自然语言文本生成 CS224N:
解码算法是根据语言模型来生成文本序列的一个算法, 常见的解码算法有:
- 贪婪解码
- 波束搜索
贪婪解码每一步只要概率最高的,波束搜索会在每一步关注当前路径概率最高的k个。
k很小的情况下其实是接近于贪婪搜索的,更大的k意味着能考虑更多的假设,但是计算成本也是更加的高。同时增加束的数量会降低BLEU的评分,可以看作是BLEU的分数和实质的翻译过程是存在差异的,因为束搜索会使得生成序列更加的短。同时束增大会生成语法规范但是相关性的低的序列。
采用自适应束搜索方式可能能够提高假设空间的范围,但是应用起来存在着问题
采样解码方式:
- pure sampling 纯采样方式 每一步从概率分布中随机进行采样,
- 和贪婪算法类似但是使用采样来代替了最大值
- 进行top k 采样随机采样k个最大概率的词
- 增加k的值会使得生成的句子更加多样化
softmax温度超参数,也就是对每个解码分数除以一个温度超参,参数的值越大概率分布就会更加均匀,降低这个超参概率分布就会越加尖锐,同时陡峭。
摘要生成任务存在两种不同的思路:
- 抽取式摘要:使用原文中的一些句子组织成为摘要
- 抽象式摘要:通过自然语言生成技术来生成新的文本
- 比较起来抽取式摘要的下线比较高,容易生成一个看的过去的摘要
抽象式摘要的上限比较高,因为更加自由同时更符合人类撰写摘要的过程。
内容选择算法:
使用一个计分函数来计算每个分片的句子分值,类似使用TF-IDF或者是TextRank
或者说句子处在文档中的位置信息也是一项比较重要的数据。
基于图的算法:
图算法将句子看作是节点,文档是这些节点构成的图集合,边就是每一个句子对。边的权重就是句子之间的相似性,使用图算法来确定哪一个句子是处在图的中心位置,也就是对应最大连接图的核心节点,对应的是表意最丰富的句子。
摘要的评估方式是以召回率为核心标准,这一点大家都可以看到。
对于机器翻译任务来说精度明显是要比召回重要的,因为生成的翻译语句都得是对的。
摘要式句子是对文章的一个总结,可以存在噪声,但是要尽量将包含文章指意的句子摘出来。但是在论文里面通常使用的是F1值来代替ROUGE估计是没有定义一个明确的最大值。
ROUGE对于不同的n元组是有着不同版本的评分估计,BLUE对于所有n元组做了一个合并估计。ROUGE是对于单个重叠词的召回率评估,ROUGE-L是对最长子串的召回率评价。
python脚本实现了一个很便利的ROUGE评估方式。但是ROUGR作为一个摘要的评估标准是存在一些问题的,
使用层次注意力或者说是多层级注意力来实现神经网络摘要
对全局文本信息进行摘要总结,选择摘要语句的时候执行更多全局文本选择
使用强化学习阿里最大化ROUGE或者其他的离散指标。
Seq2Seq模型存在一些问题,模型在生成的文本很流利,但是在抽取文本细节信息上做的不到位,抽取机制通过注意力来使得Seq2Seq架构很容易抽取输入文本里面的信息。
这点对于摘要抽取来说是比较重要的,同时使用抽取和生成能够给我们一个混合的抽取摘要的方法。
通过上下文和部分摘要的潜在信息来决定当前的词是使用生成方式还是使用抽取机制。这种混合机制使得输出的最终分布是生成分布加上抽取分布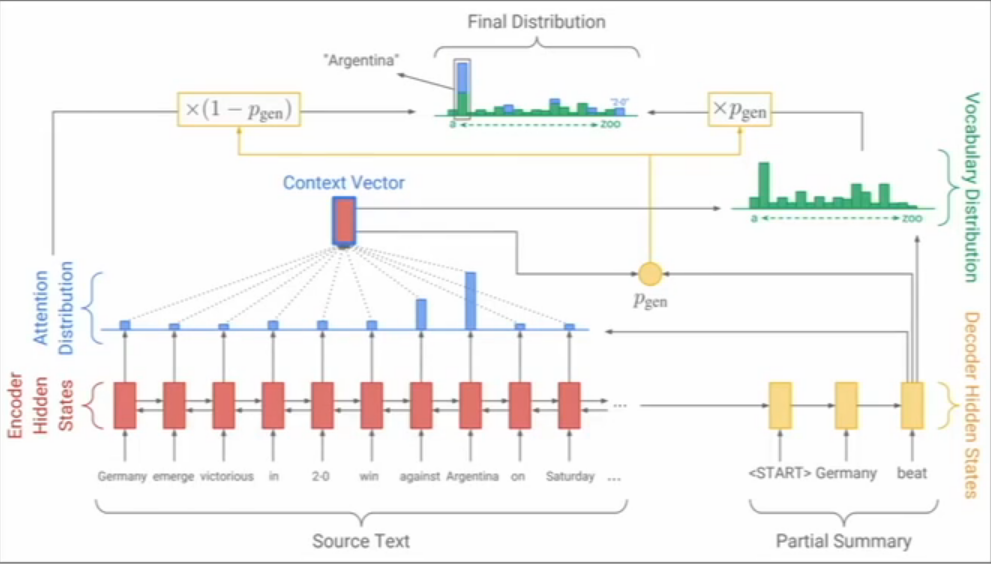
image-20210602151651140
混合机制的摘要生成架构
但是抽取机制存在问题,因为使用的是召回率作为标准,抽取机制来组织摘要肯定有很多冗余的文本成分,存在很多长词汇有的时候使用的是整个句子。生成机制在文本内容很长的情况下,在召回率上表现不好,毕竟生成的内容更多是一种语义近似。
在之前这种文本选择和表意理解是一个相互分离的一个过程,现在通过混合机制使得两个阶段是存在相互关联的。我们解码的环节现在做的是词汇级别的文本选择,但是这存在一些问题,我们使用的选择策略利用的是局部信息,在整个文本上看起来可能不是很恰当。
近期自下而上的文本标注模型的方法被引入到摘要生成上面,将摘要构建的过程变为两个阶段,第一部分抽取环节使用序列标注模型来决定是否选择每一个词;第二部分序列注意力机制不会使用第一部分未选择的词(使用掩码技术),这种方式从文本整体开始考虑,比起摘要策略要好上很多,因为不会偏好于对于长序列句子的抽取。
另外一个思路是使用强化学习来对ROUGE来产生最大化,但是最大ROUGE分数的模型生成的摘要几乎没有可读性,这也是说明了这些指标并不是完全贴合人类认知,在一定程度上甚至相距甚远。
对话任务的具体形式完全取决于任务场景的需求,开放领域的对话系统是一个很难的自然语言处理任务,在神经网络时代之前,人们往往是使用预定义模板或者检索回答语料中的相似回答,然后使用语言模型在中间填充一些过渡内容。对话任务能够分为辅助、合作、竞争对话任务和社会对话(闲聊和心理治疗)。
神经网络时代人们将Seq2Seq应用于对话系统,但是这种序列方式存在一定缺陷,这种缺陷比在摘要任务上更加严重,可能予以无用的回答,重复的回答,序列模型缺乏对语言中隐含的知识的信息,同时回复可能与上下文无关。
注意:Seq2Seq模型的优点就是能够生成流利可读性高度序列,这是因为存在一个lm的子模块。
无关回复是因为有可能这个回复比较常见,也有可能是模型将对话主题转变做了某个不相关的内容。一个解决办法是最大化输入和回复的互信息指标,使得两者之间的关联程度变高。
一些简单的改进方式可以直接上调束搜索中一些罕见词的权重,或者说是使用采样解码来代替束搜索,或者是使用一些条件改进,使用一些额外的上下文内容来生成一些有关回复,对回复语料进行检索和优化来适应对话内容,而不是选择从头生成,(对语料库中人类回复进行采样,然后进行一些编辑使它更加适应当前的一些场景)这种方式通常会产生一些有意思的内容,但是这个编辑过程是比较复杂的。
对于重复内容问题,一个简单的方式就是在束搜索中禁止出现重复的n元成分,这个方式使用起来简单而有效。或者说是训练一个掩盖机制,防止注意力多次关注到一个词,或者是定义训练目标(乘法重复内容),但是这种方式需要类似强化学习的技术来训练,因为这是一个完全不可微的输出生成的函数。
故事生成:绝大多数神经网络故事讲述工作都是使用了某种提示或者说是起始激励
给出一张图片用来生成故事,给出写作提示。
在缺少对照语料的情况下,如何进行文本生成工作。
使用常见的句子编码空间,使用跳过思考连(直觉)向量,这里的思路是和分布式表示比较相似的,使用COCO数据集来学习一种图片到直觉向量(它们字幕的编码)的映射关系,然后使用一种目标风格的语料来训练一种语言模型来对直觉向量进行解码。
从图像上生成一个句子,使用基于CNN的Seq2Seq模型来推动故事模型,使用门控制的多头多尺度的自注意力,自注意力对于捕获长程上下文来说是比较重要的,门结构允许注意力有更多的选择性,不同的尺度的注意力头意味着有更多不同的注意力机制来检索多粒度信息。
预训练一个序列模型,然后再训练第二个模型连接到第一个的隐藏状态上,第一个模型学习生成通用的语言模型,第二个模型学习基于激励条件下生成。
生成效果是比较好的,内容比较丰富,和提示有相关性,生成出来的内容也是有戏剧性的
然而,内容上主要是基于渲染,描述和环境,但是事件很少,如果生成的内容是比较长的,内容也不会更新,依然会就在这个主题上打转。
使用自然语言模型的故事生成技术虽然有流利的文本,但是缺少意义,没有情景,缺少连贯性。因为语言模型是基于词的序列结构,但是故事却是事件的序列,要描述一个故事:
-事件 - 人物和他们的性格特点 - 故事冲突 -遵守讲故事的规律。
事件到事件的故事生成,理解句子,抽象作为事件,然后预测下一个可能的事件,事件转化为句子,增强上下文的相关性,得到下一个句子。
基于结构的故事生成,故事激励,使用词性标注来生成关系结构,生成使用实体占位符描述的故事,将占位符转换为特定的相关词。组织为整个故事,
跟踪事件、实体、状态,但是这些方法对于自然语言处理来说还是一个比较困难的任务,所以说缩小领域,不是应用于开放领域而是在某些特定情况下的场景应用,反而是比较实际,跟踪词状态来生成线索。神经网络可以生成一个线索结构,给出其中的子部分,
自然语言理解的自动评估指标基本上:
- 基于词重叠的标准 :BLEU, ROUGE,METEOR,F1
- 但是我们都知道到这些标准对于机器翻译来说不太理想
- 在摘要上这些标准起到的作用也不是很大,更不好的一点是Rouge甚至会鼓励抽取式摘要而不是抽象式摘要。
- 当然在对话系统上这些标准甚至更差,因为对话系统比起摘要来说是更加开放的领域。这一点上故事生成也是类似的。
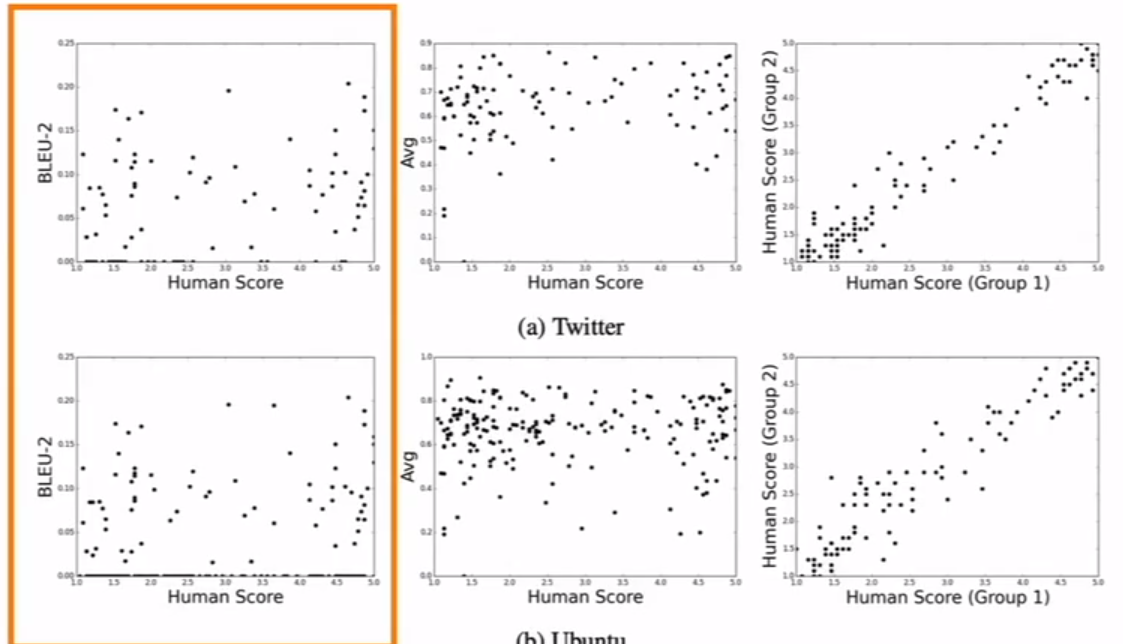
可以看到的一点是人类评估上存在很强的相似性,这个关联程度比起这些标准来说明显更加恰当,但是人类评估缺点是难以在短时间内处理海量数据。
那么困惑度指标怎么样?
- 困惑度只能表示你的语言模型的性能强弱,但是不能体现生成相关的任何信息,也就是说解码部分不受评估
- 词向量相似性评估标准同样和人类评估不存在关联
所以说这些自然语言生成任务几乎没有很适合的评价指标:
- 流利程度
- 正确的风格
- 多样性 使用稀有词的频率或者说数量
- 和输入存在相关性
- 输出序列的长度和重复度
- 特定任务的指标:例如摘要任务的压缩率
- 虽然这些方面没法体现出整体的生成质量,但是可以帮助我们追踪一些重要特性
人类评估一直是视作黄金标准;但是人类评估效率低成本高,同时人类评估也不能解决所有问题,高效的人类评估实施是很困难的,人类存在不一致性,可以是非逻辑的,没有解释性,或者评估不用心。
往往来说人类评估是项目中最困难的事,通过设计一个分离影响整体聊天机器人性能的重要因素的人类评估系统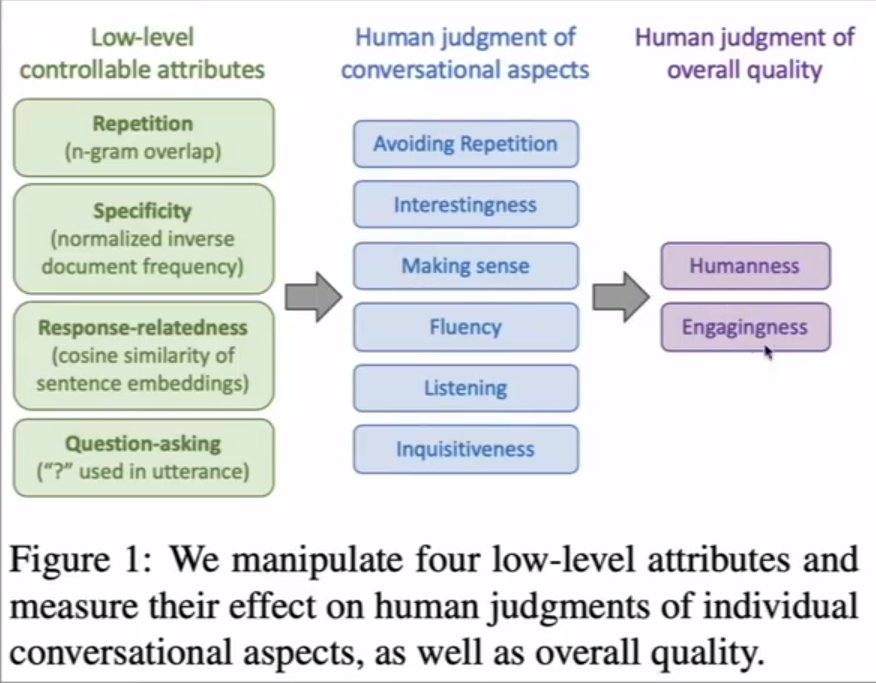
通过将低层级的评估属性转化为抽象的方面来让人类评估。而不是让人来评估整体质量。
- 可控的重复对人类评估来说是很重要的
- 问更多的问题提高参与感
- 可控的特定词汇提高实用性和趣味性还有理解对话的能力:但是人类评估对这种新奇相关的对话要求很高
- 全面的指标使用性是比较容易最大化的,这里比较接近于人类标准
- 接近人类标准还是比较困难的
- 另外人类标准和对话质量也不是等同的
- 另外人类也不是理想的对话对象,他们的对话缺少趣味性,流利程度也不够,倾听能力也是比较差的,并且提问也比较少。
未来的自然语言生成的趋势:
- 把离散潜在变量融合到自然语言生成之中
- 替换严格的自回归生成模式,对照生成,迭代修改,自顶向下生成更长的序列
- 替换使用教师模型推进的最大似然的训练,使用句子级别而不是词级别的东西
自然语言生成仍然是一片蓝海,因为缺乏有效的自动评估指标。即是是自然语言社区发展很迅速但是生成任务仍然很困难,越开放的任务往往会更加困难。一些约束反而会使的任务更加简单,特定方面的改进可能比全面生成质量的改进更加有效。
一般来说更好的语言模型会生成更好质量的文本。
对于生成任务来说对输出的观察可能比任何指标都有效,因为指标是不可靠的。大量查看生成结果可能会对你的模型改进更加有效。
你需要一些自动评估的指标,虽然这些指标并不完美;如果你要使用人类评估的方式,尽量让你的问题更加具体。另外一点再现性对于现在的深度学习NLP是一个重大问题,当然这点在自然语言生成中也是更加严重。
发表论文时候开放你的模型的输出是很有意义的一件事。这会使得后来的研究者可以使用适合的自动化评估指标来确定适合的技术路线。

若有收获,就点个赞吧
0 人点赞
