CPU与GPU
在没有GPU之前,基本上所有的任务都是交给CPU来做的。有GPU之后,二者就进行了分工,CPU负责逻辑性强的事物处理和串行计算,GPU则专注于执行高度线程化的并行处理任务(大规模计算任务)。GPU并不是一个独立运行的计算平台,而需要与CPU协同工作,可以看成是CPU的协处理器,因此当我们在说GPU并行计算时,其实是指的基于CPU+GPU的异构计算架构。在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device)。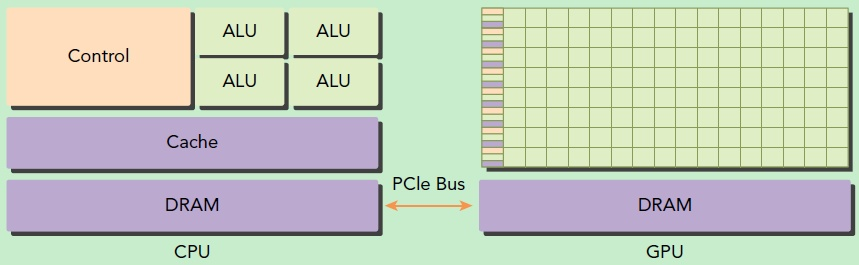
GPU包括更多的运算核心,其特别适合数据并行的计算密集型任务,如大型矩阵运算,而CPU的运算核心较少,但是其可以实现复杂的逻辑运算,因此其适合控制密集型任务。另外,CPU上的线程是重量级的,上下文切换开销大,但是GPU由于存在很多核心,其线程是轻量级的。因此,基于CPU+GPU的异构计算平台可以优势互补,CPU负责处理逻辑复杂的串行程序,而GPU重点处理数据密集型的并行计算程序,从而发挥最大功效。GPU无论发展得多快,都只能是替CPU分担工作,而不是取代CPU。
GPU中有很多的运算器ALU和很少的缓存cache,缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,而是为线程thread提高服务的。如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问DRAM。
CUDA
2006年,NVIDIA公司发布了CUDA(Compute Unified Device Architecture),是一种新的操作GPU计算的硬件和软件架构,是建立在NVIDIA的GPUs上的一个通用并行计算平台和编程模型,它提供了GPU编程的简易接口,基于CUDA编程可以构建基于GPU计算的应用程序,利用GPUs的并行计算引擎来更加高效地解决比较复杂的计算难题。它将GPU视作一个数据并行计算设备,而且无需把这些计算映射到图形API。操作系统的多任务机制可以同时管理CUDA访问GPU和图形程序的运行库,其计算特性支持利用CUDA直观地编写GPU核心程序。
CUDA提供了对其它编程语言的支持,如C/C++,Python,Fortran等语言。只有安装CUDA才能够进行复杂的并行计算。主流的深度学习框架也都是基于CUDA进行GPU并行加速的,几乎无一例外。还有一个叫做cudnn,是针对深度卷积神经网络的加速库。
CUDA在软件方面组成有:一个CUDA库、一个应用程序编程接口(API)及其运行库(Runtime)、两个较高级别的通用数学库,即CUFFT和CUBLAS。CUDA改进了DRAM的读写灵活性,使得GPU与CPU的机制相吻合。另一方面,CUDA提供了片上(on-chip)共享内存,使得线程之间可以共享数据。应用程序可以利用共享内存来减少DRAM的数据传送,更少的依赖DRAM的内存带宽。

若有收获,就点个赞吧
0 人点赞
