Identity函数:f(x)=x;
以sigmoid和tanh为主的饱和激活函数, 是常用sigmoid激活单元的非线性函数,用来在神经网络当中引入非线性函数(nonlinearity),sigmoid的梯度计算是其输出函数的函数,
是常用sigmoid激活单元的非线性函数,用来在神经网络当中引入非线性函数(nonlinearity),sigmoid的梯度计算是其输出函数的函数,
 是双曲正切激活函数,它的导数计算就还是很简单,
是双曲正切激活函数,它的导数计算就还是很简单, 这俩个激活函数存在一个问题,只在一个很小的范围内是线性的,在此区间之外则输出趋于饱和,饱和区间类激活函数的梯度非常小,这表示这很容易导致梯度消失问题,神经网络可以从反向传播方法去学习,如果梯度太小会使得神经网络无法有效地学习这些权重。
这俩个激活函数存在一个问题,只在一个很小的范围内是线性的,在此区间之外则输出趋于饱和,饱和区间类激活函数的梯度非常小,这表示这很容易导致梯度消失问题,神经网络可以从反向传播方法去学习,如果梯度太小会使得神经网络无法有效地学习这些权重。
以Relu和RRelu的“非饱和激活函数”有着以下一些优点:
1.解决饱和激活函数的“梯度消失问题”;
2.帮助神经网络一个快速度收敛。

f(x)=max(0,x),这个简单的激活函数在保留了step中的生物学启发的同时,为神经网络提供了非线性变换,对于总输入提供了一个恒定的梯度,这个恒定梯度能够避免其他s形曲线的梯度消失问题,但是Relu带来了一个限制,它对负数输入的零梯度,这可能会降低训练的速度,然而,当输入为负值的时候,ReLU 的学习速度可能会变得很慢,甚至使神经元直接无效,因为此时输入小于零而梯度为零,从而其权重无法得到更新,在剩下的训练过程中会一直保持静默。这种情况下带泄露的修正性线性单元(LeakRelu)函数会很有用,对负数输入,函数的输出和梯度都不是0.
relu的强制稀疏化处理,可能会减小模型的有效容量,
LeakRelu:带泄露的Relu的导数计算就是
softmax单元是常常用来处理多分类问题,将其输出为不同类别的概率, 通常是和交叉熵函数来进行损失估计。
通常是和交叉熵函数来进行损失估计。
不会过拟合
计算简单
比sigmoid/tanh计算简单
参数化修正线性单元(Parameteric Rectified Linear Unit,PReLU)属于 ReLU 修正类激活函数的一员
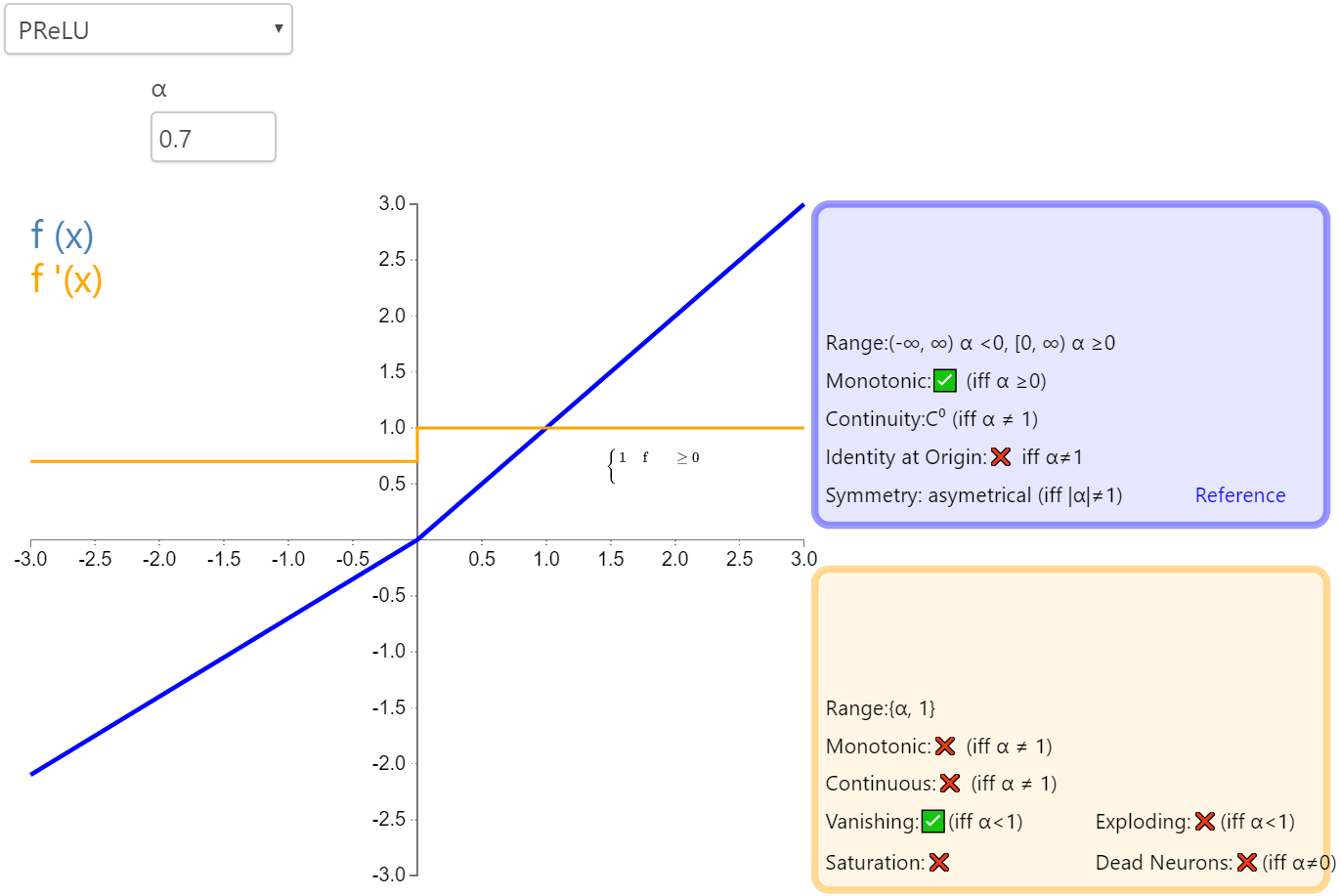
,即为负值输入添加了一个线性项。而最关键的区别是,这个线性项的斜率实际上是在模型训练中学习到的。这也就是名字里参数化的由来。
随机带泄露的修正线性单元(RRelu):
这个RRelu和上边的PRelu不一样的地方是对每一个负值节点的斜率是不一样的,可以说是在训练中使用随机变动的斜率,在测试之中是不变的。
ELU 这一变体在大多数情况下是比Relu是更好的选择,它试图让激活函数的均值为0,同时加快学习的速度。
相比Relu,ELU能够把输出均值往0推,达到batchnormalization的效果(将输出均值接近0可以减少偏移效应进而使得梯度接近自然梯度)Elu在负值时是一个指数型函数,对于输入只定性,不定量。
所以ELU在减小计算量上比较有效果,Relu在和BN一起使用时精度效果比较好
selu 自归一化函数
swish函数效果很好
gelu
maxout 和dropout 联合使用起来很好

若有收获,就点个赞吧
0 人点赞
