Glove : 词表示的全局向量
论文的起因是Jeffery等人研究词相似任务时发现由背景词预测中心词的条件概率的比值能够很好体现词性的词性。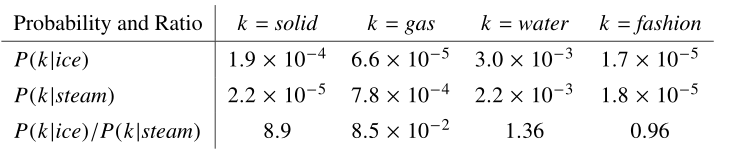
上图就是用条件概率的比率来表示词的相似性关系,冰和蒸汽的共现词在整个语料中的共现概率,和他们共现概率的比率是能够体现出两个词的差异,‘冰’相比‘蒸汽’,和固体的相关程度是更高的,和蒸汽的相关程度上是比较低的。
Jeffery认为这一特点表明了共现概率的比率是词向量表示的起始点。现在简单讲一讲他是怎么构建一个公式,说实话这里几乎没有严谨的推导过程,感觉上就像是为了验证一个假设,一步步构造一个觉得应该是有效的公式来。
同时这里面使用两个向量来表示一个共现概率的比值,其中词向量包含是要学习的词表示方式,是稀疏的上下文词向量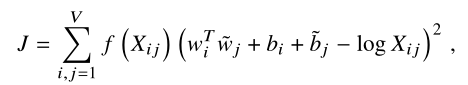
是语料库中对应的的上下文中单词j的出现次数,所以也就是。是单词i的上下文内的其他词的共现概率。
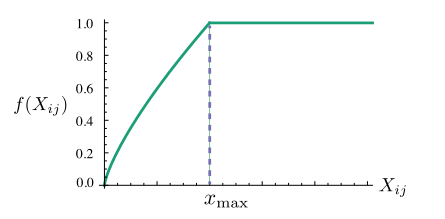
这里加上一个f()是用来对上下文中的词向量来做按照词频的加权调整,可以看到这里其实做了一个截断处理,所以过于高频的不表意词汇的权值相应的也被截断了。这样能够保证共享信息里面的高频词会对语义产生比较大的影响,低频词相对的影响是比较低的。
后面括号里面的式子是对词i的共现词概率的对数化形式, 所以这个式子其实是建立在整个共现矩阵X上面的,引入的是为了保证上式左右保证对称性,也就是词的先后顺序不影响计算结果。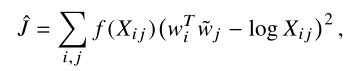
作者通过一些推理论证了原先的窗口模型的代价估计是和现在这个在共现矩阵上的差别不大,现在还对词频按照截断加权的方式进行了调整。
首先大家得理解一个东西他这个全局共现矩阵听起来像是整个语料尺度上的直接共现,其实不是这样,因为这样的共现矩阵每一行的海明距离一定是非常小的,也就是说没什么差异信息被统计出来了,毕竟统计的共现范围太大,包含了太多的噪声数据。同时语言之间的关系和相对位置存在一定关系,距离遥远的词显然是难以包含当前词的分布式关系,因为说不定都不是一个文档里面的,所以它这个其实也是加窗的共现矩阵。通过对加窗背景词共现概率的统计作为一个矩阵,同时作者还认为离输入词越近的词的重要性更加重要,同时距离越远的词占统计权重的比例也就是越小。
现在将以前的W2V的概率从对应预测词的概率,变为是是预测背景词共现概率。也就是说首先统计全词表的共现矩阵学习的两个向量表示被模型一步步更新,使得他们的的积接近于带有偏置的对数共现次数,这里模型的整个流程应该是将独热码或者是词表索引形式的输入词形式,经过对第一个权重矩阵中行的复制(也就是输入词对应的权重向量行),得出的词向量其实就是(维度是n x 1)经过转置之后与第二个矩阵的每一列做向量积,然后对这个值和我们根据语料获得的统计矩阵中的共现次数的对数值进行上述的加权均方误差计算。
由此看出了这个算法的一个好处就是没有使用神经网络,也没有使用什么softmax,这样模型训练的复杂度很低,也就是计算整个语料库的共现矩阵。这个模型利用了全局的共现信息,同时在最终的词表示向量其实使用输入向量和输出向量的和作为最终向量,因为训练结束之后两个向量本来理论上是应该是一样的,但是两者初始化是随机的,所以这里两个向量可以看做是方差不同,相加之后对于向量来说就是平均了高方差,是的向量表征的泛化性能更加好。

若有收获,就点个赞吧
0 人点赞
