常用的scoring参数的取值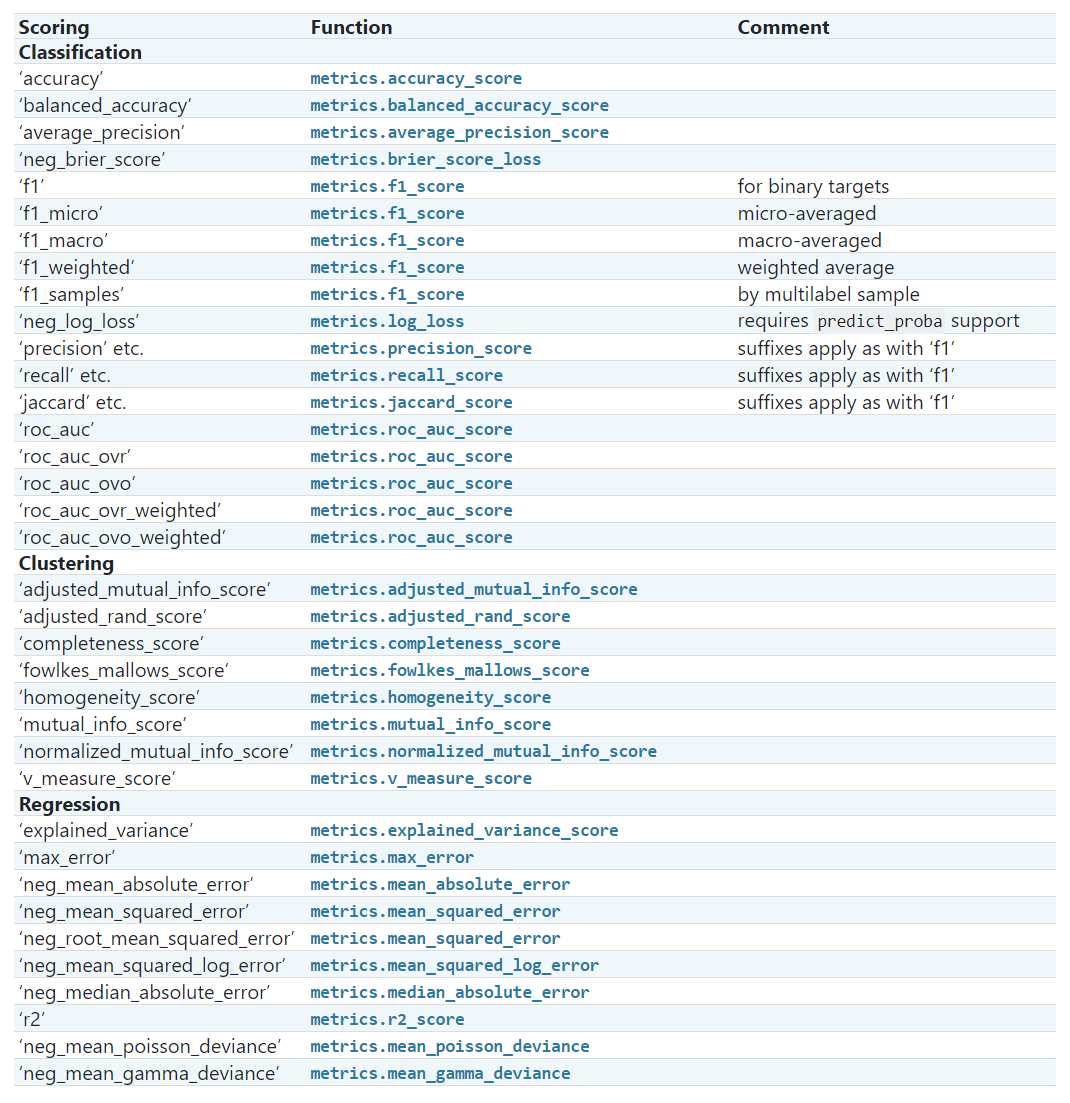
分类 :
| “accuracy”指的分类正确的比例 | “precision”指的是预测出正样本的比例 | “recall”被识别出来的正类比例 |
|---|---|---|
| F1=2/(1/精度+1/召回率) | “roc_au”指的是 | |
| max_error:最大误差 | “neg_m_s_error”:mse | “neg_m_a_e”:平均绝对 |
这些参数的结果也可以通过SKlearn.metrics之中的函数进行返回
逻辑回归:
逻辑回归可以设置求解器,一般来说“liblinear”是通过(oVrest)即一对多来实现多类划分的,
lbfgs适合于较小一些的数据集,过大的数据集和较多的特征会影响其效果,使用的一种拟牛顿法,使用损失函数二阶导数矩阵来优化损失函数。
sag是随机平均梯度下降,是梯度下降算法的一种,所以在较大数据集上适合使用,
saga是“sag”的变种,可以引入L1正则化选项。
ROC曲线:
roc曲线只能使用于二分类问题:
使用如下:
scores = clf.predict_proba(x_test)[:,1]
fpr,tpr,thresholds = roc_curve(y_test,scores)
plt.plot(fpr,tpr,linewidth=2,label=’…’)
plt.plot([0,1],[0,1],’k—)
plt.axis([0,1,0,1])
plt.show()
随机森林:
随机森林重要的参数有三个:
- max_features :随机生成时选取特征的最大数量:
- n_estimators:生成随机决策树的数量。
- min_sample_leaf:生成树的叶子最少要对应多少样本:
决策树:
决策树泛化问题通常是采用剪枝操作来进行实现:
预剪枝就是在划分的过程中检测划分前后验证精度有无下降,采用的是贪心策略,要是对泛化没有效益不进行展开
缺点:预剪枝给决策树带来了更多的欠拟合风险。
后剪枝就是对训练集中生成的一棵完整决策树,对其进行剪枝预测,若是剪枝(将子树变成叶节点)后能带来更多的泛化收益就进行剪枝。后剪枝会带来更多的资源开销,但是欠拟合风险很小,因为它会保留更多的分支。
神经网络:
- 通常要对原始数据进行预处理,以便转换成张量,单词序列可以使用二进制编码。但也有其他编码方式;
- relu的激活Dense层能够解决很多问题;
- 二分类问题“binary_crossentropy”,只有一类输出的分类器可以使用sigimoid标量输出。
- rmsprop 和Adam是足够好的选择
- 神经网络也会过拟合,一定要一直监控在训练集之外的数据上的性能。
- 对于单标签,多分类的问题使用softmax激活很是合适,多分类适合分类交叉熵,能够将网络输出的概率与真实分布之间的概率距离最小化。
- 处理多分类问题标签的方法有两种。
- 通过分类标签(热编码),然后使用分类交叉熵做损失函数。
- 将标签编码成整数,然后使用稀疏分类交叉熵做损失函数。
- 较多的分类输出避免使用较小的中间层,容易造成信息瓶颈。
- 神经网络层数过多容易导致过拟合
- 数据量较少时k折交叉验证是很好的方法。
数据预处理过程:
- 向量化:输入和label都要是张量
- 标准化:特征必须在同样尺度内。
- 处理缺失值:为0的缺失值是安全的,如果测试数据中是存在缺失值的话,可以复制训练集一部分制造缺失值。
 是神经网络进度提升方式。
是神经网络进度提升方式。
启发式算法 是人们基于经验和直观构造的算法,一般是仿自然的算法为主:
模拟退火,遗传算法,列表搜索,进化规划,进化策略,蚁群算法,粒子群算法。
类别不平衡 处理:
有两种策略:
欠采样:去除一些较多的例子,实现各类别之间比例比较平衡。
过采样:对较少的类别进行添加,实现类别之间比例的平衡。
缺失值处理:
1.丢弃缺失值:对小样本,或者缺失样本数量较多的数据集不适合,
2.使用插值:用对应属性特征的均值来替代。
BP**神经网络:
误差逆向传播网络:实现梯度反向传播。
均值:是衡量类别之间差距的,也可以用来衡量精度,
方差:是衡量类之间数据分布差距的,也就是类间差异。
神经网络的正则化会有导致误差增大的风险。
drop out 会很好的防止神经网络的过拟合。
批量标准化 BN是在部分数据集能够提高泛化效益的技术。
其他类型的神经网络:
RBF 就是激活函数采用径向基函数的神经网络,
 是高斯径向基函数,也是高斯核的函数,优点是能够以任意精度逼近连续函数。
是高斯径向基函数,也是高斯核的函数,优点是能够以任意精度逼近连续函数。
ART就是采用一种无监督的竞争型学习方法的神经网络,网络输出神经元能够相互竞争,每一时刻仅有一个竞争获胜的神经元激活,采用的是“赢家通吃,败者食尘”的策略。优点是适用于增量学习和在线学习。
SOM自组织映射网络是一种竞争学习型的无监督神经网络,能将高维输入数据映射到低维度中
级联相关网络是一种结构自适应网络的一种,在开始训练的时候,新的神经网络从只有输入输出层开始加入新的隐藏层神经元,新的神经元引入时输入端权重是冻结的,与一般的前馈神经网络相比级联神经网络无需设定好网络层数,神经元数目,而且训练速度比较快,但是在数据较小的时候容易陷入过拟合。
ELMAN递归神经网络,允许网络中出现环形结构,从而可以让一些神经元的反馈作为输出信号,这样使得网络在t时刻的输出状态不仅与t时刻的输入有关,还与t-1时刻的网络状态有关,使用于处理时间有关的动态变化,
平衡机:平衡机就是基于网络能量的一种模型。
pandas之中显示对齐:使用中文特征名后对齐还是比较困难
可以使用pd.set_option(“display.unicode.east_asian_width”)
**

若有收获,就点个赞吧
0 人点赞
