Lawformer解读
这个工作是清华的人工智能研究所做的,发表于AI Open上,清华和武大在法律ai上面深耕很久了我找到的最早的论文可以追溯到
这个刊物是去年创办的,主编是清华的唐杰,副主编是刘知远,和人民大学的张静(好像是唐杰的学生),主要是收录人工智能和相关应用方面的文章。
征稿主题是:
- 深度学习与表征学习
- 图论与图挖掘
- 知识表示、推理和逻辑
- 机器学习和数据挖掘
- 知识图及其应用
- 基于Agent和多Agent系统
- 网络和基于知识的信息系统
- 自然语言处理
- 图像处理与分析
- 基于大脑的学习:
- 人脑相关健康/疾病/社会行为的热门主题
- 大脑连通性和网络建模
- 脑智能范式
- 神经信息学
- 学习和记忆
- 认知与行为
- 卫生数据分析和统计
刊物为自监督学习 知识图谱 图神经网络 强化学习 设置了专门板块。
论文审稿人是从清华唐杰教授团队的Aminer系统里面选取的。
这个系统比较好用,推荐的一些论文还是比较精确的,就是近期论文的推荐权重比较低。
近年来投稿团队还是比较强的,感觉论文质量比较好。
现在开始说论文
这项工作就是基于法律方面任务的相关特点:
近些年(自2018年起)基于预训练语言模型的法律AI研究受到高度关注,也就是投稿比较多,用的最多的也就是Bert系列作为基础的编码器。
但是法律方面涉及的任务文本都是比较长的Bert系列相对于这方面的任务来说还是不能直接处理,因为Bert系列的常用变体是512的token长度,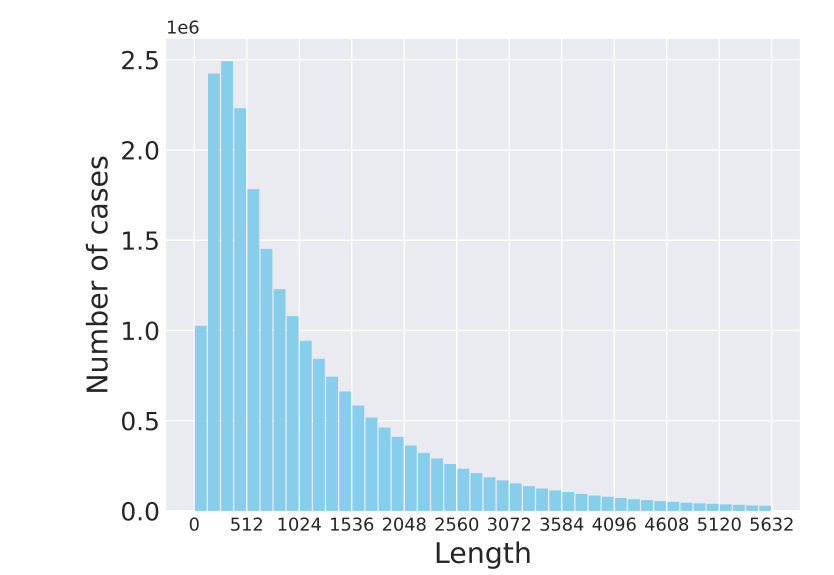
image-20210820152328953
可以看看这个图,虽然文本长度为512左右的案件是最多的,但是还是有64%以上的案件长度是超出这个范围的。
所以为了处理法律领域常见的长文本的,就基于Longformer 在法律语料上预训练了一个语言模型。
Longformer 语言模型
这项工作是美国的艾伦ai研究所的工作:Allen 研究所在NLP领域有117篇论文,质量都很高
很出名的成果有ELMO和SpanBert
因为Transformer 架构的自注意力计算复杂度与序列长度的平方成正比,也就是说bert系列的模型在处理长文本时,计算成本会很高,为了实现长文本的自注意力计算,得使得自注意力计算关于输入文本的复杂度成线性关系,也就是O(n),这样有几千个token的文本也能够用Transformer来处理,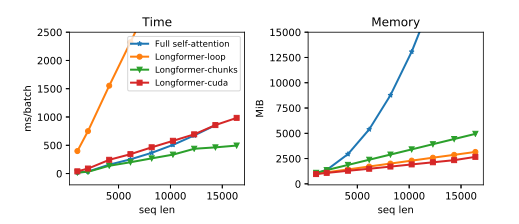
可以看到Longformer内存占用少很多,综合最优的是 Longformer-chunks
下面是三种文本处理的算子的计算复杂度:
对于输入的向量序列来说进行一次卷积计算复杂度是O(nkd)n 是序列长度 k是卷积核尺寸 d是维度(这里默认是做了padding,维持输入输出维度不变),相似的为了维持输入输出尺寸不变,得用d个卷积核也就是d个通道,所以最终卷积是所以复杂度计算如上(这里统一不论激活函数)。
对于RNN计算的复杂度主要是在门上,最简单的RNN是:
St = f(U\cdot X_t + W\cdot S{t-1})\ O_t = g(V\cdot S_t)\qquad\text{(1)}
隐藏状态计算的复杂度是 输出门是所以整体的复杂度还是
对于transformer架构:
默认使用多头注意力 注意力头设为h,对输入向量使用三个投影矩阵,这点可以看做对输入向量做了多个embedding,q,k,v的维度是k/h,d>k,n个d维向量投影的计算复杂度是,因为k
image-20210820195437600
一些简单的使用bert来处理长序列的做法是,一种是截断文本,常用在文本分类任务里面的技巧,这种容易丢失截断文本里面的信息,另一种将一个长文本切分做多个短文本(小于或等于512token)来处理,但是容易丢失跨上下文的信息,
这些都是用于解决长文本理解的Transformer改进,注意力矩阵方面,使用稀疏方式能够节省能存,上面的大部分改进工作都是在研究如何改进计算效率上,也只是对比了语言建模的性能,但是很少有在文档级语料上做下游的nlp任务,同时Adaptive Span 和 Compressive不适合使用roberta预训练参数微调的范式。
Longformer 使用加窗的局部注意力来限制长文本注意力的计算成本,加窗之后计算量就是线性的,任务全局注意力能够构建整个序列的表征,
现在介绍Longformer的集中注意力模式:
- 滑窗模式:这种滑窗注意力只是计算token周围窗口内的注意力,同时滑窗注意力有卷积的特点,堆叠的多个层会产生一个较大的感受野,计算复杂度
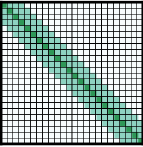
- 扩展滑窗:这种思路类似于空洞卷积又叫扩展卷积,卷积中间有间隙,能够在相同计算量下有更大的感受野,对多个注意力头可以配置不同的滑窗模式,一些是普通的滑窗注意力模式,这些注意力头会关注局部注意力,一些是不同扩张的滑窗注意力,能够关注更长的上下文,可以提高模型性能。

- 对特定令牌使用全局注意力模式,因为滑窗注意力不能学习特定任务需要的表征,所以在预先设置的token处计算全局注意力,例如[CLS]处学习整个序列的表示,问答任务里对所有问题标记计算全局注意力。
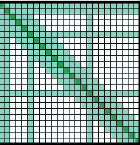
Longformer实现因为滑窗注意力的计算需要一种带状矩阵乘法,现有的深度学习库都是不支持这种矩阵乘法,所以使用了三种实现:
pytorch里面的loop方法,这种方式很省内存但是速度非常慢
chunks方式不能支持扩展 也就是不能改写,cuda方式是使用TVM实现的高度优化自定义计算内核。
注意力模式的应用,在处理自回归语言建模任务时仅仅使用滑窗注意力,但是底层使用比较小的窗口(不用扩张滑窗),较高层使用比较大的窗口(仅仅在几个头上使用扩张卷积),这样同时保证了性能和效率。
模型训练技巧:
因为这种局部注意的模式需要大量的梯度更新,所以作者在训练早期从一个比较小的窗口来更新,随着训练进行逐步增加注意力窗口大小和文本序列的长度,并且将学习速率减半,也就是先从一个比较简单的模型开始训练起,在前一个模型的基础上训练更加复杂的模型。最后阶段作者在5个序列长度上对模型进行了训练,序列长度从2048到23040.并且在一个32256长度的文本上进行了评估。
模型使用的滑窗大小是512(这里没使用扩张卷积,因为差异性比较大可能需要对这类模型进行重新训练),位置编码使用roberta的预训练编码,这样在窗口边界之外的位置都能保留很好的上下文信息,在利用roberta进行微调之后模型能够很快收敛,作者对模型按照序列长度,64的批次大小进行了6w5k次梯度更新,最大的学习速率是线性预热500步,然后使用三次幂的多项式衰减,其他的超参数和Roberta相同
模型在enwik8上进行了性能评估,要超出Transformer-XL,但是性能和Sparse Transformer差不多,和两倍参数的最新模型相比要稍微差一点,

这张表显示了使用随机初始化的位置编码和直接复制Roberta的位置编码的模型性能差异,经过2k步迭代更新后新模型已经超出了原始的Roberta,训练63k步带来的性能提升并不是很高,但是成本很高。最后一行表明在完全冻结除了位置编码之外的Roberta的模型权重的时候经过训练的位置编码比直接复制使用更加好,但是要比训练全部参数要差。
使用Longformer改进的Roberta模型在三个任务的六个数据集上取得更好的性能,尤其对于需要处理长文本序列的任务,性能提升是比较明显的,实现结果发现对于指代消解任务来说因为任意两个指代的距离都是比较小的,所以只使用处理较小文本长度的基线模型就能够取得很好的性能。
这篇文章最大收获就是可以使用一些改进的transformer结构对一些基于transformer的mlm训练或者针对特定任务预训练的模型进行替换来提升性能,
回到Lawformer 使用Longformer架构的Roberta-wwm -ext全词掩码在法律领域的中文长文本上进行掩码语言建模预训练,
下图是LawCorpus上的Longformer的注意力机制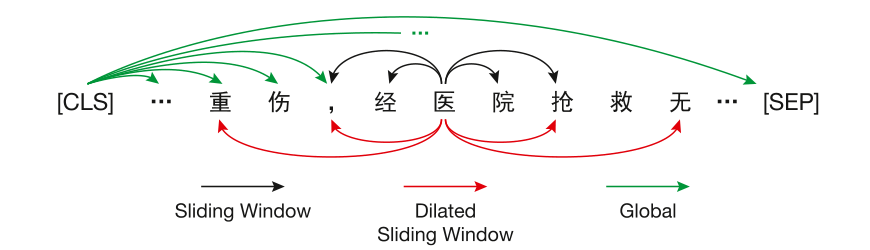
这里可以扩展滑窗注意力模式可以忽略不计,原因和上一节说的一样,原始的Roberta里面的注意力头计算的模型和扩展卷积差异性太大。
训练之后的模型和三个基线模型相对比:
Bert-base-chinese 、 Roberta-wwm-ext、Legal RoBERTa 这个是在法律语料上预训练的Roberta-wwm-ext模型。
这三个基线模型依次是 中文Bert 使用全词掩码的Roberta 和进行了领域预训练的模型。
作者在中国裁判文书网上收集了几千万份裁判文书,然后剔除了案情描述小于50token的文档,这点我猜测是通过设计好的正则提取的案情描述的分词长度来进行筛选。从18年的几百万份刑事文书的案情描述就是清华大学通过正则抽取的,质量相当不错,前期有技术积累。
这里可以看到筛选之后的刑事文书有540w条以上,平均文本长度是96k个token 总大小是17G,语料相当大,
作者按照Longformer的办法在Roberta-wwm-ext的基础上以5x的学习率进行训练,序列长度是4096个token是Roberta的八倍长度,batch size是32,训练的epochs是40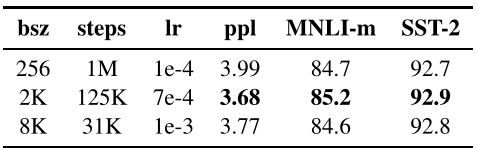
这里插播一下Roberta的一些训练上的技巧,感觉应该是比较通用的,因为整个任务的数据量是一定的,所以batch size增加整个训练的步数小了,随着一个批次的数据大小的增长,模型的准确率和复杂性,同时可以使用分布式数据来并行训练,所以这里使用8K作为batch size 这个大小在文本上不是很夸张(但是图像上估计是不适用的,PPYOLO2建议是64-128,因为显存有限),2019年You et at训练Bert是采用32k作为batch size (所以用了很多显卡?),即是是这样也在1024个V100GPU上跑了接近一天的时间,如果是单卡能跑好几年。
经典的线性WarmUp 设置为总步数的6%,学习率为然后线性衰减到0,
这些训练设置要比Roberta的预训练参数要小,因为是做领域迁移,同时Longformer也做了多项式学习率衰减,模型总共进行了20w步的预训练,其中最初的3000步是用来做模型预热也就是WarmUp的,便于模型领域迁移存在的启动问题,
we take the fact description as
inputs and extract the judgment annotations with regular expressions.
我们使用正则来提取裁判文书的要素,并且将实施描述作为输入。
模型在多个公开的法律任务数据集上进行了下游任务的评估,尤其在法律案件检索上性能提升很高,因为Bert模型无法处理完整的文书内容,阅读理解任务上在法律语料上训练的Roberta处理理解任务上要好一些,但是判断答案正确性这一任务上Lawformer要更加好,
话说这个数据集链接没有放在论文里面,但是在项目LegalPLMs的github文档说明里面提供了CAIL_Long,感觉语料很有价值。
模型的预训练文件是huggingface和thunlp

若有收获,就点个赞吧
0 人点赞
