 当面对的其实是一个复杂问题,简单的分类器其实是很低效的
神经网络可以学习更加复杂的函数和非线性决策边界
自然语言处理的深度学习的共同点:
权重矩阵和词向量都是学习出来的,
使用矩阵表示方式就是很常见的
激活函数是用来对这些线性加权计算进行非线性映射,或者是计算概率,同时是在元素尺度上进行这项运算的,也就是说对当前层的神经元的输入逐个做这种计算
线性变换和非线性变换
线性变换可以视作是对函数空间进行旋转或者拉伸,但是这种变换也只能时解决线性转换的问题,面对更加复杂的问题,非线性变换可以尽可能拟合复杂的函数形式
一个神经网络 = 同时运行好几个逻辑回归
也就是说通过非线性叠加神经网络近乎可以拟合所有的函数,更深的网络只要解决梯度传递的问题,性能当然会更加好。
命名实体识别
这项任务:发现并且对文本里面的实体名称进行分类
一些可能的目的:
- 追踪文本中特定的实体
- 对于问答系统,回答通常是一个实体任务
- 很多需求信息和命名实体之间存在联系
- 这个技术可以被应用在其他的填空任务上
实体连接和规范也常常用在知识库中
实体命名识别任务中实体边界是很难分清楚的,因为文本中本来就是存在一些没有相关知识就会有多种理解情况,同时新的(或者不明)实体是很难知道如何去分类识别的,仅仅依靠文本的话实体类别是模糊不清的,按照宗庆后在统计自然语言处理里面说的,人的语言本身就是一种因为信息传播低效的条件下,使用的一种高度压缩后的信息来相互交流,交流的双方默认是具备大量潜在知识,可以将存在歧义或者指代不清的文本补充起来,进行理解。
二词窗分类:
通常来说,对单个词分类几乎是很少做的。
文本歧义是一个很有意思的问题。
通过上下文也就是临近词来分类一个词。
通过对窗口内的上下文对中间单词进行softmax分类,使用交叉熵来做损失函数。
一些特殊的方法:
使用未归一的分数做二分类,
早期的实体命名识别是通过上下文分布关系,也就是窗口内的上下文,通过对窗口进行分类来区别中心词是命名实体的窗口和其他视作是错误项的窗口,那些错误窗很容易发现,同时数量也很多。
窗口的分数通过三层神经网络来进行计算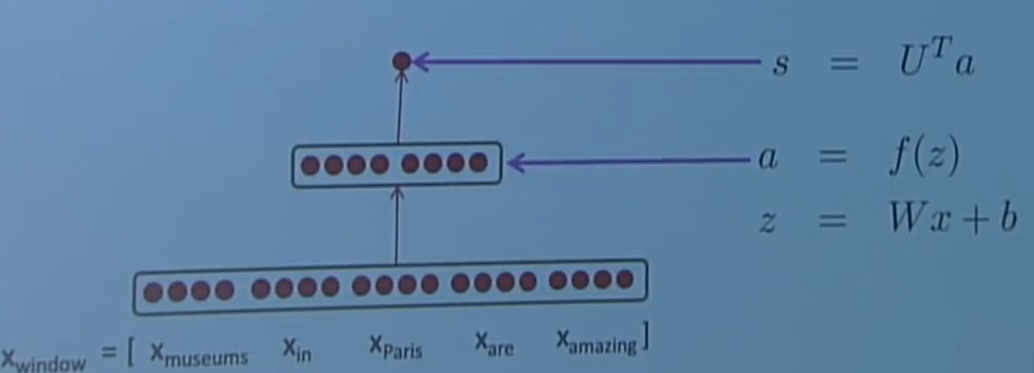
这个神经网络的中间层可以输入词向量之间的非线性关系
回顾一下多向量导数的计算过程:
可以发现矩阵计算全部向量的梯度:
- 全向量梯度计算更快并且比非向量梯度计算更加有用
- 但是在练习过程中非向量的梯度计算更加适合
偏导数矩阵称作雅克比矩阵(Jacobian),the jacobian is an m x n matrix of partial derivatives (偏导数).
根据求导的链式规则,可以求出多变量导数(multiply derivatives)
逐个元素使用的激活函数
后面的部分就是在讲偏导数计算和增量更新
习惯上我们常常把一维的向量表示做列向量,遵循这类习惯使得使用优化算法更加容易。我们更加期望结果能够遵守向量的形状公约,使用雅各比形式对于计算结果是非常有用的。

若有收获,就点个赞吧
0 人点赞
