进入Demo所在目录
cd /E/MAX78000/MAXSDK/Examples/MAX78000/CNN/kws20_demo
执行编译
make
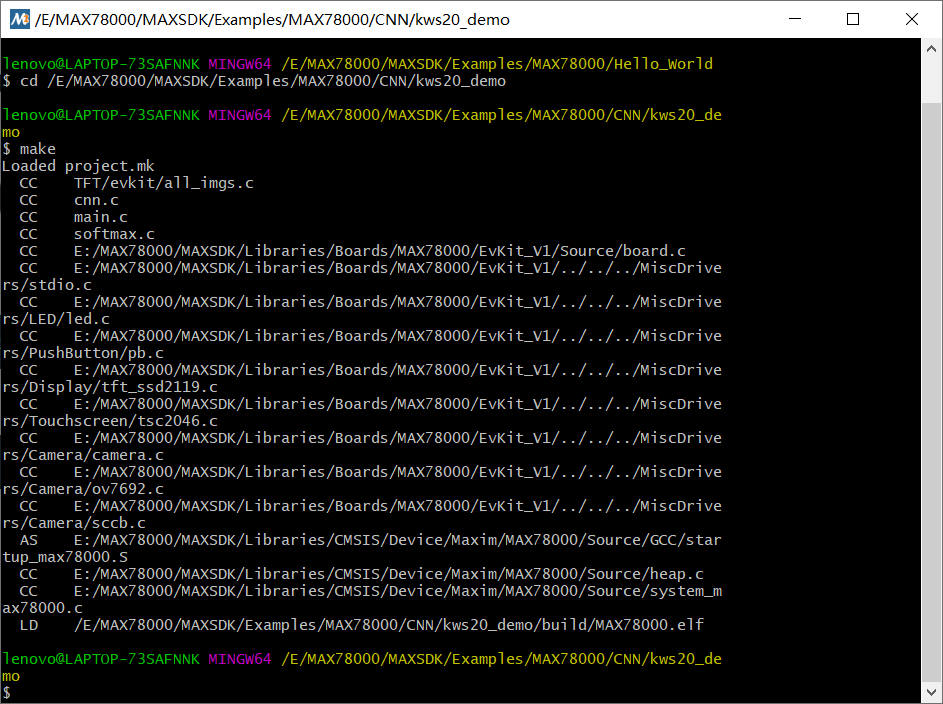
如果之前已经被编译过了,可以先清除,再make
make distclean
选择板型
根据自己用的开发板不一样,注释掉BOARD=EvKit_V1
To compile code for MAX78000 EVKIT enable BOARD=EvKit_V1 in project.mk:
# Specify the board usedifeq "$(BOARD)" ""BOARD=EvKit_V1#BOARD=FTHR_RevAendif
To compile code for MAX78000 Feather board enable BOARD=FTHR_RevA in project.mk:
# Specify the board usedifeq "$(BOARD)" ""#BOARD=EvKit_V1BOARD=FTHR_RevAendif
如果你用的IDE来开发的,可以这里设置。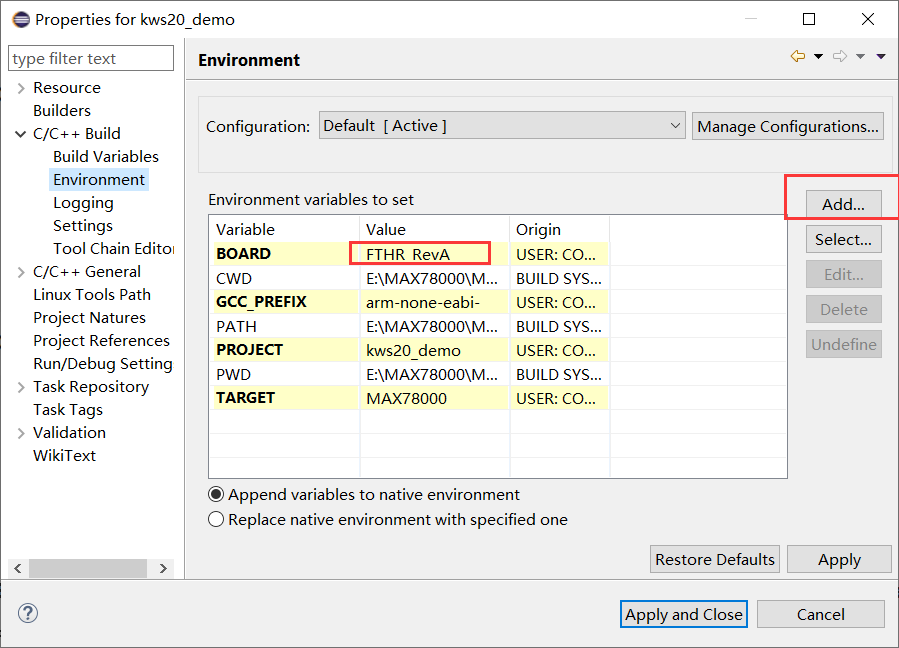
之后可以打开这个文件,来看一下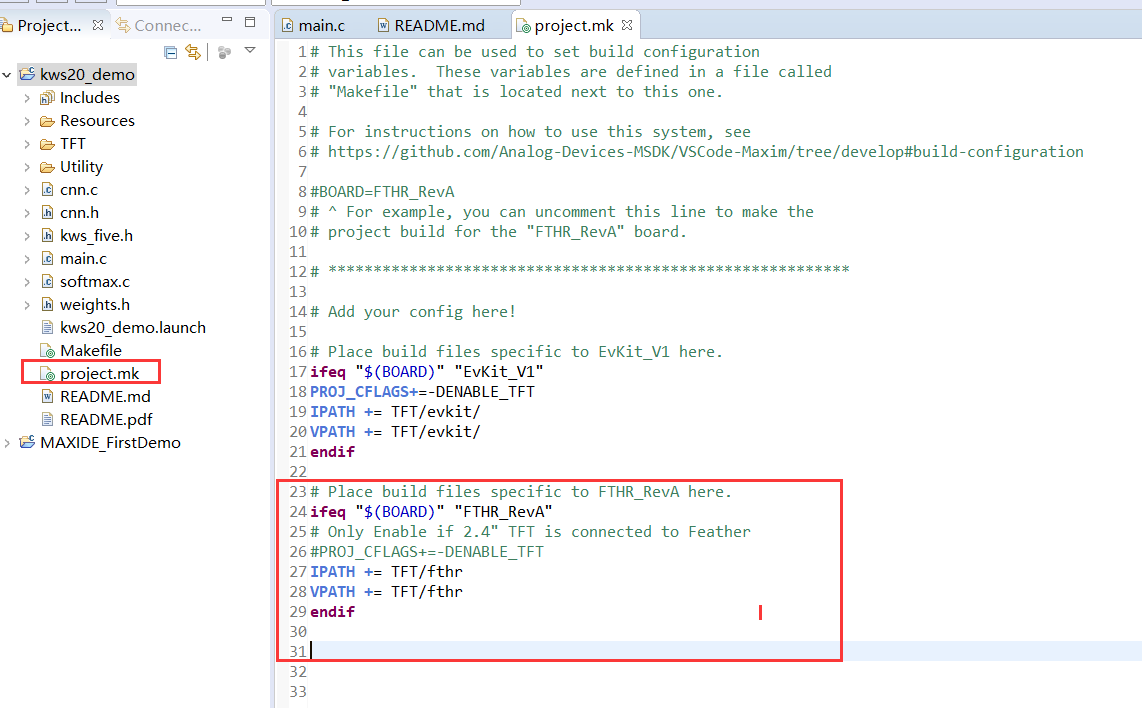
开始烧录
如果你是Window上整的
openocd -s $MAXIM_PATH/Tools/OpenOCD/scripts -f interface/cmsis-dap.cfg -f target/max78000.cfg -c "program build/MAX78000.elf reset exit"
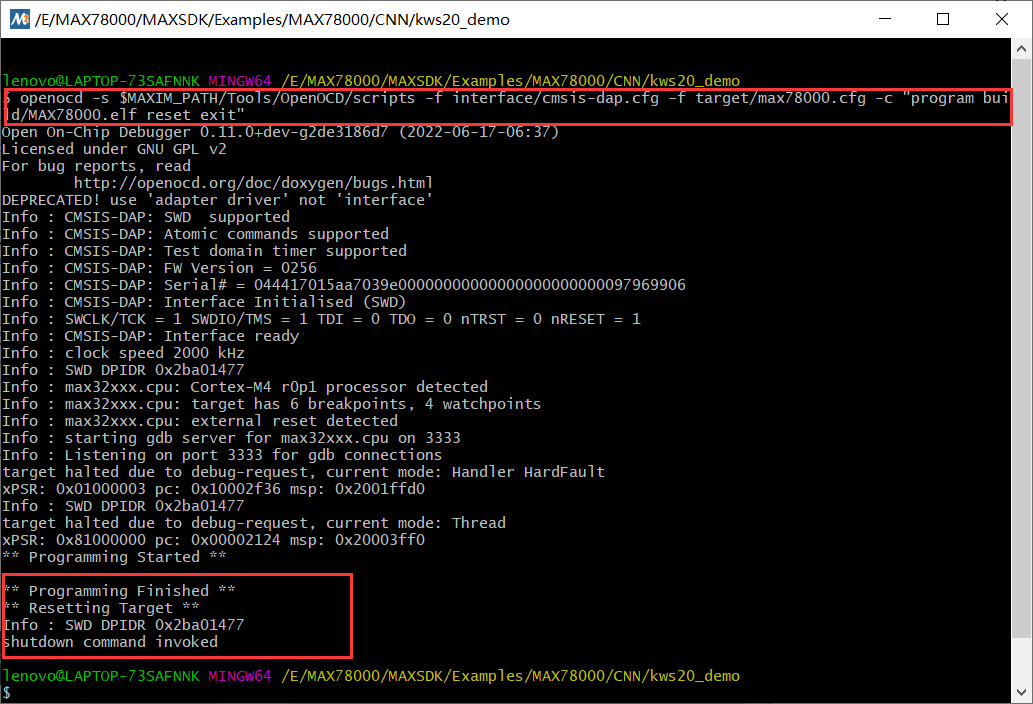
然后就烧录进去了,没了,里面本来的那个Demo没了,变成这玩意了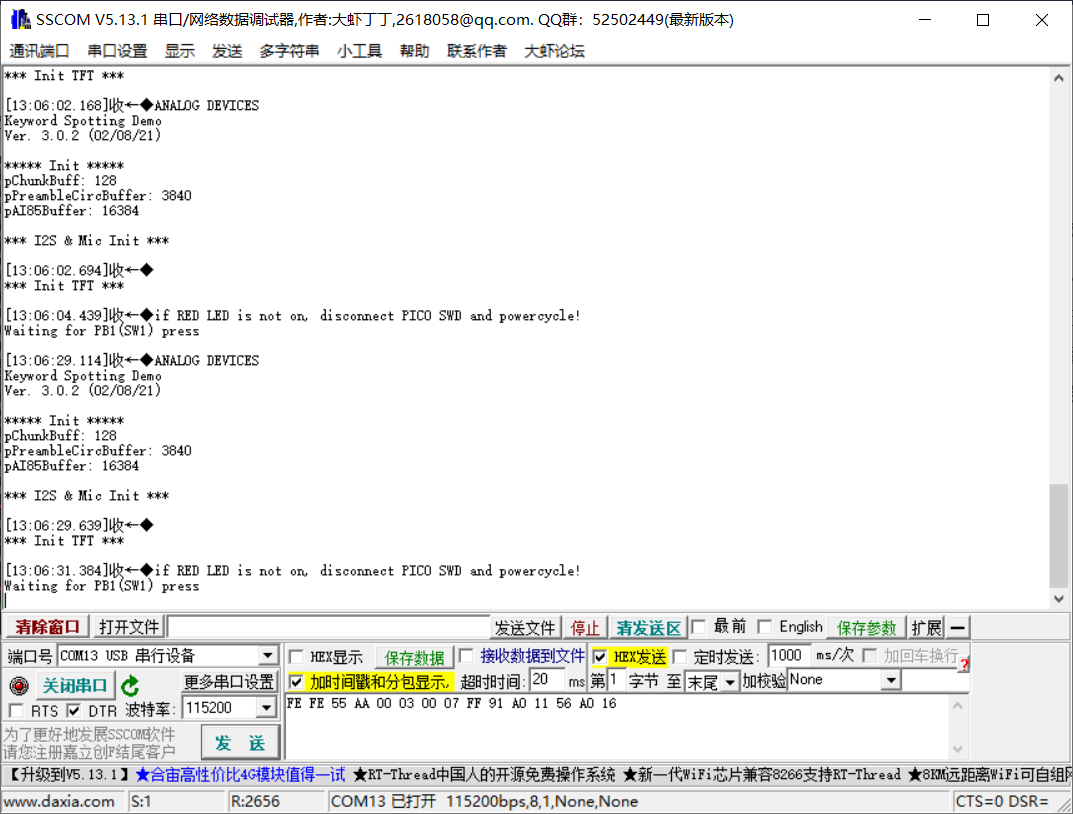
如果你在Linux上
./openocd -f tcl/interface/cmsis-dap.cfg -f tcl/target/max78000.cfg -c "program build/MAX78000.elf verify reset exit"
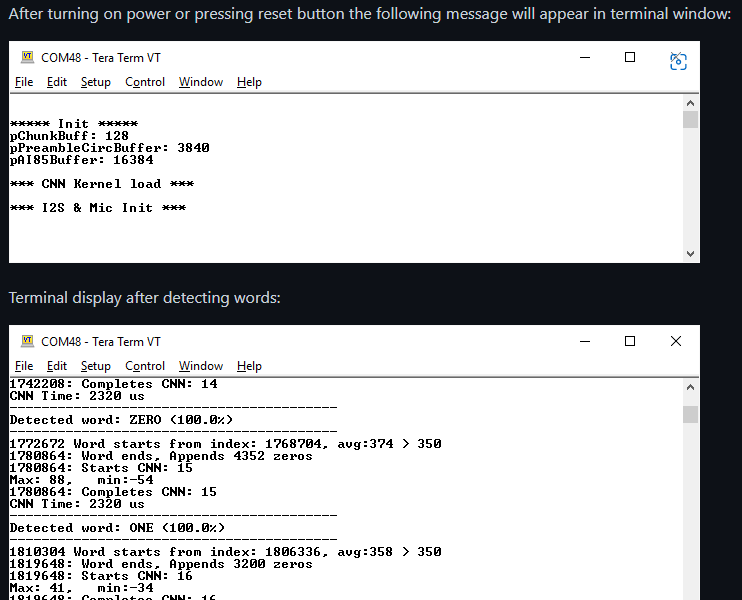
原理部分
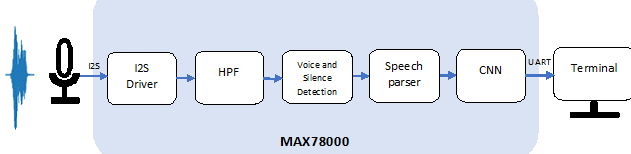
CNN Model 卷积神经网络模型
The KWS20 v.3 Convolutional Neural Network (CNN) model consists of 1D CNN with 8 layers and one fully connected layer to recognize keyword from 20 words dictionary used for training.
class AI85KWS20Netv3(nn.Module):"""Compound KWS20 v3 Audio net, all with Conv1Ds"""# num_classes = n keywords + 1 unknowndef __init__(self,num_classes=21,num_channels=128,dimensions=(128, 1), # pylint: disable=unused-argumentbias=False,**kwargs):super().__init__()self.drop = nn.Dropout(p=0.2)# Time: 128 Feature :128self.voice_conv1 = ai8x.FusedConv1dReLU(num_channels, 100, 1,stride=1, padding=0,bias=bias, **kwargs)# T: 128 F: 100self.voice_conv2 = ai8x.FusedConv1dReLU(100, 96, 3,stride=1, padding=0,bias=bias, **kwargs)# T: 126 F : 96self.voice_conv3 = ai8x.FusedMaxPoolConv1dReLU(96, 64, 3,stride=1, padding=1,bias=bias, **kwargs)# T: 62 F : 64self.voice_conv4 = ai8x.FusedConv1dReLU(64, 48, 3,stride=1, padding=0,bias=bias, **kwargs)# T : 60 F : 48self.kws_conv1 = ai8x.FusedMaxPoolConv1dReLU(48, 64, 3,stride=1, padding=1,bias=bias, **kwargs)# T: 30 F : 64self.kws_conv2 = ai8x.FusedConv1dReLU(64, 96, 3,stride=1, padding=0,bias=bias, **kwargs)# T: 28 F : 96self.kws_conv3 = ai8x.FusedAvgPoolConv1dReLU(96, 100, 3,stride=1, padding=1,bias=bias, **kwargs)# T : 14 F: 100self.kws_conv4 = ai8x.FusedMaxPoolConv1dReLU(100, 64, 6,stride=1, padding=1,bias=bias, **kwargs)# T : 2 F: 128self.fc = ai8x.Linear(256, num_classes, bias=bias, wide=True, **kwargs)def forward(self, x): # pylint: disable=arguments-differ"""Forward prop"""# Run CNNx = self.voice_conv1(x)x = self.voice_conv2(x)x = self.drop(x)x = self.voice_conv3(x)x = self.voice_conv4(x)x = self.drop(x)x = self.kws_conv1(x)x = self.kws_conv2(x)x = self.drop(x)x = self.kws_conv3(x)x = self.kws_conv4(x)x = x.view(x.size(0), -1)x = self.fc(x)return x
The CNN input is 128x128=16384 8-bit signed speech samples.
试试烧录试kws20_v3
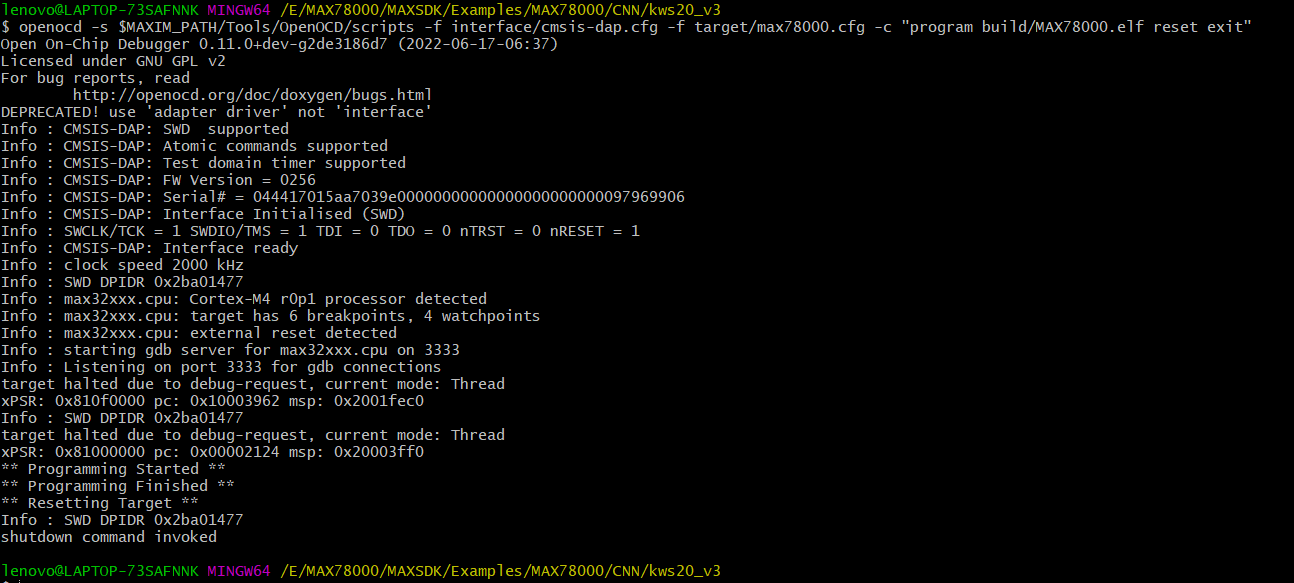
成功。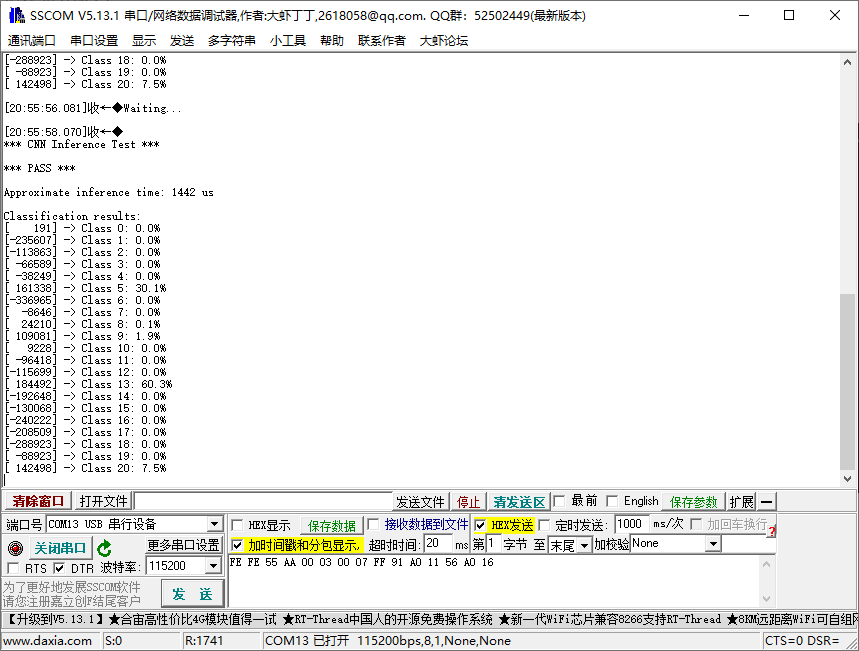
在编译烧录之前一定注意,要先make distclean 一下,不然会出问题的
尝试烧录 work15
cd /E/MAX78000/voice_light/work15/work15/kws20_demo/
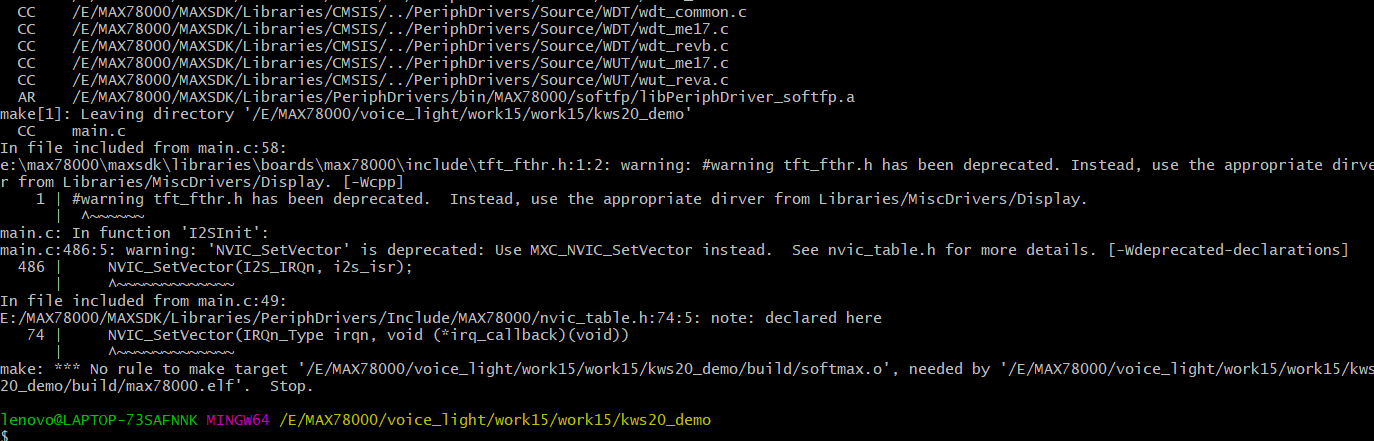
尝试烧录kws20_demo-riscv
$ cd /E/MAX78000/MAXSDK/Examples/MAX78000/CNN/kws20_demo-riscv/


若有收获,就点个赞吧
0 人点赞
