NNLM神经网络语言模型
要说道词向量总要谈及这篇论文的,虽然这篇论文目标不是学习词的分布式表示。
这篇论文目标是要学习语言中单词序列的联合概率函数,也就是通过上文来生成下一个单词的概率函数,来得到一个自回归生成的最大似然模型。
这篇文章为什么能够和词的分布式表示有关联,就是这个语言模型通过学习词的分布式表示和整个单词序列的表示来获得单词序列生成的条件概率,这种使用神经网络在未标注语料上学习词的分布式表示的方式是相当具有启发性的,后序的几个关键模型也都是做出了启发性的改进。
就我个人来说这个模型的研究思路是相当超越时代的,不仅提出了一种使用神经网络来训练词向量的方式,同时也间接表示了单词序列可以通过对单词序列的线性加权和来表示。同时这个03年提出的语言模型,也指导了十年后2013年发表的W2V的论文1,‘Efficient Estimation of Word Representations in Vector Space’,这里将词分布矩阵的维度转化为一个超参数,因为文本中词汇的相关性会随着位置衰减,同时也提出了只通过文档的局部表示,也就是句子的一部分来预测下一个词的条件生成概率,神经网络在词向量表示的任务上超出了经典的N-gram模型。
对于一个统计语言模型来说训练语料是永远不嫌多的,越多的训练数据会有越高的性能,但是数据稀疏问题也是所有统计方法的困扰,为了提高准确度,需要更多的语料,更多的语料会带来更多的词汇,稀疏的词汇矩阵形式使得矩阵的维度十分巨大,同时测试语料中会有未出现在训练语料中的词汇,为了减少这类未出现词,就得在更加大的语料数据上进行训练,如果不寻求一种可以用低秩矩阵表示原始矩阵的方式,词表示在但是就是一个无解的怪圈。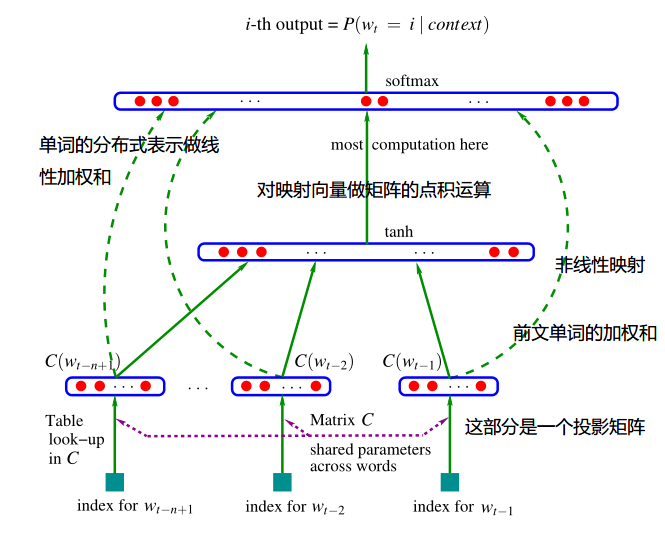
现在来看一看这个经典的架构,这个模型的图我写了一些注释,理论上是一个N-gram的词表示和对应的序列表示(N-gram词的分布式加权和的非线性映射作为序列表示)的线性计算得到下一个位置词的全词生成概率(也就是说这个概率是对整个词表的词进行计算的),
$x = (C(W{t-1}),C(W{t-2}),….,C(W{t-n+1})) —— (1)\ \ y = b +Wx+U tanh (d+HX) ——— (2)\ \ \hat{P}(W_t \mid W{t-1},…W{t-n+1})=\frac{e^{y{w_t}}}{\sum_i e^y_i} ——-(3)$
这就是NNLM的数学模型,目标函数是对数化的条件概率加上正则化项,也就是通过不断更新权重参数来使得目标函数最大化,这个模型提出了通过神经网络来学习一种被降维的分布表示。但是这个模型问题也是很明显:
神经网络语言模型在那个算力缺乏的年代,对超大长度的语料库上进行softmax的规范因子计算花费的算力实在是很大,假设N元模型考虑N个词作为输入,投影矩阵的维度假设被压缩做D维,所以计算y的复杂度 O = N x D + N x D x H + H x V, 这里面之所以有两个N x D的子式,是因为对输入N个词的投影向量做了两次线性计算,第一个子式是 (2)式里面的,也就是简单的词分布表示。
第二部分显然就是对整个序列进行隐层计算(这里隐层共有H个神经元),最后一部分就是(2)中的部分和softmax计算,这个部分的计算需求几乎是爆炸性的。
另一个原因就是使用隐藏层来更新词的分布矩阵是存在一个最优解的,关键问题在于如何在一个维度极其高的向量空间中获得这个最优解。使用梯度下降计算得到的大概率是局部最优解。
所以原作者是如何解决这个问题的了,算力量级不够就通过数量来凑,作者通过并行计算来解决这个问题,在40CPU上训练5轮需要3周,使用SGD要10-20轮才会收敛,也就是说最糟糕的情况不调参可能需要3个月才能得到收敛的结果,虽然一部分因素是但是算力的限制,也同样说明这个模型要是想取得足够好的性能是不切实际的,当时的大型共享内存并行计算机对于这位Yoshua Bengio 蒙特利尔大学教授(现在的深度学习泰斗,Yoshua,Hinton,LeCun)来说也是十分昂贵的,甚至使得他没做太多的实验来搜索超参数。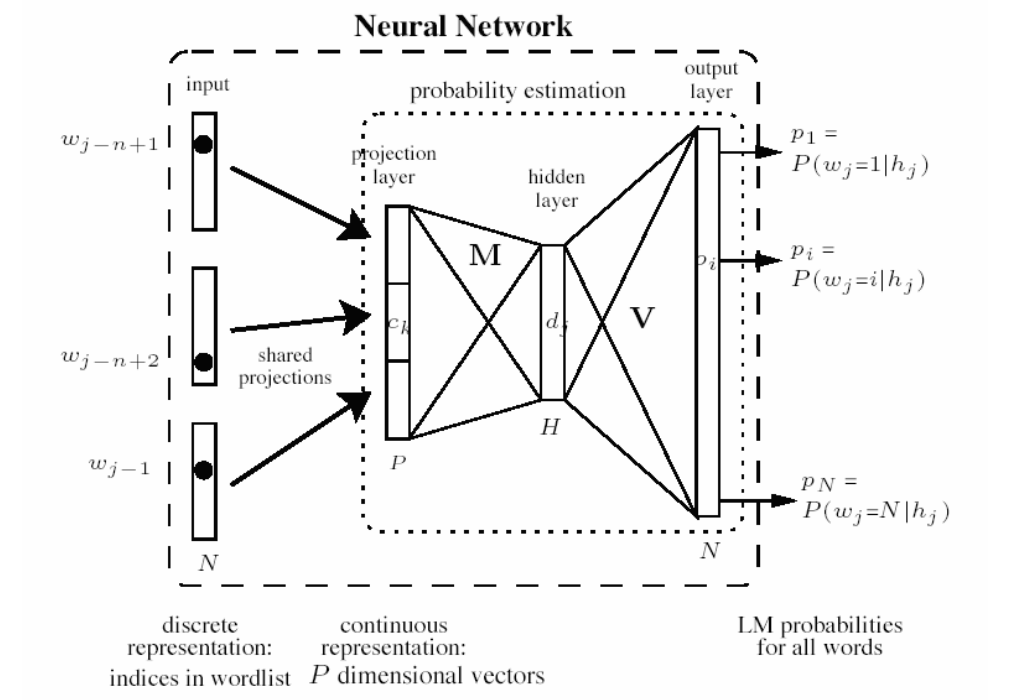
上图是Mikolov在2007的博士论文中对早期的NNLM简化后的模型结构:简单的来说就是将原本的投影矩阵变成一个共享的投影层,到了2013年的论文里面这个投影层彻底变成一个权重矩阵还被叫做输入矩阵(这个矩阵的每一行就是我们要用的词向量)。所以说这里其实就是已经有部分W2C的架构。

若有收获,就点个赞吧
0 人点赞
