PLM和PTM 两种称呼:
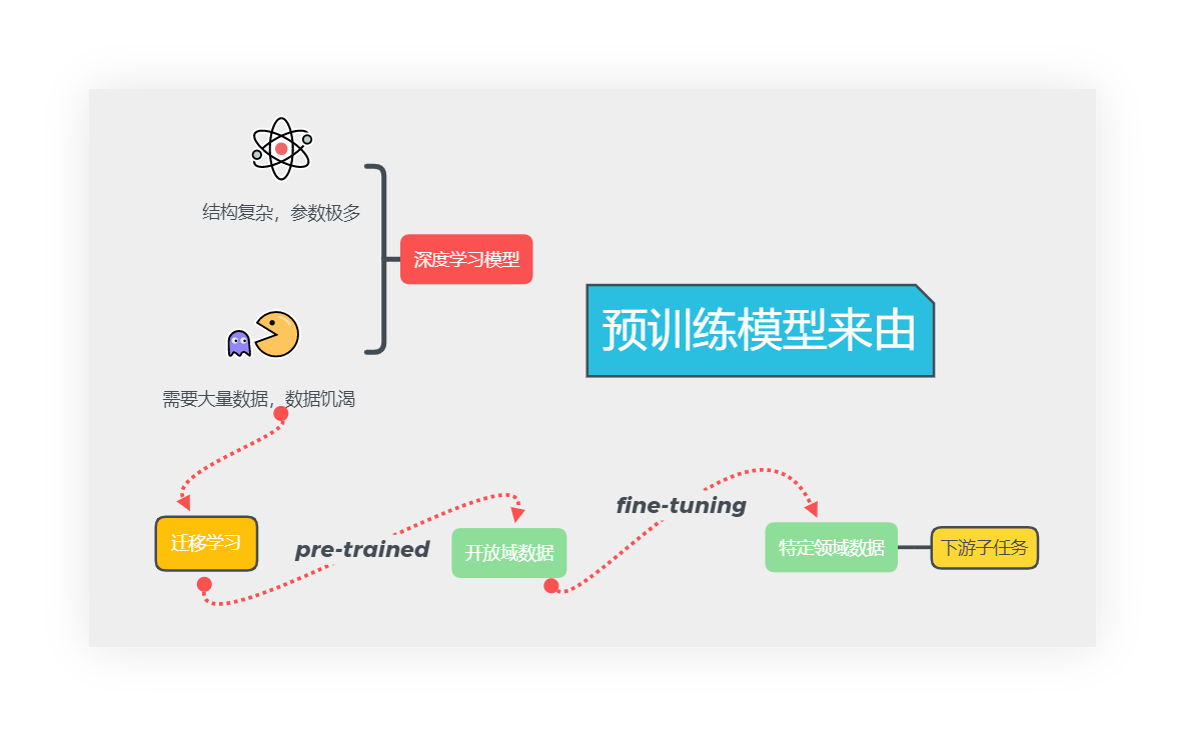
深度学习模型以结构复杂,参数极多作为标志性特征,复杂的结构允许模型学到更加复杂的特征结构,同时会使得人难以推断模型运算的结果,模型也缺少解释性。
预训练模型在CV领域起步很早,成熟的大模型也很多,但是语言领域的标注成本很高,预训练的方式,对标注数据需求巨大,Bengio的语言模型思想采用自监督的上下文开启了预训练的大门,但是直到后来的ELMO之前,使用的都是预训练词向量也就是特征迁移方法,这种方式固然便捷,但是忽视了上下文关联的语境信息。
使用rnn预训练的上下文相关向量表示模型,通过RNN的递归性质使得经过模型调整的表示向量存在依存关系。但是语言模型的大小和深度存在限制,原因就是RNN无法解决捕获上下文信息和并行化计算之间的矛盾,RNN的生成网络计算成本过高,因为可以将rnn的递归看作是时序上的深度网络,同时不存在可靠的信息同时因为独特的架构表示信息很容易消失,在反向传播过程中深层模型很难学习。
情况1: 无标记数据远比有标记数据多出无数倍
情况2: 人工标记的成本很高,也不一定是百分百准确,有些标注必须有领域专家参与,人 工难以标记海量数据,使用人工标注的方式注定是难以解决预训练模型需要的海量语料。
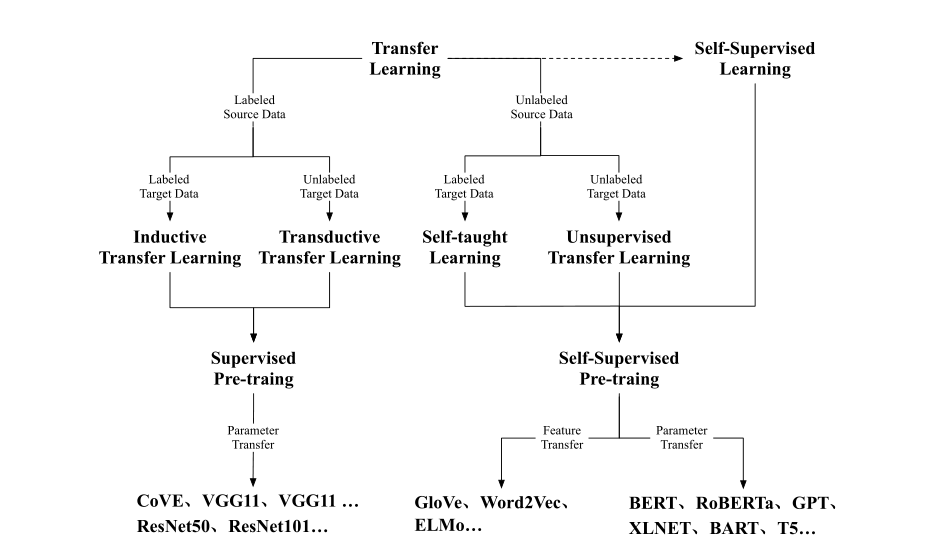
image-20210619135332267
从上图可以看到CV领域的基石是监督预训练,而自监督是自然语言领域对大规模语料进行预训练的根基,因为文本领域的标注远比图像更加复杂,大规模文本文本标注成本是及其高昂的。
自监督学习,通过上下文来预测一个单词,这种形式利用了文本中的依存关联,是文本相对独特的优势,语言模型训练无需标注,数据压力小的优势显著,可以看到监督预训练除了来源于机器翻译应用的COVE其他的自然语言处理的预训练模型是来源于自训练的语言模型。
image-20210619142836684
而RNN时代制约预训练语言模型的关键因素是,RNN难以构建比较深的网络,研究人员实验超过12层的RNN训练难度难以承受,而这个层数对比CNN网络的上百层来说实在是令人沮丧,同时RNN不仅是计算成本高,而且必须采用截断计算(实际传递的时序状态是存在长度限制),LSTM改进将显式限制转化为隐式,采用门结构来控制细胞状态,但是对于长距离依赖表示信息的学习依旧是艰难无比.
Transformers 架构通过多头自注意力绕开递归机制,使得模型可以并行化处理数据,这一点就是它能够构建最够大的深层模型的基础,研究人员发现堆叠编码器或者解码器部分构成的模型仍旧有很好的学习能力,这一表现就是开启money model时代的启示。后边的这类预训练模型无一不是烧钱巨兽。
自监督学习和transformer架构是推开自然语言预训练模型的两只手,缺一不可,自监督学习使得语言模型有行之有效的建模方式,transformer使得预训练模型能够向更深更大发展,
语言建模一直是有两个趋势,AR和AE也就是自回归模型和自编码模型,因为架构的差异两种模型擅长不同的部分,Bert在自然语言理解领域独占鳌头,所有SOTA模型都是从此派生出来的。GPT系列体型庞大,堪称巨兽,在文本生成领域独领风骚,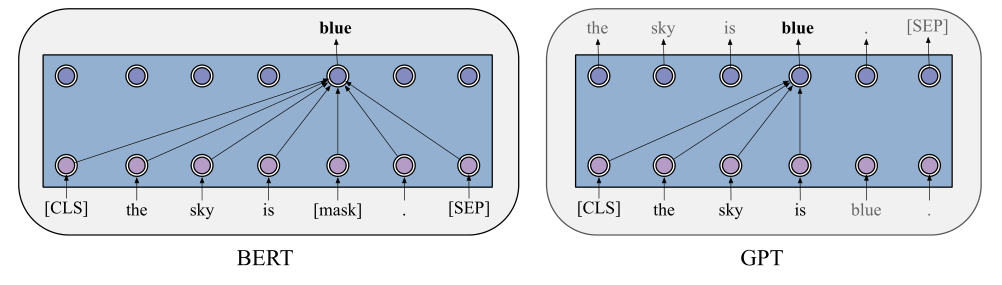
image-20210619155114138
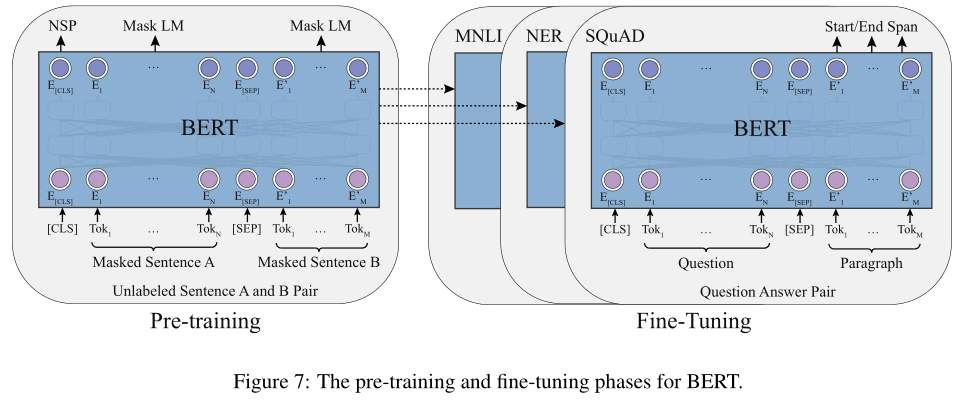
image-20210619155436001
Bert模型存在一些痛点,第一个就是源数据域和目标域存在预训练和精调过程中的一个巨大差异,[Mask]消失了,因为精调过程中可是不存在,这点会导致比较严重的性能损失,一种解决办法是使用promte tunung 也就是模仿预训练过程中的方式构造提示模板,使得模型预测Mask作为结果:
- 例子:[CLS]标题为;推进人民币国际化需要外汇期货 的新闻[SEP]应该是[Mask]新闻。
- 通过[Mask]作为预测,这种方式能够使得模型在少量数据情况下启动,极端情况下可以使用几十条数据用来
- 另一种迁移方式,就是在目标域的语料上以语言模型的形式来训练一轮,在此基础上在结合任务模型再次训练一轮。
- 另外 一个核心技术NSP也就是预测一个句子是不是当前句子的下一个句子。
- 后续的一些改进有ALBert和RoBerta的Bert变体,RoBerta论文中指出NSP是无用设计😢,在Bert基础继续精细调参,使用动态掩码,以15%的几率Mask十次。RoBerta的精细调参使得模型性能一度领先,XLnet是在AR基础上加上PLM做到类似Bert的双向编码效果(这部分没看,论文里面讲的),另外还有一些
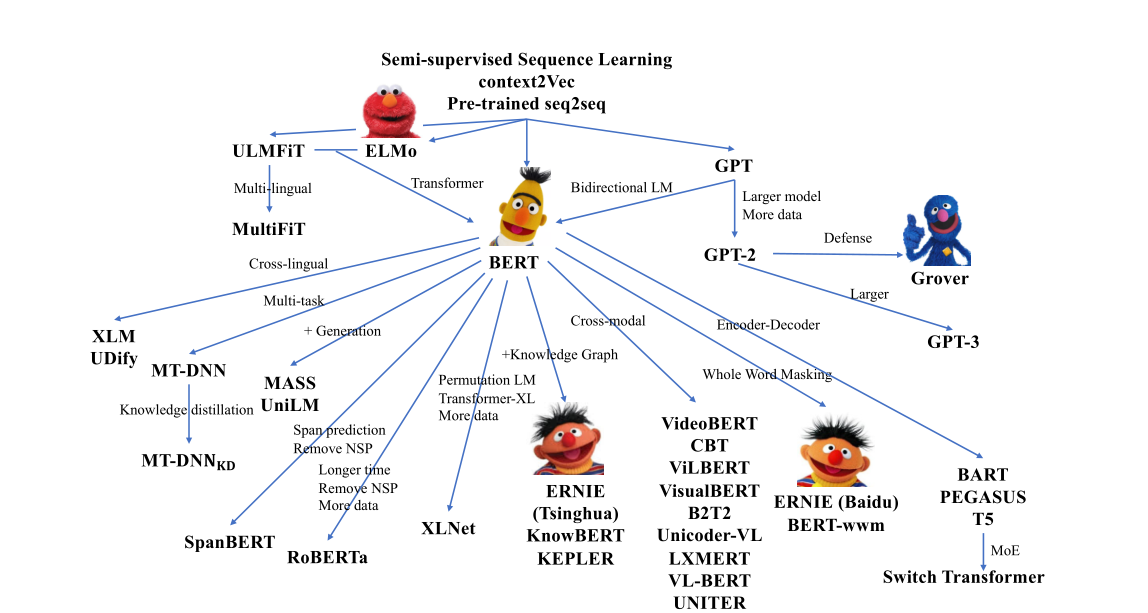
AE和AR模型的结合:
于是就有人想着这划分两个模型,但是实际任务又没办法划成两种任务,因为不能理解语言就不能很好的生成语言,就提出了UNiLM统一语言模型,在一个框架中统一单向双向,序列到序列,模型在生成性问答和抽象式摘要上表现很好,另外的XLnet使用预训练中排列token的顺序来实现对token的预测,同时将GPT的单向生成和Bert的双向理解结合起来,后续的改进是MPNet,修正了XLNet在预训练中不知道句子长度的问题,其实最近的一些研究表明GPT系列甚至在语言理解上面有比Bert更好的性能,这参数当然就恐怖了。
基于掩码策略的改进有MASS模型,采用掩码预测策略改进编码器解码器结构,T5对Mask中存在的变长序列统一使用一个掩码来预测,最近提出的GLM使用一种可变长掩码机制实现了统一模型的最佳性能基准,模型采用的是一种二维掩码来确定掩码长度的策略。BART用对原序列进行破坏来代替原本的掩码机制(😄掩码做的还不够),但是这一思路的统一模型比起单个编码器或者解码器结构的相比来说,参数更多,这带来的性能提升是存疑的。
一些研究者研究知识结合得语言模型,工作记忆和长期记忆也是语言模型结合的重点,工作记忆更多的是一种短程语义关系特征信息。特定领域长期记忆和语言模型的结合又被称作是知识增强,这方面存在三种方式:
- 通过特定任务让模型学到任务中存在的知识
- 对文本语料进行张量化(这里思想其实接近预训练词向量)
- 对知识图谱进行向量化(知识图谱嵌入)现在也是比较热门的领域(图表示)
- 显示知识增强的思想就是下边两种,也就是将文本中对应的实体或者行为替换为解释更加明确的嵌入知识,例如刑法条文《第一百二十三条》换成意义更强的对应条文的嵌入
Bert掩码改进策略的变体模型数量众多,但是主要是从这些方面做出努力,Mask的对象更多,从词到实体,收益依赖,再到对话,语言,乃至任务。另一种就是将掩码长度也纳入预测对象,代表性的SpanBert和ERNIE和NEZHA都有类似想法,哈工大的ELECTRA提出RTD替换token检测,生成器替换token,鉴别器预测替换的令牌是哪个,虽然这个理论上是一个更难同时更有效率的任务,但是该模型只在和tiny-Bert上有优势,虽然对数据要求比较少。
另一种改进就是让模型学习语言中存在的一种共同语义,通过在多语言训练一个模型可以在基准测试上做的更好,但是使用LSTM的多语言任务基本上只能在训练的特定任务上使用,很难进行推广,在Bert时代mBert和XLM-R通过多语言掩码语言模型证明了Bert有能力学习多语言语义,但是存在一个问题,多语言模型对于平行语料的要求是比较高的,不管是基于翻译语言模型的TLM模式还是采用CLWR对照语言单词嵌入,以及CLPC这种多语言句子配对方法,使得对语料的要求比较高。
另外就是一些多模态的Bert模型,这些模型扩展了Bert框架,将视觉和语言的关系作为建模的主题,这些多模态模型感觉应用方面还是大有作为的。这一系列从ViBert和LXMERT以及后来的VisualBert以及VL-Bert,ImageBert同样也是,应用的领域主要是这四个方面:视觉问答,基于标题的图像检索,定位推理表达(例如推测照片中这个人站在标志物的哪个地方),多模态验证技术。
这里提一下目前最强的文本图像生成多模态模型,是DALLE和BAAI。
这里就是一些模型训练的一些技巧
另外在训练模型时可以通过对参数的位数进行量化缩减来减少模型的内存占用,从全精度32位浮点数,半精度16位浮点数表示,混合精度浮点数表示(之所以要混合就是浮点数截断或者溢出,会使得模型训练时不稳定)。另外为了计算梯度保存的激活状态其实也是冗余的,一些研究人员提出了梯度检查点技术,使得内存只保留一部分的激活状态,如果方向传播的时候需要这部分激活状态,那就从检查点处重新计算。这种方式和旷视的MegEngine的动态计算图现存优化十分类似。
另外的一些有效的训练方法:上面说的RTD是一个很高效的改进策略,另外的训练方法改进是通过反向传播重要性或者梯度来选择要掩盖的token,用来加速模型训练(原本的token是完全随机的,也就是不加区分得掩盖token,但是对不同类型的token识别的难度是不一样的,识别简单的token学习程度够了但是复杂可能还没学习好,这时候对数据还是得进一步扩增,另外Roberta是将这个过程重复多次来利用一个数据)
第三个是学习率相关的问题,研究表明在训练初期线性增强学习率可以解决冷启动(最初几轮梯度下降比较慢),在模型比较深的情况下自适应使用不同的学习率能够加快模型收敛速度
第四个就是对注意力机制计算的改进,主要是自注意力计算复杂度还是比较大的,例如对一个固定大小序列计算自注意力,而不是整个序列长度,或者使用可学习的参数将token切分为多个块更加合适,另一种就是使用全局注意力挑选token,然后进行后续计算。
第五个就是压缩模型 ,预训练模型可以在一些相似的单元之间共享参数,这种技术在一定程度上能够防止大模型过拟合,还可以修剪模型的结构,将一些无用的部分减除,一些研究会在训练中随机丢掉一些网络层,以便得到比预设更浅的网络,另一些人发现多头注意只需要一部分就能实现良好性能,选择剪除注意力头。
第六个 知识蒸馏,使用教师学生方式教授一个浅的模型来学习更深更强的模型的输出概率和隐藏状态和注意力矩阵,但是这一般比普通的预训练模型要有更长的训练时长。
后面这篇文章讲了未来的一些研究热点应该是:
- 模型体系结构改进(自回归,自编码。统一)
- 多语言多模态(更加通用的抽象化知识)
- 计算效率
- 边缘学习
- 领域预训练模型 (SCIBert和BioBert以及最近的simcBert)
- 学习认知和知识学习

若有收获,就点个赞吧
0 人点赞
