词向量和词义表示
it’s lesson two:
这是斯坦福自然语言处理公开课的第二节:
教授关于词向量空间的说法是:词向量空间的向量包含了一定的语义,因为词向量的表示形式是由和它一起出现的上下文词向量的共现分布决定的,与这个向量越相似的词向量越可能是其近义词。
使用analogy可以对词向量关系进行类比:
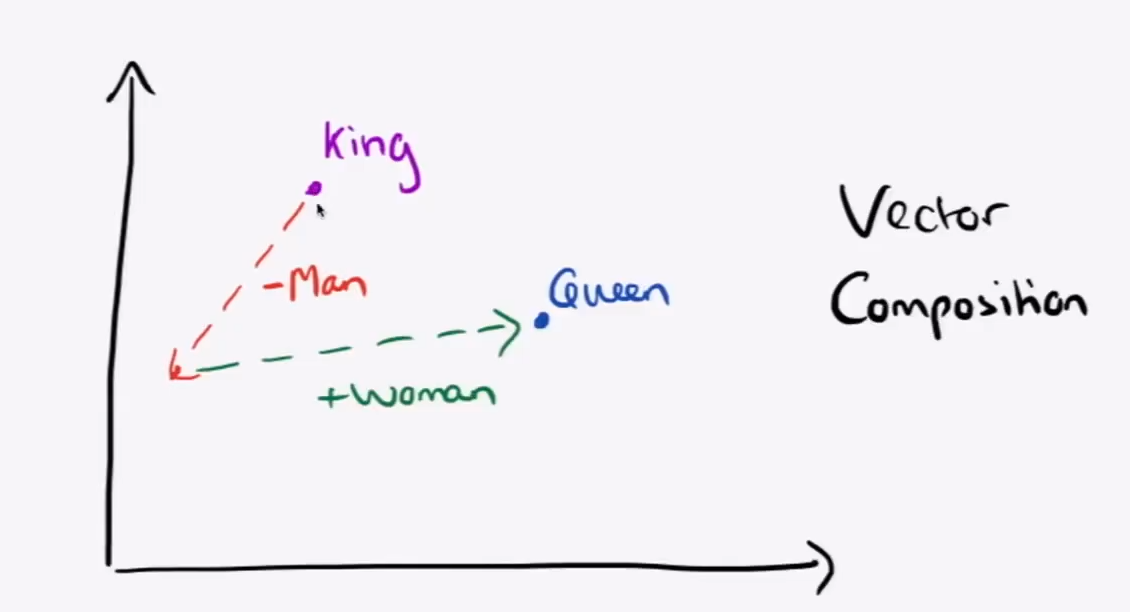
示例: analogy(‘man’,’king’,’woman’)->’queen’
这种运算是和上图演示的原理比较接近的
类比推理的原理就是一个和词向量计算相近的词向量,根据吴恩达说这种计算的准确率只有30-75%
而计算词向量相似性的方式是使用余弦相似度cosline
示例:analogy(‘australia’,’beer’,’france’)->’champagne’
也就是说澳洲和啤酒的关系就是法国的香槟
于是出现了一个问题,这类词向量使得词汇指代表意是固定的,
示例:model.doesnt_match(‘breakfast cereal dinner lunch’.split())->’cereal’
使用doesnt_match函数能够选出词汇里边差异最大的一个
这里就是使用PCA降维来对词向量做可视化,在可以用二维方式展示的基础上尽量保留原向量空间的信息
主要逻辑就是如果没有指定词就可视化模型自带的词表,同时在散点图上标记对应的词的‘文本’
这部分也要修改成三维样式的化
threedim = PCA().fit_transform(word_vectors)[:,:3]
plt.figure(figsize=(8,8))
ax = pltaxes(projection='3d')
ax.scatter3D(threedim[:,0],threedim[:,1],three[:,2])
for word, (x,y,z) in zip(words,threedim):
`plt.text(x+0.005,y+0.005,z+0.005,word)`
感觉上使用三维散点图应该会更加好一点
#使用方式:import matplotlib as pltplt.figure(figsize=(8,6))ax = pltaxes(projection='3d')ax.scatter3D(X,Y,Z)plt.xticks(range(11))plt.rcParams.update({'font.family':'Time New Roman'})plt.rcParams.update({'font.weight':'normal'})plt.rcParams.update({'font.size':20})plt.xlabel('X')plt.ylabel('Y',rotation=38)ax.set_zlabel('Z')plt.savefig('3D.jpg',bbox_inches='tight',dpi=2400)plt.show()
这个部分就是显示三维散点图的方式,其实可以进一步减少代码量
关键的部分是%20%20plt.show()#card=math&code=ax.scatter3D%28X%2CY%2CZ%29%20%20plt.show%28%29&id=zEb3E)
这类使用起来还是比较简单的
也就是将PCA可视化散点的二维散点图函数换成现在的这个三维的
在视频中基本上可以看出这种PCA投影方式还是能看出词之间的相似度远近
正式的第二课内容:词向量和词意
- 完成对word vector and word2vec的课程的观看
- 基本的优化原理
- 通过计数方式来捕获词意的本质
- Glove词向量模型
- 评估词向量
- 词意
- 总结这堂课
- 目标是这堂课结束后能够阅读词向量论文
所以这堂课就是在讲如何通过对共现信息的统计来捕获词意,构建一个密集词向量模型
回顾word2vec模型的主要思想
- 对整个文本语料中的每个词迭代处理
- 用词向量来预测周围的词汇
%3D%20%5Cfrac%7Bexp(uo%5ETv_c)%7D%7B%5Csum%7Bw%5Cin%20V%7Dexp(uw%5ETv_c)%7D#card=math&code=P%28o%7Cc%29%3D%20%5Cfrac%7Bexp%28u_o%5ETv_c%29%7D%7B%5Csum%7Bw%5Cin%20V%7Dexp%28u_w%5ETv_c%29%7D&id=jrHzb)
- 更新词向量是的预测更加准确
我们需要的是一个具备可解释性的对文本中的所有词都有很高概率的预估模型,使得预测的上下文词汇能够在真实语料中出现频率尽量大。
所以说从另一个方面来说这类词向量表示模型的目标就是使得相似的词在空间中位置临近,差异性较大的词尽量远离。
梯度下降算法的思想就是for current value of θ,calculate gradient of J(θ),then take small step in the direction of negative gradient.And Repeat
也就是说梯度下降通过向函数负梯度的方向前进来搜索最优点
当然也可能是nonconvex非凸函数,这种情况下可能存在局部最优点,优化算法必须有跳出局部最优点的能力。对于真实情况所对应的抽象函数来说,函数的形状不可能是一个简单的曲线,也不会很平滑。
在一片专门介绍词向量基线模型的论文里提到一些不表达确切意思的高频词类似于“not” ‘and’‘of’
这类介词出现频率很高,如果对这些高频词使用平滑方法会使得模型对词向量的相似度计算更加准确
这也是引入停用词的原因;(更加极端的做法,去除停用词)
对于文本相似性任务使用简单的加权平均的方式计算的效果是优于其他的各种各样的方法
关于词权重计算的方式使用$\frac{\alpha}{\alpha+p(w)} \alpha$是一个参数,p(w)是估计的词频
这种权值设置被称作是平滑逆频率,这种方式明显好于简单的未加权平均计算的方式
这种平滑逆频率的方式和信息检索里面的TF-IDF的文档逆频率计算很相似,这种思路我觉得也应该是一致的,一个句子中表达核心意思的词不应该是文档出现最多的词,也就是说使得高频词对句意的影响尽量变小。
大多数词向量嵌入方式使用词汇在文本中的共现信息来更新词向量,也就是说这种方式会使得一些没有实际意义的高频词得出一个大向量。如果使用简单的向量平均和方式会使得句向量会在没有意义的语义方向上拥有更多的分量,有意思的是这种平滑加权的方式在测试环境中比TF-IDF方式效果上要好出不少,
详细的部分我会写一个词向量论文研学的笔记:
使用全批量梯度下降的方式因为单个更新的计算成本过高所以这种方式对于所有相对深的网络来说都是不适合的一种思路。
解决方法:随机梯度下降:
在窗口中随机采样,然后更新每一个。
优点:随机梯度下降能够获得的噪声是比较少的,
执行并行操作时时间成本会相对低,参数更新更加快
词向量的随机梯度更新梯度值是很稀疏的对象
- 我们可能只是想要更新实际出现的词的向量
- 你或者使用稀疏矩阵来更新全向量矩阵的某一行,或者你需要词向量的哈希
使用32的倍数作为batch_size有利于GPU进行并行计算
于是问题来了mini_batch里面的语料比较少,如果使用的是32这类大小窗口大小为5的时候,可能会只有100个不同的词,于是我们可能只是更新了在语料中出现的那些词的向量,未出现的词向量没有得到有效更新
解决问题的方法是要把稀疏矩阵更新的操作从只更新几行变为更新全部向量
或者你需要为词向量保留一个散列(哈希);
另外的一些训练有效技巧:
负采样技术:
迄今为止,我们关注的还只是简单的softmax,这是一个相当简单但是计算成本相对比较高的方法
因为这个规范因子的计算成本实在是有点过高,你得计算整个词表中的每个词的概率
因此在标准的w2c里面实现skip-garm模型是利用负采样
主要思想是为一个真实数据和对照的几个噪声对对训练一个二分类的逻辑斯蒂回归模型,
马尔科夫在2013年的词和短语以及他们的组合的分布式表示:
通过负采样来使得得到随机词组的可能性最小,得到真实的共现词汇的概率最大化
这种方式可以极大的简化计算
%7Bneg-sample%7D%20%3D%20-%20log(%5Csigma(u_o%5ET%2Cv_C))-%5Csum%7Bk%3D1%7D%5EK%20log(%5Csigma(-Uj%2Cv_C))#card=math&code=J%28o%2Cv_c%2CU%29%7Bneg-sample%7D%20%3D%20-%20log%28%5Csigma%28uo%5ET%2Cv_C%29%29-%5Csum%7Bk%3D1%7D%5EK%20log%28%5Csigma%28-U_j%2Cv_C%29%29&id=sIvHm)
在这里面前半部分是真实出现的词向量的概率估计,后边是k个随机词的概率估计取负
当窗是5的时候也就是要对是个随机词进行概率估计的时候,负样本可以选取为15也酒是K的取值
单词分布U(w)使用了3/4的幂指数,也就是减少常见单词的频率,类似于加权相对来说减小了(这部分也是通过用作超参数设置探索出来的)
毕竟高频词在词意上大部分是不表达确切指意的
讲到对w2c的改进的思路:
为啥不使用共现次数的和?
使用共现矩阵X来统计共现信息:
- 有两种选择一种就是:使用加窗来获得局部共现信息 另一种就是对整个文档中词汇的共现信息进行统计
- 共现矩阵是一个巨大的稀疏矩阵,也就是说这个矩阵只有很小一部分是能够
- 随着词表的增长,共现矩阵会有非常高的维度,需要很大的内存,使用其他方式来表示稀疏矩阵或许花比较少的时间
- 后续序列分类模型有着稀疏性问题
- 模型的鲁棒性不高(不够健壮,泛化也比较差),因为单元格中很多词没有出现(词表中的词)
解决方法:
- 使用一个固定的低维度的方式来存储重要信息
- 通常是使用25到1k的维度,这点和w2c很像
- 所以怎么减少维度呢?
对共现矩阵做奇异值分解(singular value decomposition)也就是PCA降维
将X共现矩阵分解为UΣ,这里面U和V是正交的,也就是对应行列的正交基
分解之后丢掉最小奇异值的维度,保留K个奇异值最大的维度
$\hat {X} $是X的最佳阶数近似,这项技术在2k年的时候是非常流行的
主要是用在潜在语义分析和潜在语义索引方面的应用
使用对数缩放方式的思路来自于信息检索领域,另一种做法是使用截断计数
在W2C里面采样窗口对附近的词计数次数更多一点,这里开始考虑使用皮尔逊系数来代替计数方式,同时考虑把负值设置成0,也就是说这里面用词汇的相关性程度来代替共现计数,同时将负相关性的词汇
在词共现空间基础上构建一个线性空间用于计算语义相似度,这个线性空间中的向量的方向分布之间是存在一些有意义的线性倾向。
以前有着两种研究词向量模型的流派:
一种就是在词的统计方式进行改良,LSA,HAL,COALS,Hellinger-PCA
这种方式训练快,有效的利用了统计方式,主要是用来捕获词的相似性,计数比较大的词的权重是不成比例的
另一方面神经网络方法也很快的应用在这方面,基于语料大小的精度,统计数据的利用度不是很足够
但是可以在任务的执行过程中逐渐提高其表现,但是可以捕获更加复杂的模式信息(比起词的相似度信息),基于采样方式的过程对于统计数据的利用是不充分的
用向量方式来编码语义区别:2014年 Pennington等人在EMnlp上分享了这项研究
对这些词向量表示模型的关键研究发现,共现概率的比率可以被编码成一个有意义的分量,
所以我们怎么把捕获的共现概率转化为词向量空间中一个有意义的线性分量
对数线性模型 使得词向量点积等于共现概率的对数线性模型
向量的差集是对数的共现条件概率的比率
如何评估一个词向量
联系到一般的NLP任务:内部评价和外在评价
内在评估:
在某个特殊子任务上评估
计算很快
有助于理解这个系统
外在评估:
在一个真实任务上评估
为了计算准确可能要花很长时间
如果这个子系统是一个问答或者是一个交互甚至是其他的子系统,这种评估是难以清晰的体现出来
也就是说在复杂系统中这一环节的改进可能在整个系统中无法明显的体现出来
如果使用另外的子系统来替换实际的一个子系统能提高精准度
那就好得多
NerualIPS2018 词向量的维度 On the Dimensionality of Word Embedding
词向量当中的维度其实是对偏差方差折衷的一种反馈
通过矩阵摄动理论揭示了词向量模型选择中基本的偏差方差权衡
维基这样的百科全书中涉及到的解释性文本有助于语言模型的训练
这种词向量化的形式是多个词义的加权平均值,有一个很令人惊奇的结果是因为是在高维空间中来对稀疏变量进行编码,我们可以分离并还原这些词义
使用良好的词向量模型可以在很大程度上使得文本任务的性能得到提升

若有收获,就点个赞吧
0 人点赞
