6.图
图:由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V, E),其中G表示一个图,V是图G中顶点的集合,E是图G中边的集合。
特点:
- 顶点集合不能为空
- 边的集合可以为空
各种图定义
- 无向图:若顶点v1到v2之间的边没有方向,则称这条边为无向边,用无序偶对(v1, v2)来表示。无向图就是图中任意两个顶点之间的边都是无向边。
无向图 - 有向图:若从顶点v1到v2的边有方向,则称这条边为有向边,也称为弧。用有序偶对
有向图 - 简单图:在图中,不存在顶点到其自身的边,并且同一条边不重复出现,称为简单图。
非简单图 - 完全图:如果在无向图中,任意两个顶点之间都存在边,则称为完全图。
完全图 - 有向完全图:如果任意两个顶点之间都存在互为相反的两条弧,则称为又想完全图。
有向完全图 - 有很少条边或弧的图称为稀疏图,反之称为稠密图。(数量不一定)
- 与图的边或者弧相关的数字叫做权,带权的图称为网。
- 子图:假设有两个图G=(V, {E})和G1=(V1, {E1}),如果V1⊆V,且E1⊆E,则称G1为G的子图。
图的顶点和边之间的关系
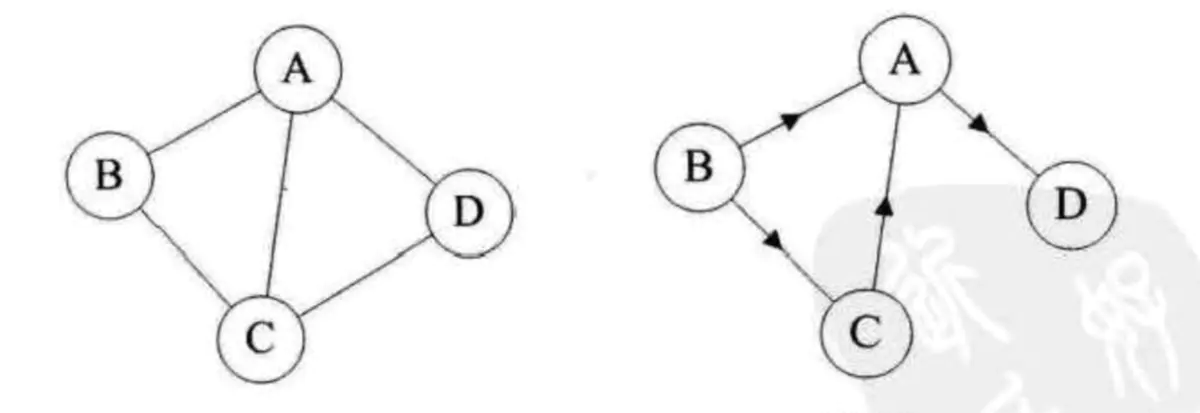
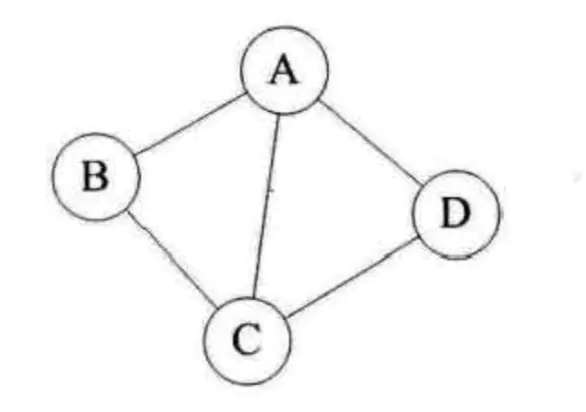
图1
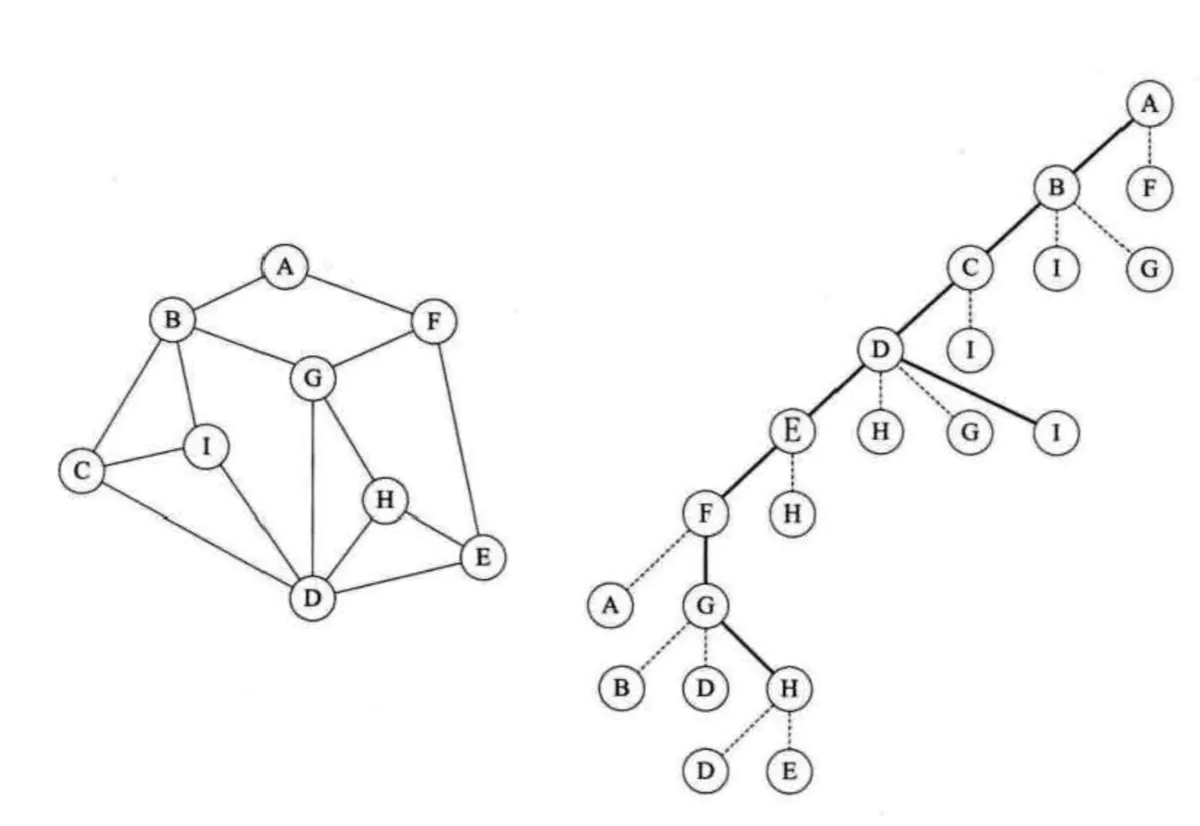
- 顶点的度:
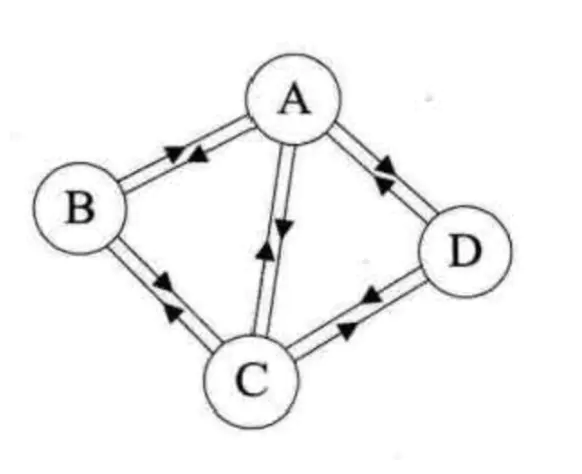
对于无向图G=(V,{E}),如果边(V,V1)∈E,则称顶点V和V1互为邻接点,顶点V的度是和V相关联的边的数目,记为TD(V)。如图1,A的度TD(A)=3,TD(B)=2,TD(C)=3,TD(D)=2,则各个顶点的度总和为:3+2+3+2=10,而图1无向图的边数为5,即各个顶点的度的总和的一半。
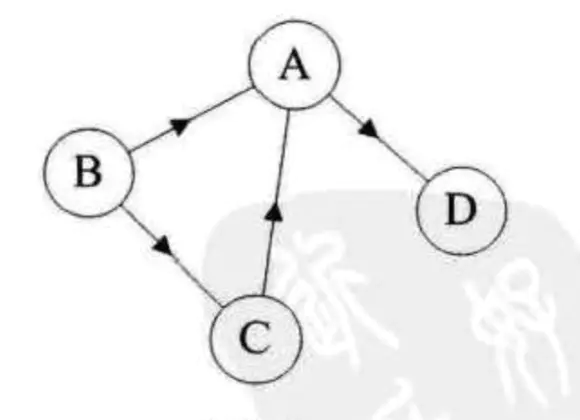
对于有向图G=(V,{E}),如果弧 - 路径:
从一个顶点到另一个顶点所走过的顶点和边所连成的通道。比如图1的无向图,从B到D有四条路径,分别是(BAD),(BCD),(BACD),(BCAD)。而图1从B到D的路径是有方向的,即(BAD),(BCAD)。路径的长度是路径上的边数或弧的数目。序列中顶点不重复出现的路径称为简单路径。 - 回路或环:
点一个顶点和最后一个顶点相同的路径称为回路或者环。其中,除了第一个顶点和最后一个顶点,其余顶点不重复出现的回路,称为简单回路或简单环。下面图1左边就是简单回路,右边并不是简单回路,因为顶点C重复出现了。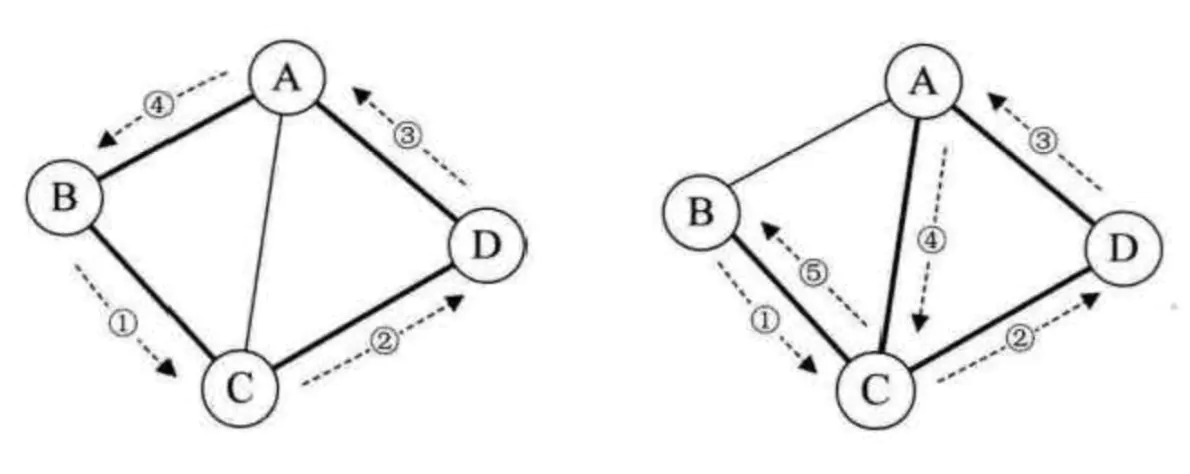
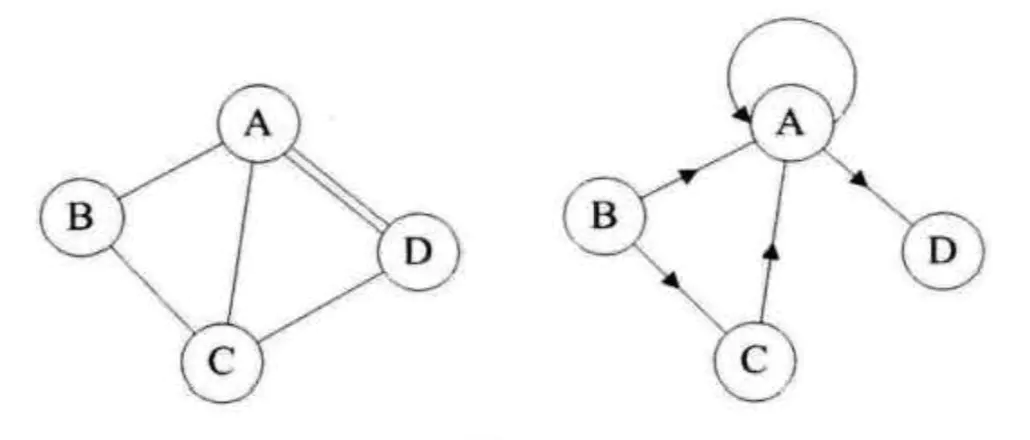
图2 - 连通图:
在无向图G中,如果从顶点V到顶点V1有路径,则称顶点V和顶点V1是连通的。如果对于图中任意两个顶点都是连通的,则称G是连通图。如图3,左边的图不是连通图,右边的图是连通图。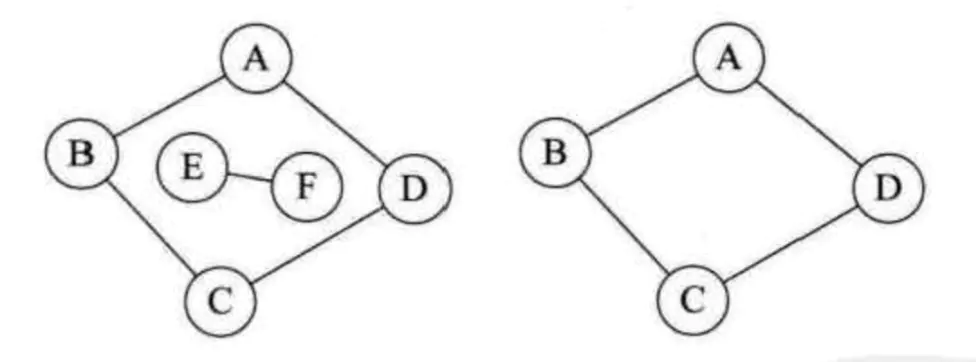
图3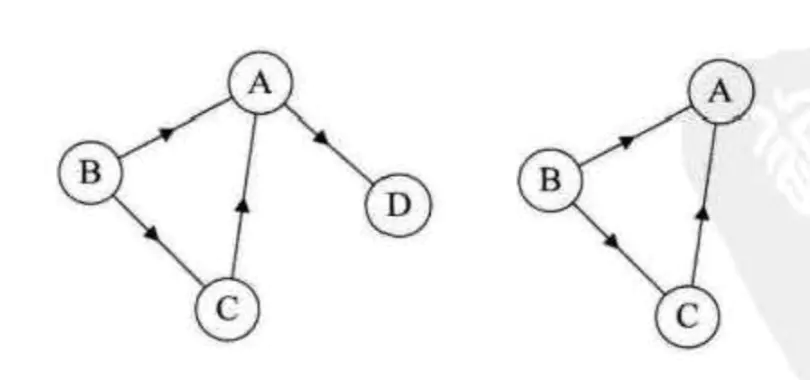
图4 - 连通分量:
无向图中的极大连通子图称为连通分量。
(1)子图。
(2)子图是连通的。
(3)连通的子图含有极大的顶点数。
(4)具有极大顶点数的连通子图包含依附于这些顶点的所有边。
比如图3中,左边的图的连通分量为右边的图。
在有向图G中,如果对于每一对V1,V2∈V,V1≠V2,从V1到V2和从V2到V1都存在路径,则称G是强连通图。有向图中极大强连通子图称做有向图的强连通分量。上图4中左边的图不是强连通图,右边的图是强连通图。 - 无向图生成树:
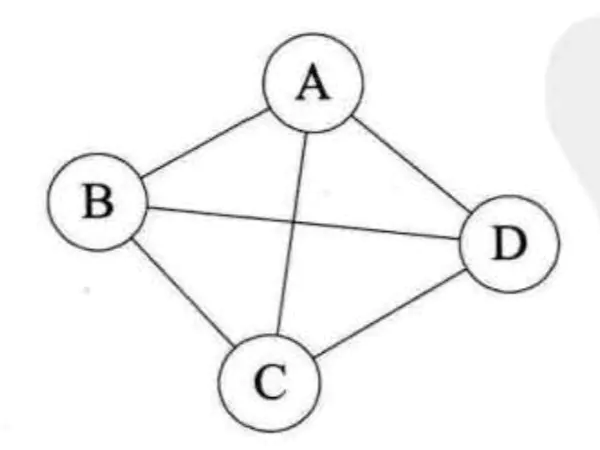
一个连通图的生成树是一个极小的连通子图,它含有图中全部的n个顶点,但只有足以构成一棵树的n-1条边。比如图2中左边的无向图,它的连通分量为自身,则它的极小连通子图为,自身去调AC和AD两条边,则构成一个极小连通图,因为再去多一条边就构不成连通图了,这个就是连通图的生成树。 - 有向树:
如果一个有向图恰有一个顶点的入度为0,其余顶点的入度都为1,则是一颗有向树。(不需要连通) - 生成森林:
一个有向图的生成森林由若干有向树组成,含有图中全部顶点,但只有足以构成若干课不相交的有向树的弧。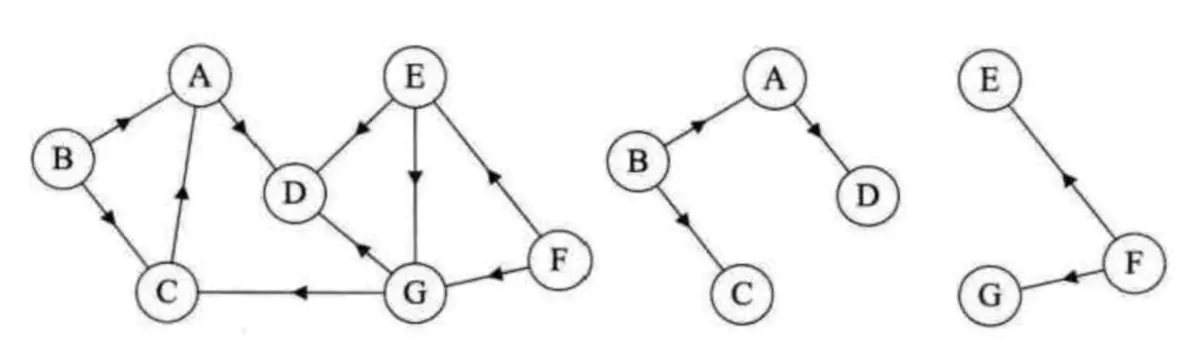
图5
图的抽象数据类型
ADT 图(Graph)Data顶点是有穷且非空集合+边的集合Operation...addVertex(v):添加顶点addEdge(v1, v2):添加边DFSTraverse():深度优先遍历BFSTraverse():广度优先遍历...EndADT
图的数据存储
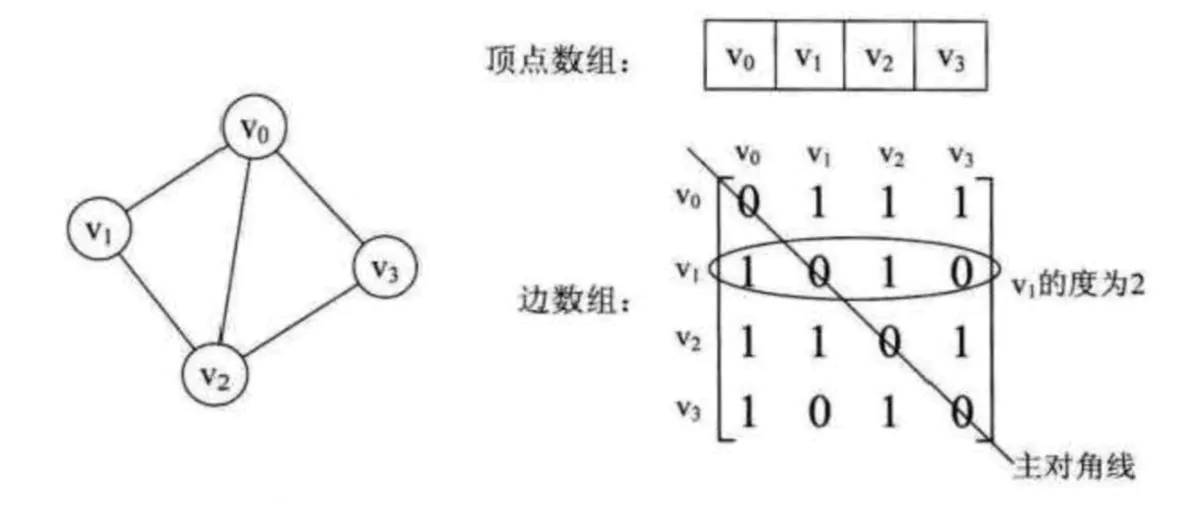
邻接矩阵:用两个数组来表示图。一个一维数组储存图中顶点信息,一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。
- 无向图

邻接矩阵图1
邻接矩阵图2
信息:
(1)v1的度即为第1行,所有元素之和:1+0+1+0=2。
(2)v1的邻接点即为第1行,所有元素为1的顶点。
(3)判断v1到v2是否有边,只需要判断arc[1][2]==1?就行,所以,v1到v2有边。
- 有向图
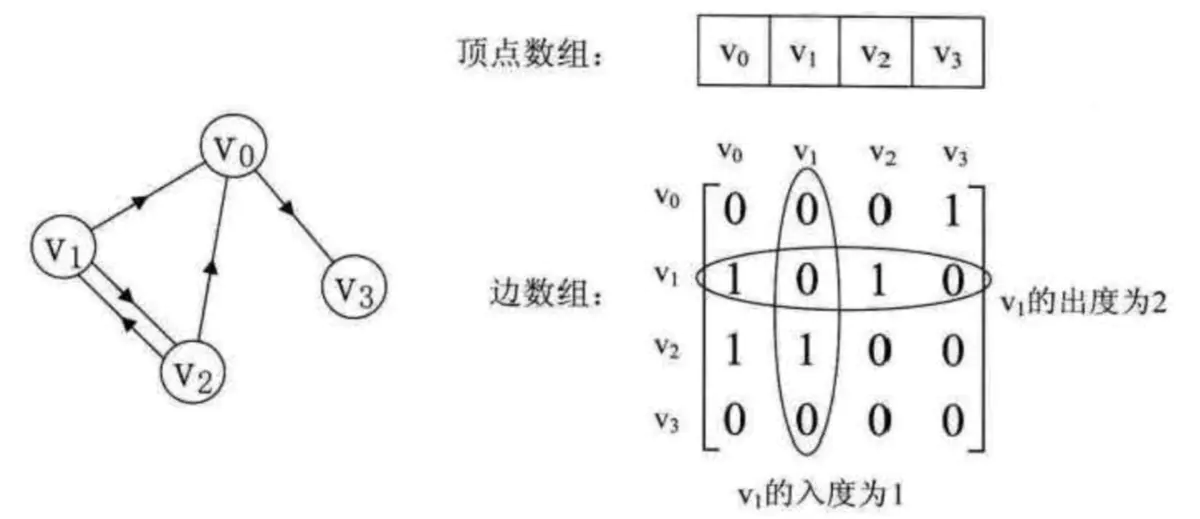
邻接矩阵3
信息:
(1)v1的出度为第1行的元素之和:1+0+1+0=2;v1的入度为第1列的元素之和:0+0+1+0=1。
(2)判断v0到v3是否有弧,只需要判断arc[0][3]==1?就行,所以,v0到v3是有弧的。(v3到v0没有弧,弧是有方向的) - 带权有向图
就是将有向图的邻接矩阵中的0和1换成相应的权值,不存在则设置为∞,自身则设置为0。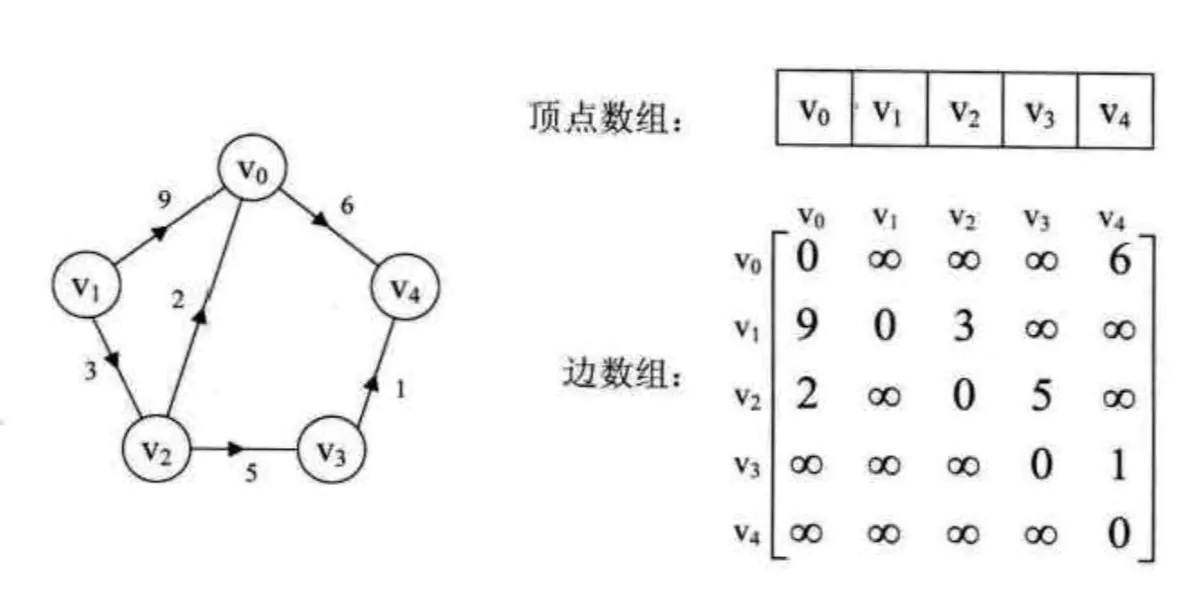
邻接矩阵4
邻接表:数组和链表组合的存储方法称为邻接表。
邻接表处理:
(1)图中顶点使用一个一维数组存储。
(2)图中每个顶点v的所有邻接点构成一个线性表。
- 无向图邻接表:
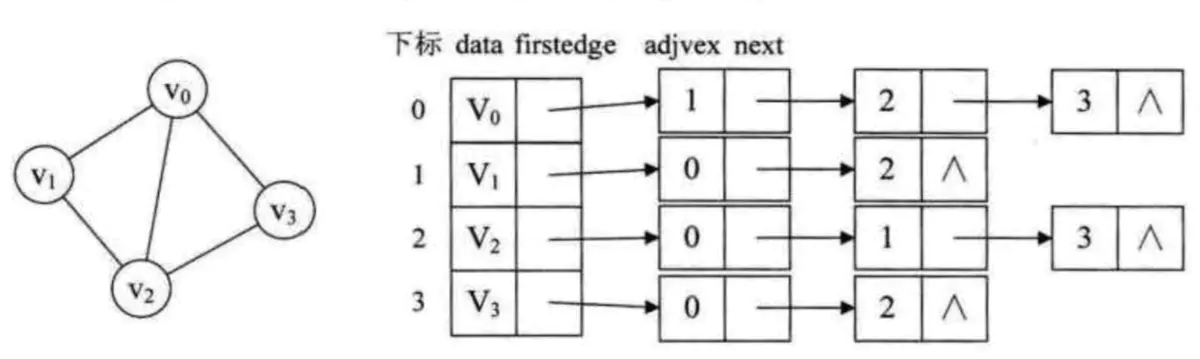
邻接表图1 - 有向图邻接表和逆邻接表:
(1)有向图邻接表记录的是顶点的出度的弧,即弧尾。
(2)有向图逆邻接表记录的是顶点的入度的弧,即弧头。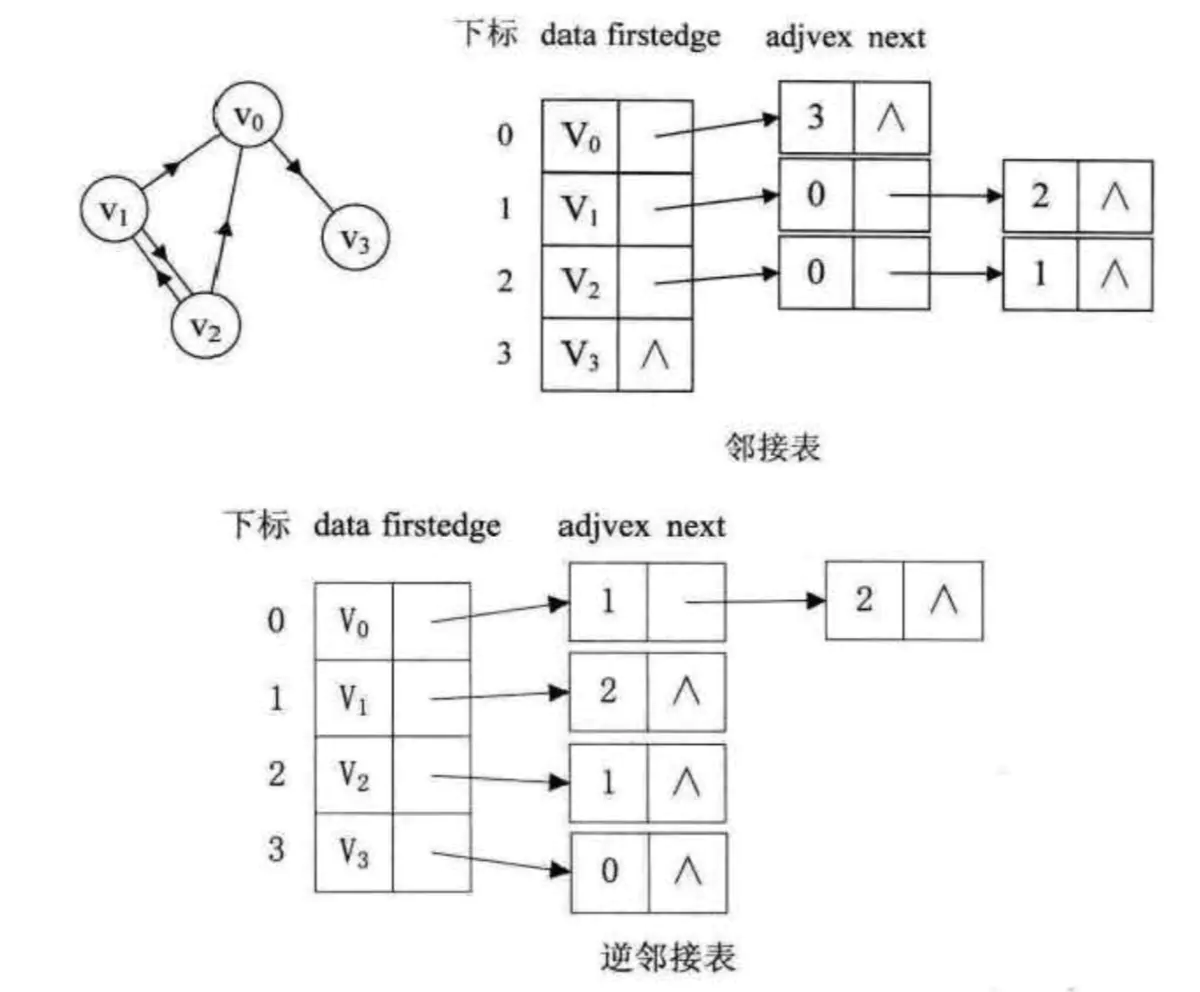
邻接表图2 - 带权邻接表
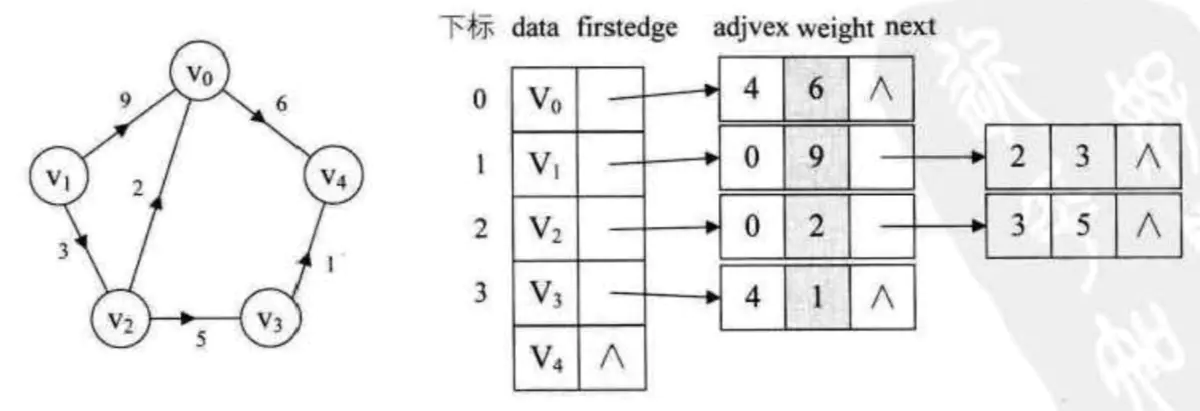
邻接表图3
十字链表:即把邻接表与逆邻接表结合起来。(有向邻接表的优化)
- 重新定义顶点

十字链表顶点
data为数据域,firstin为入边的表头指针,firsetout为出边的表头指针。顶点的入边从firstin开始查询,同理,顶点的出边从firstout开始查询。 - 重新定义边结点结构

十字链表结点
tailvex是指弧尾结点的下标,headvex是指弧头结点的下标;headlink是指弧头结点下标和headvex相同的另一个弧头结点下标,同理,taillink是指弧尾结点下标和tailvex相同的另一个弧尾结点下标,没有置为空。
举个例子:
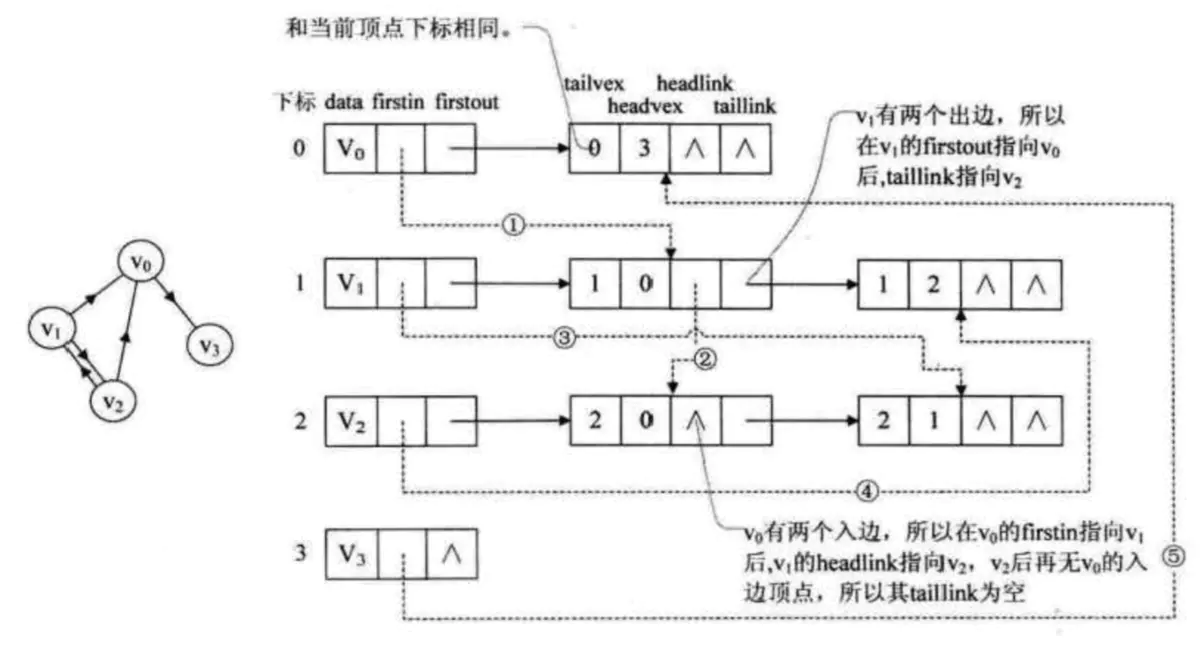
十字链表图1
v0的入度为:1->0, 2->0,v0的出度为:0->3。
邻接多重表:改造边结点,使删除某一条边不需要遍历两次。

邻接多重表结点
其中ivex和jvex是与某条边依附的两个顶点在顶点表中的下标。ilink指向依附顶点ivex的下一条边,jlink指向依附顶点jvex的下一条边。
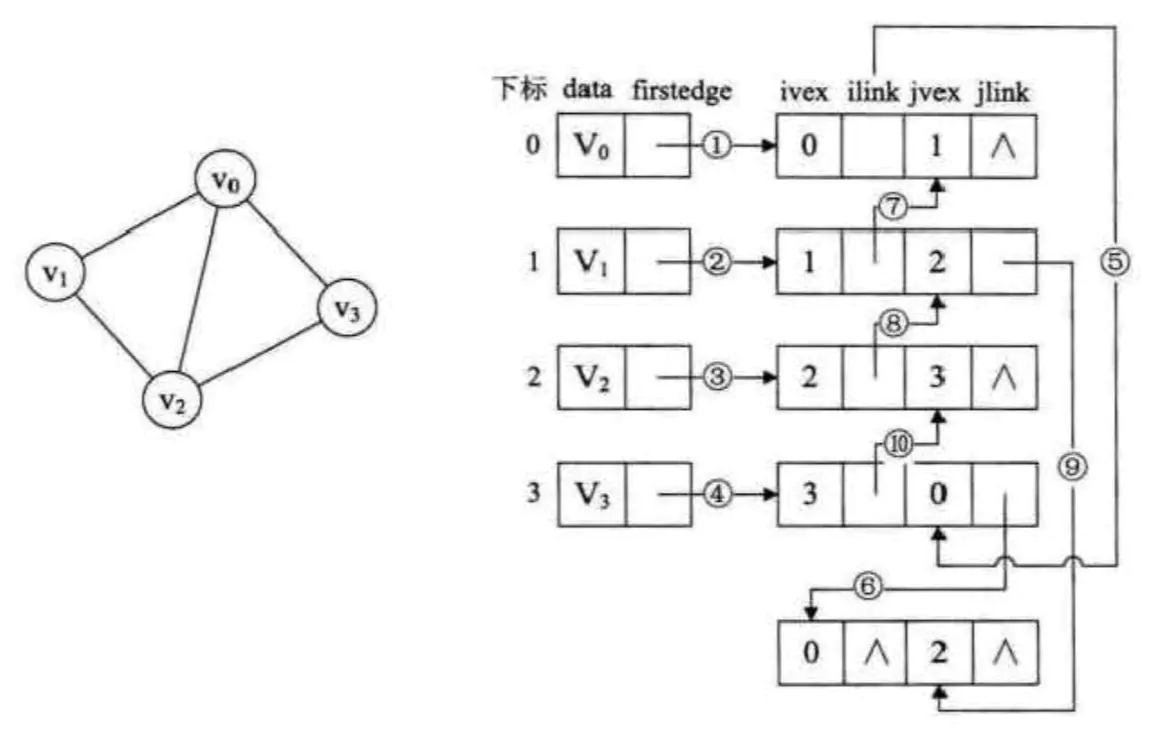
邻接多重表
上图总共有5条边,分别是v0->v1,v1->v2,v2->v3,v3->v0,v0-v2,所以,会有5个边结点。然后从v0开始,有三条邻接的边,分别是v0-v1,v0-v2,v0-v3,首先vo指向E(0,1),然后当前的边结点的ivex=0,所以,ilink需要找到下一条顶点为v0的边,顺着边结点往下找,可以找到E(3,0),所以,ilink指向E(3,0),由于,v0还有另外一条边E(0,2),所以,jlink顺着往下找,找到E(0,2),再往下没有边结点了,所以置为空。其他顶点的操作也是相似的过程。
边集数组:边集数组是由两个一位数组组成。一个是存储顶点信息,另一个是存储边的信息。这个数组每个数据元素由一条边的起点下标(begin),终点下标(end)和权(weight)组成。
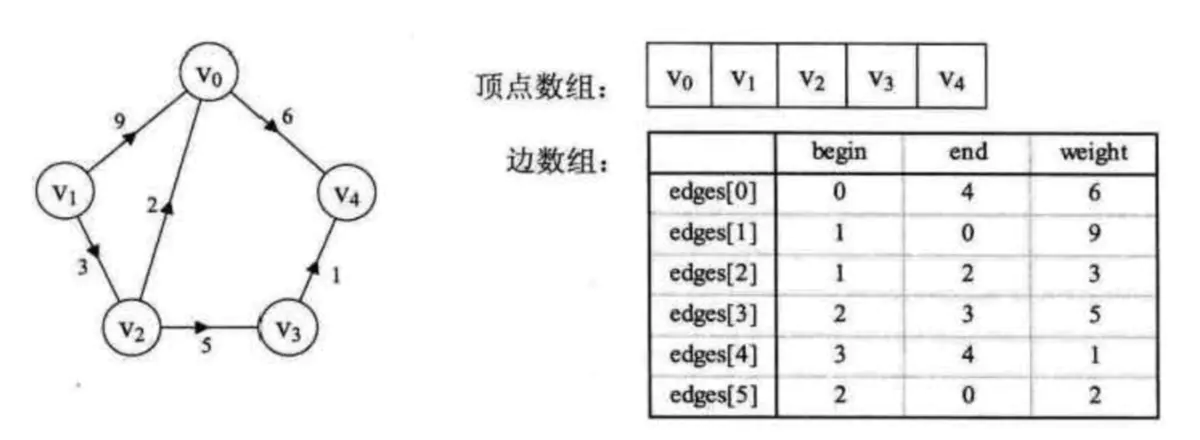
边集数组
图的遍历
图的遍历:从图中某一顶点出发访遍图中其余顶点,且使每一个顶点被访问一次。
- 深度优先遍历(DFS)
连通图深度优先遍历: 从图中的某个顶点v出发,访问此顶点,然后从v的未被访问的邻接顶点出发,深度优先遍历图,直到图中所有和v有路径相通的顶点被访问到。
非连通图深度优先遍历:先对一个顶点进行连通图深度优先遍历,若还有没有被访问的顶点,再对该顶点进行连通图深度优先遍历,直到图中所有顶点都被访问到。
深度优先遍历图1
邻接矩阵存储图,深度优先遍历实现算法
使用深度优先遍历图1实现深度优先遍历算法//邻接矩阵public struct Graph<T: Equatable> {fileprivate var vexs: [T] = []fileprivate var arc: [[Int]] = []public var vertexes: Int {return vexs.count}public var edges: Int {var count = 0for items in arc {for item in items {if item > 0 {count += 1}}}return count}public mutating func addVertex(vertext: T) {vexs.append(vertext)for i in 0..<arc.count {var temp = arc[i]temp.append(0)arc[i] = temp}let newArray = Array(repeating: 0, count: arc.count+1)arc.append(newArray)}public mutating func addEdge(from top1: T, to top2: T) {let containTop1 = vexs.contains { $0 == top1 }let containTop2 = vexs.contains { $0 == top2 }guard containTop1, containTop2 else {return}let row = vexs.index(of: top1)!let column = vexs.index(of: top2)!arc[row][column] = 1}}var graphics = Graph<String>()graphics.addVertex(vertext: "A")graphics.addVertex(vertext: "B")graphics.addVertex(vertext: "C")graphics.addVertex(vertext: "D")graphics.addVertex(vertext: "E")graphics.addVertex(vertext: "F")graphics.addVertex(vertext: "G")graphics.addVertex(vertext: "H")graphics.addVertex(vertext: "I")graphics.addEdge(from: "A", to: "B")graphics.addEdge(from: "A", to: "F")graphics.addEdge(from: "B", to: "C")graphics.addEdge(from: "B", to: "I")graphics.addEdge(from: "B", to: "G")graphics.addEdge(from: "C", to: "I")graphics.addEdge(from: "C", to: "D")graphics.addEdge(from: "D", to: "I")graphics.addEdge(from: "D", to: "E")graphics.addEdge(from: "D", to: "G")graphics.addEdge(from: "D", to: "H")graphics.addEdge(from: "E", to: "F")graphics.addEdge(from: "E", to: "H")graphics.addEdge(from: "F", to: "G")graphics.addEdge(from: "G", to: "H")//深度优先遍历var visited: [Bool] = []func DFS(graphics: Graph<String>, i: Int) {visited[i] = trueprint(graphics.vexs[i])for j in 0..<graphics.vertexes {if graphics.arc[i][j] == 1, !visited[j] {DFS(graphics: graphics, i: j)}}}func DFSTraverse(graphics: Graph<String>) {for _ in 0..<graphics.vertexes {visited.append(false)}for i in 0..<graphics.vertexes {if !visited[i] {DFS(graphics: graphics, i: i)}}}DFSTraverse(graphics: graphics)输出结果:ABCDEFGHI
邻接链表存储图,深度优先遍历实现算法:
class EdgeNode<T: Equatable> {var index: Intvar nextEdge: EdgeNode<T>?init(atIndex index: Int) {self.index = index}}class VertexNode<T: Equatable> {var data: Tvar firstEdge: EdgeNode<T>?init(_ data: T) {self.data = data}}class Graphics<T: Equatable> {var adjList: [VertexNode<T>] = []var numVertexes: Int {return adjList.count}var numEdges: Int {var count = 0for vertex in adjList {if let edge = vertex.firstEdge {count += 1var next = edge.nextEdgewhile next != nil {count += 1next = next?.nextEdge}}}return count/2}func addVertex(vertex: T) {let v = VertexNode<T>(vertex)adjList.append(v)}func addEdge(from v1: T, to v2: T) {let vertex1 = getVertex(data: v1)let vertex2 = getVertex(data: v2)guard vertex1 != nil, vertex2 != nil else {return;}let index1 = getVertextIndex(v1)!let index2 = getVertextIndex(v2)!vertextAddEdge(vertex: vertex1!, index: index2)vertextAddEdge(vertex: vertex2!, index: index1)}func vertextAddEdge(vertex: VertexNode<T>, index: Int) {var edgeNode = vertex.firstEdgeguard edgeNode != nil else {vertex.firstEdge = EdgeNode<T>(atIndex: index)return;}let value = adjList[index].dataif adjList[(edgeNode?.index)!].data == value {return}while edgeNode?.nextEdge != nil {edgeNode = edgeNode?.nextEdgeif adjList[(edgeNode?.index)!].data == value {return}}edgeNode?.nextEdge = EdgeNode<T>(atIndex: index)}func getVertex(data: T) -> VertexNode<T>? {for v in adjList {if v.data == data {return v}}return nil}func getVertextIndex(_ data: T) -> Int? {for index in 0..<adjList.endIndex {let vertex = adjList[index]if vertex.data == data {return index}}return nil}}let graphics = Graphics<String>()graphics.addVertex(vertex: "A")graphics.addVertex(vertex: "B")graphics.addVertex(vertex: "C")graphics.addVertex(vertex: "D")graphics.addVertex(vertex: "E")graphics.addVertex(vertex: "F")graphics.addVertex(vertex: "G")graphics.addVertex(vertex: "H")graphics.addVertex(vertex: "I")graphics.addEdge(from: "A", to: "B")graphics.addEdge(from: "A", to: "F")graphics.addEdge(from: "B", to: "A")graphics.addEdge(from: "B", to: "C")graphics.addEdge(from: "B", to: "G")graphics.addEdge(from: "B", to: "I")graphics.addEdge(from: "C", to: "B")graphics.addEdge(from: "C", to: "D")graphics.addEdge(from: "C", to: "I")graphics.addEdge(from: "D", to: "C")graphics.addEdge(from: "D", to: "E")graphics.addEdge(from: "D", to: "G")graphics.addEdge(from: "D", to: "H")graphics.addEdge(from: "D", to: "I")graphics.addEdge(from: "E", to: "D")graphics.addEdge(from: "E", to: "F")graphics.addEdge(from: "E", to: "H")graphics.addEdge(from: "F", to: "G")graphics.addEdge(from: "G", to: "B")graphics.addEdge(from: "G", to: "D")graphics.addEdge(from: "G", to: "F")graphics.addEdge(from: "G", to: "H")var visited: [Bool] = []func DFS(graphics: Graphics<String>, i: Int) {visited[i] = trueprint(graphics.adjList[i].data)var edgeNode = graphics.adjList[i].firstEdgewhile edgeNode != nil {if !visited[(edgeNode?.index)!] {DFS(graphics: graphics, i: (edgeNode?.index)!)}edgeNode = edgeNode?.nextEdge}}func DFSTraverse(graphics: Graphics<String>) {for _ in 0..<graphics.numVertexes {visited.append(false)}for i in 0..<graphics.numVertexes {if !visited[i] {DFS(graphics: graphics, i: i)}}}DFSTraverse(graphics: graphics)输出结果:ABCDEFGHI
- 广度优先遍历(BFS)
如果深度优先遍历类似于树的前序遍历,那么广度优先遍历则类似于树的层遍历。与深度优先遍历图1为例,则广度优先遍历的顺序则为:
(1)A(2)BF(3)CIGE(4)DH。
邻接矩阵存储图,广度优先遍历实现算法
var visited: [Bool] = []func BFSTraverse(graphics: Graph<String>) {for _ in 0..<graphics.vertexes {visited.append(false)}var result: [String] = []for i in 0..<graphics.vertexes {if !visited[i] {visited[i] = trueprint(graphics.vexs[i])result.append(graphics.vexs[i])while !result.isEmpty {result.removeFirst()for j in 0..<graphics.vertexes {if graphics.arc[i][j] == 1, !visited[j] {visited[j] = trueprint(graphics.vexs[j])result.append(graphics.vexs[j])}}}}}}BFSTraverse(graphics: graphics)输出结果:ABFCDIEHG
邻接链表存储图,深度优先遍历实现算法:
var visited: [Bool] = []func BFSTraverse(graphics: Graphics<String>) {for _ in 0..<graphics.numVertexes {visited.append(false)}var result: [VertexNode<String>] = []for i in 0..<graphics.numVertexes {if !visited[i] {visited[i] = trueprint(graphics.adjList[i].data)result.append(graphics.adjList[i])while !result.isEmpty {let vertex = result.removeFirst()var edgeNode = vertex.firstEdgewhile edgeNode != nil {if !visited[(edgeNode?.index)!] {visited[(edgeNode?.index)!] = trueprint(graphics.adjList[(edgeNode?.index)!].data)result.append(graphics.adjList[(edgeNode?.index)!])}edgeNode = edgeNode?.nextEdge}}}}}BFSTraverse(graphics: graphics)输出结果:ABFCGIEDH
比较:深度优先遍历适合目标比较明确,而广度优先遍历更适合在不断扩大范围时找到相对最优解的情况。
最小生成树
最小生成树:构造连通网的最小代价生成树称为最小生成树。
寻找最小生成树的两种算法:普里姆算法(Prim)和克鲁斯卡尔算法(Kruskal)。
- 普里姆算法
假设N是连通网,TE是N上最小生成树中边的集合。算法从U={u0}(u0∈V),TE={}开始。重复执行下述操作:在所有u∈V,v∈V-U的边(u,v)∈E中,找一条代价最小的边(u0,v0)并入集合TE,同时v0并入U,直至U=V为止。此时TE中必有n-1条边,则T=(V,{TE})为N的最小生成树,时间复杂度为O(n^2)。通俗来讲,先从v0开始,找到和v0连接的权重最小的边的顶点v1,然后再找{v0,v1}相连的权重最小的边,直到所有顶点都找完。
func miniSpanTree_prim(graphics: Graph<String>) {var adjvex = Array(repeating: 0, count: graphics.vertexes) //初始化都为0,意味着从v0开始找var lowcost = graphics.arc[0] //初始化为v0所关联的所有边的权值//因为v0已经在adjvex里面了,所以从下标1开始寻找var min: Intfor _ in 1..<graphics.vertexes {min = Int.max //lowcost下标为0则说明该顶点已被找过,下标为Int.max则意味着,没有该条边var k = 0 //保存最小值的下标for j in 1..<graphics.vertexes {if lowcost[j] != 0, lowcost[j] < min {min = lowcost[j]k = j}}print("\(adjvex[k], k)") //adjvex[k]为当前的顶点,k为当前顶点关联权值最小边的顶点的下标//将找到的最小权值边的下一个顶点加入adjvex,并且将该顶点相关联的较小边加入lowcostfor j in 1..<graphics.vertexes {if lowcost[j] != 0, graphics.arc[k][j] < lowcost[j] {lowcost[j] = graphics.arc[k][j]adjvex[j] = k}}}}miniSpanTree_prim(graphics: graphics)输出结果:(0, 1)(0, 5)(1, 8)(8, 2)(1, 6)(6, 7)(7, 4)(7, 3)
- 注意点:每添加一个顶点,lowcost数组中除了对应已选则的顶点为0之外,保存已选顶点和未选顶点之间的所有较小的边。
- 克鲁斯卡尔算法
假设 N= (V,{E})是连通网,则令最小生成树的初始状态为只有 n 个顶点而无边的 非连通图 T={V,{}},图中每个顶点自成一个连通分量。在 E 中选择代价最小的边,若 该边依附的顶点落在 T 中不同的连通分量上,则将此边加入到 T 中,否则舍去此边而 选择下一条代价最小的边。依次类推,直至 T 中所有顶点都在罔一连通分量上为止 ,时间复杂度为O(eloge)。通俗来讲就是,先把所有的边按照权值的大小排序,然后从最小的开始选择,每选择一次需要判断是否和之前已选择的边形成回路,如果形成回路则选择下一条边,直到所有的边都被遍历完,所得就是最小生成树。
struct Edge{let begin: Int, end: Int, weight: Intinit (begin: Int, end: Int, weight: Int) {self.begin = beginself.end = endself.weight = weight}}func miniSpanTree_Kruskal(graphics: Graph<String>) {var edges: [Edge] = [] //边集数组for i in 1..<graphics.vertexes {let arc = graphics.arc[i-1]for j in i..<graphics.vertexes {if arc[j] < Int.max {let edge = Edge(begin: i-1, end: j, weight: arc[j])edges.append(edge)}}}edges.sort{$0.weight < $1.weight}var parent = Array(repeating: 0, count: graphics.vertexes) //判断是否成环的数组for i in 0..<edges.count {let n = find(parent: parent, fedge: edges[i].begin)let m = find(parent: parent, fedge: edges[i].end)if n != m { //一条边从两边开始计算,只要最后的点相等,则会构成环parent[n] = mprint("\(edges[i].begin, edges[i].end) \(edges[i].weight)")}}}//寻找每个点的路径func find(parent: [Int], fedge: Int) -> Int {var result = fedgewhile parent[result] > 0 {result = parent[result]}return result}miniSpanTree_Kruskal(graphics: graphics)
- 注意点:parent数组,从下标开始和相应下标数组中的值,形成该顶点的一条路径。
- 两个算法对比:
对比两个算法,克鲁斯卡尔算法主要是针对边来展开,边数少时效率会非常高,所以对于稀疏图有很大的优势。而普里姆算法对于稠密图,即边数非常多的情况会更 好一些。
最短路径
对于网图来说,最短路径,是指两顶点之间经过的边上权值之和最小的路径,并且,我们称路径上第一个顶点为源点,最后一个顶点为终点。
以下面的网图,寻找最短路径:
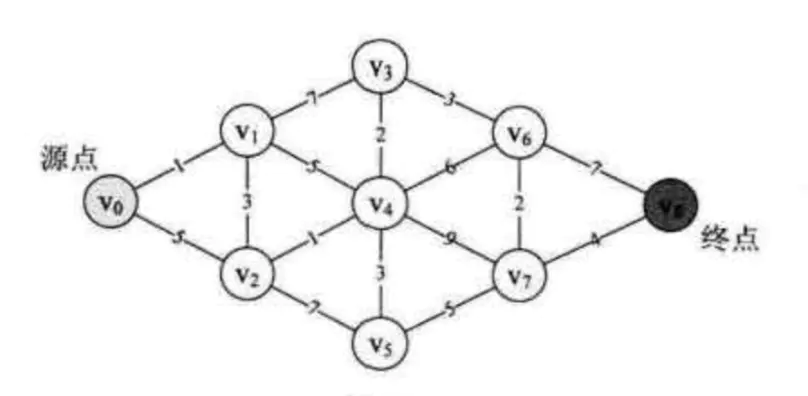
最短路径
var graphics = Graph<String>()graphics.addVertex(vertext: "v0")graphics.addVertex(vertext: "v1")graphics.addVertex(vertext: "v2")graphics.addVertex(vertext: "v3")graphics.addVertex(vertext: "v4")graphics.addVertex(vertext: "v5")graphics.addVertex(vertext: "v6")graphics.addVertex(vertext: "v7")graphics.addVertex(vertext: "v8")//最短路径graphics.addEdge(from: "v0", to: "v1", weight: 1)graphics.addEdge(from: "v0", to: "v2", weight: 5)graphics.addEdge(from: "v1", to: "v0", weight: 1)graphics.addEdge(from: "v1", to: "v2", weight: 3)graphics.addEdge(from: "v1", to: "v3", weight: 7)graphics.addEdge(from: "v1", to: "v4", weight: 5)graphics.addEdge(from: "v2", to: "v0", weight: 5)graphics.addEdge(from: "v2", to: "v1", weight: 3)graphics.addEdge(from: "v2", to: "v4", weight: 1)graphics.addEdge(from: "v2", to: "v5", weight: 7)graphics.addEdge(from: "v3", to: "v1", weight: 7)graphics.addEdge(from: "v3", to: "v4", weight: 2)graphics.addEdge(from: "v3", to: "v6", weight: 3)graphics.addEdge(from: "v4", to: "v1", weight: 5)graphics.addEdge(from: "v4", to: "v2", weight: 1)graphics.addEdge(from: "v4", to: "v3", weight: 2)graphics.addEdge(from: "v4", to: "v5", weight: 3)graphics.addEdge(from: "v4", to: "v6", weight: 6)graphics.addEdge(from: "v4", to: "v7", weight: 9)graphics.addEdge(from: "v5", to: "v2", weight: 7)graphics.addEdge(from: "v5", to: "v4", weight: 3)graphics.addEdge(from: "v5", to: "v7", weight: 5)graphics.addEdge(from: "v6", to: "v3", weight: 3)graphics.addEdge(from: "v6", to: "v4", weight: 6)graphics.addEdge(from: "v6", to: "v7", weight: 2)graphics.addEdge(from: "v6", to: "v8", weight: 7)graphics.addEdge(from: "v7", to: "v4", weight: 9)graphics.addEdge(from: "v7", to: "v5", weight: 5)graphics.addEdge(from: "v7", to: "v6", weight: 2)graphics.addEdge(from: "v7", to: "v8", weight: 4)graphics.addEdge(from: "v8", to: "v6", weight: 7)graphics.addEdge(from: "v8", to: "v7", weight: 4)
- 迪杰斯特拉(Dijkstra)算法
从源点开始,找到源点到下一个最短路径的顶点。然后,在之前的基础上,再找下一个最短路径的顶点,直到终点。该算法的时间复杂度为O(n^2)。
func shortestPath_Dijkstra(graphics: Graph<String>) {var final = Array(repeating: 0, count: graphics.vertexes) //final[N]=1,表示求的顶点v0至vN的最短路径var pathArc = Array(repeating: 0, count: graphics.vertexes) //储存最短路径下标前驱的数组var shortPathTable: [Int] = [] //表示v0到各个顶点的最短路径长度for i in 0..<graphics.vertexes {shortPathTable.append(graphics.arc[0][i])}final[0] = 1 //v0-v0不需要求路径//开始求v0到各个顶点的最短路径for _ in 1..<graphics.vertexes {var min = Int.max //当前所知离v0顶点最近的距离var k = 0for w in 0..<graphics.vertexes {if final[w] == 0, shortPathTable[w] < min {k = wmin = shortPathTable[w]}}final[k] = 1//修正最短路径for w in 0..<graphics.vertexes {if final[w] == 0, min < shortPathTable[w]-graphics.arc[k][w]{shortPathTable[w] = min + graphics.arc[k][w]pathArc[w] = k}}}print(final)print(pathArc)print(shortPathTable)}shortestPath_Dijkstra(graphics: graphics)//输出结果[1, 1, 1, 1, 1, 1, 1, 1, 1][0, 0, 1, 4, 2, 4, 3, 6, 7][0, 1, 4, 7, 5, 8, 10, 12, 16]
- 说明:
刚开始final数组为:[1, 0, 0, 0, 0, 0, 0, 0, 0],因为从v0开始,v0算是找到了最短路径;pathArc数组为:[0, 0, 0, 0, 0, 0, 0, 0, 0];shortestPathTable数组为:[0, 1, 5, ∞, ∞, ∞, ∞, ∞, ∞]。因为v0-v1=1 < v0-v2=5,所以,v0下一个最短路径的顶点是v1,这时候final为[1, 1, 0, 0, 0, 0, 0, 0, 0],那么,既然找到了下一个最短路径的顶点v1,那么,和v1相连的顶点路径的权值和shortestPathTable中的权值比较,取较小者的权值。到此,v0-v1以及和v1相连的顶点的较小权值都得到了,继续重复上面的步骤直到终点,就可以得到从v0-v8各个顶点到v0的最小路径了。 - 佛洛伊德(Floyd)算法
关键公式:D[ v ][ w ] = min { D[ v ][ w ] , D[ V ][0] + D[0][W] },主要思想就是:求v1到v2经过最短路径,有v1->v2,v1->v0->v2,则v1->v2的最短路径为两者最短的路径。以此类推,在其基础上求v1-v3的路径也是一样的。算法时间复杂度为O(n^3)。
//佛洛伊德算法func ShortestPath_Floyd(graphics: Graph<String>) {//初始化矩阵var pathmatirx: [[Int]]var shortPathTable: [[Int]] = graphics.arcvar rowValue: [Int] = []for i in 0..<graphics.vertexes {rowValue.append(i)}pathmatirx = Array(repeating: rowValue, count: graphics.vertexes)//开始算法for k in 0..<graphics.vertexes {for v in 0..<graphics.vertexes {for w in 0..<graphics.vertexes {if shortPathTable[v][k] < Int.max, shortPathTable[k][w] < Int.max, shortPathTable[v][w] > shortPathTable[v][k] + shortPathTable[k][w] {shortPathTable[v][w] = shortPathTable[v][k] + shortPathTable[k][w]pathmatirx[v][w] = pathmatirx[v][k]}}}}//打印最短路径var k = 0for v in 0..<graphics.vertexes {for w in v+1..<graphics.vertexes {print("v\(v)-v\(w) weight: \(shortPathTable[v][w])")k = pathmatirx[v][w]print("path: \(v)")while k != w {print(" -> \(k)")k = pathmatirx[k][w]}print(" -> \(w)")}print("\n")}}ShortestPath_Floyd(graphics: graphics)//输出结果[0, 1, 4, 7, 5, 8, 10, 12, 16] //v0达到各顶点的最短路径[1, 0, 3, 6, 4, 7, 9, 11, 15][4, 3, 0, 3, 1, 4, 6, 8, 12][7, 6, 3, 0, 2, 5, 3, 5, 9][5, 4, 1, 2, 0, 3, 5, 7, 11][8, 7, 4, 5, 3, 0, 7, 5, 9][10, 9, 6, 3, 5, 7, 0, 2, 6][12, 11, 8, 5, 7, 5, 2, 0, 4][16, 15, 12, 9, 11, 9, 6, 4, 0]//前驱矩阵[0, 1, 1, 1, 1, 1, 1, 1, 1][0, 1, 2, 2, 2, 2, 2, 2, 2][1, 1, 2, 4, 4, 4, 4, 4, 4][4, 4, 4, 3, 4, 4, 6, 6, 6][2, 2, 2, 3, 4, 5, 3, 3, 3][4, 4, 4, 4, 4, 5, 7, 7, 7][3, 3, 3, 3, 3, 7, 6, 7, 7][6, 6, 6, 6, 6, 5, 6, 7, 8][7, 7, 7, 7, 7, 7, 7, 7, 8]
- 说明:获取v0->v8的最短路径,则P[0][8] = 1,P[1][8] = 2,P[2][8] = 4,P[4][8] = 3,P[3][8] = 6,P[6][8] = 7,P[7][8] = 8,所以,v0->v8的最短路径为:v0->v1->v2->v4->v3->v6->v7-V8。
- 两个算法总结:
如果只需求其中两个顶点之间的最短路径,采用迪杰斯特拉算法;如果需要求所有顶点到所有顶点的最短路径,可以采用佛洛依德算法,虽然,两个算法计算所有顶点到所有顶点的最短路径的时间复杂度都是O(n^3),但是佛洛依德算法比较简洁,不易出错。
拓扑结构
在一个表示工程的有向图中,用顶点表示活动,用弧表示活动之间的优先关系,这样的有向图表示的网,称为AOV网(Activity On vertex Network)。假设G=(V,E)是一个具有n个顶点的有向图,V中的顶点序列v1, v2, v3, …… , Vn,满足若从顶点vi到vj有一条路径,则中顶点序列中顶点vi必须在vj之前,我们称这样的顶点序列为一个拓扑序列。拓扑排序,就是对一个有向图构造拓扑序列的过程。拓扑序列的主要作用是确定一个有向图确定的有序序列,比如:iOS开发使用拓扑序列来整理整个工程的文件依赖,比如检查循环依赖,比如确认从那个依赖文件开始编译等等。两个特点:1.无环有向图 2.两个顶点之间的方向只有一个。
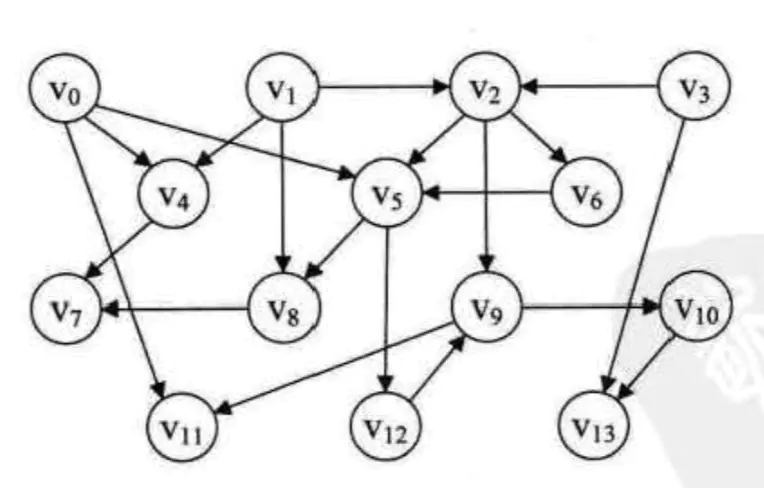
AVO图.png
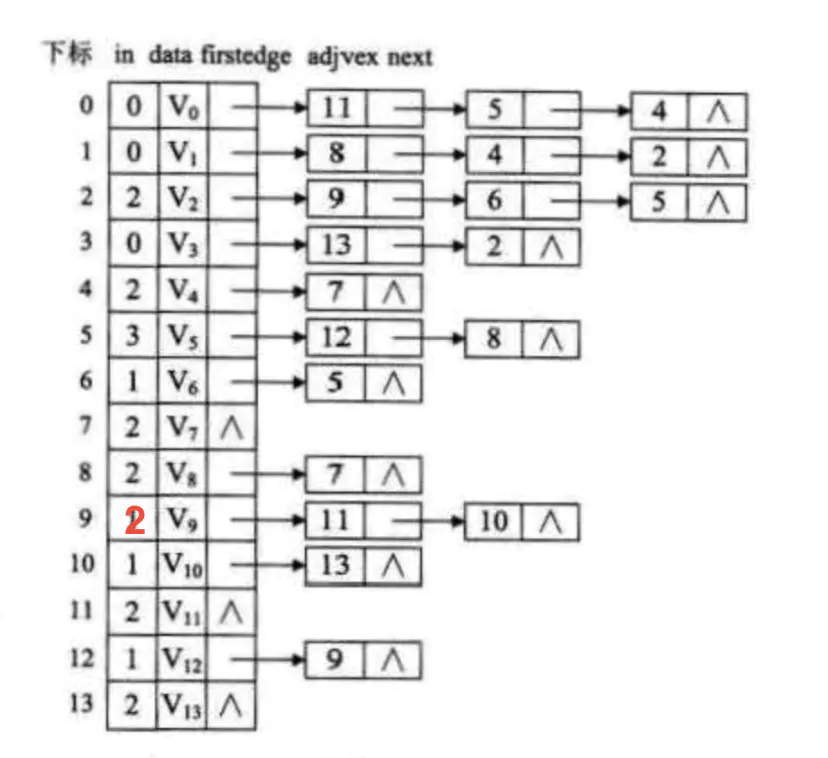
AVO图链表表示.png
extension Int {static func += (left: inout Int, right: Int) {left = left + right}static func -= (left: inout Int, right: Int) {left = left - right}}//边表结点class EdgeNode {var adjex = 0var weight = 1var next: EdgeNode?}//顶点表结点class VertexNode {var inEdge = 0var data = 0var firstEdge: EdgeNode?}class GraphAdjList {var adjList: [VertexNode] = []var numEdges = 0var numVertexes : Int {return adjList.count}}let graphiAdjList = GraphAdjList()//V0let v0 = VertexNode()v0.inEdge = 0v0.data = 0let v0E11 = EdgeNode()v0E11.adjex = 11let v0E5 = EdgeNode()v0E5.adjex = 5let v0E4 = EdgeNode()v0E4.adjex = 4v0.firstEdge = v0E11v0E11.next = v0E5v0E5.next = v0E4//V1let v1 = VertexNode()v1.inEdge = 0v1.data = 1let v1E8 = EdgeNode()v1E8.adjex = 8let v1E4 = EdgeNode()v1E4.adjex = 4let v1E2 = EdgeNode()v1E2.adjex = 2v1.firstEdge = v1E8v1E8.next = v1E4v1E4.next = v1E2//V2let v2 = VertexNode()v2.inEdge = 2v2.data = 2let v2E9 = EdgeNode()v2E9.adjex = 9let v2E6 = EdgeNode()v2E6.adjex = 6let v2E5 = EdgeNode()v2E5.adjex = 5v2.firstEdge = v2E9v2E9.next = v2E6v2E6.next = v2E5//V3let v3 = VertexNode()v3.inEdge = 0v3.data = 3let v3E13 = EdgeNode()v3E13.adjex = 13let v3E2 = EdgeNode()v3E2.adjex = 2v3.firstEdge = v3E13v3E13.next = v3E2//V4let v4 = VertexNode()v4.inEdge = 2v4.data = 4let v4E7 = EdgeNode()v4E7.adjex = 7v4.firstEdge = v4E7//V5let v5 = VertexNode()v5.inEdge = 3v5.data = 5let v5E12 = EdgeNode()v5E12.adjex = 12let v5E8 = EdgeNode()v5E8.adjex = 8v5.firstEdge = v5E12v5E12.next = v5E8//V6let v6 = VertexNode()v6.inEdge = 1v6.data = 6let v6E5 = EdgeNode()v6E5.adjex = 5v6.firstEdge = v6E5//V7let v7 = VertexNode()v7.inEdge = 2v7.data = 7//V8let v8 = VertexNode()v8.inEdge = 2v8.data = 8let v8E7 = EdgeNode()v8E7.adjex = 7v8.firstEdge = v8E7//V9let v9 = VertexNode()v9.inEdge = 2v9.data = 9let v9E11 = EdgeNode()v9E11.adjex = 11let v9E10 = EdgeNode()v9E10.adjex = 10v9.firstEdge = v9E11v9E11.next = v9E10//V10let v10 = VertexNode()v10.inEdge = 1v10.data = 10let v10E13 = EdgeNode()v10E13.adjex = 13v10.firstEdge = v10E13//V11let v11 = VertexNode()v11.inEdge = 2v11.data = 11//V12let v12 = VertexNode()v12.inEdge = 1v12.data = 12let v12E9 = EdgeNode()v12E9.adjex = 9v12.firstEdge = v12E9//V13let v13 = VertexNode()v13.inEdge = 2v13.data = 13graphiAdjList.adjList.append(v0)graphiAdjList.adjList.append(v1)graphiAdjList.adjList.append(v2)graphiAdjList.adjList.append(v3)graphiAdjList.adjList.append(v4)graphiAdjList.adjList.append(v5)graphiAdjList.adjList.append(v6)graphiAdjList.adjList.append(v7)graphiAdjList.adjList.append(v8)graphiAdjList.adjList.append(v9)graphiAdjList.adjList.append(v10)graphiAdjList.adjList.append(v11)graphiAdjList.adjList.append(v12)graphiAdjList.adjList.append(v13)func toPologicalSort(gl: GraphAdjList) {var count = 0, top = 0, k = 0, getTop = 0var stack: [Int] = []//将有向图所有入度为0的顶点入栈for i in 0..<gl.numVertexes {if gl.adjList[i].inEdge == 0 {stack.append(i)top += 1}}//开始算拓扑序列while top != 0 {getTop = stack.removeLast()top -= 1print("vertex: \(gl.adjList[getTop].data)")count += 1var edgeNode = gl.adjList[getTop].firstEdgewhile edgeNode != nil {k = (edgeNode?.adjex)!gl.adjList[k].inEdge -= 1if gl.adjList[k].inEdge == 0 {stack.append(k)top += 1}edgeNode = edgeNode?.next}}if count < gl.numVertexes {print("Error")} else {print("OK")}}toPologicalSort(gl: graphiAdjList)//输出结果vertex: 3vertex: 1vertex: 2vertex: 6vertex: 0vertex: 4vertex: 5vertex: 8vertex: 7vertex: 12vertex: 9vertex: 10vertex: 13vertex: 11
- 拓扑排序并不是唯一的
- 拓扑排序简要说明:
1.先找到所有入度为0的顶点,并依次进栈。
2.从栈顶开始,出栈;然后,遍历该栈顶元素的链表,每个顶点的入度减1,判断每个顶点的入度是否为0,如果为0则入栈,否则跳过。
3.判断栈是否还有元素,如果栈不为空,则回到第2步,否则,结束。
关键路径
拓扑排序解决一个工程能否顺利进行的问题,那么,关键路径就是解决工程完成需要的最短时间问题。在一个表示工程的带权有向图中,用顶点表示事件,用有向边表示活动,用边上的权值表示活动的持续时间,这种有向图的边表示活动的网,我们称之为 AOE网 (Activity On Edge Network) 。 我们把AOE网中没有人边的顶点称为始点或源点,没有出边的顶点称为终点或汇点。我们把路径上各个活动所持续的时间之和称为路径长度,从源点到汇点具有最大长度的路径叫关键路径,在关键路径上的活动叫关键活动。
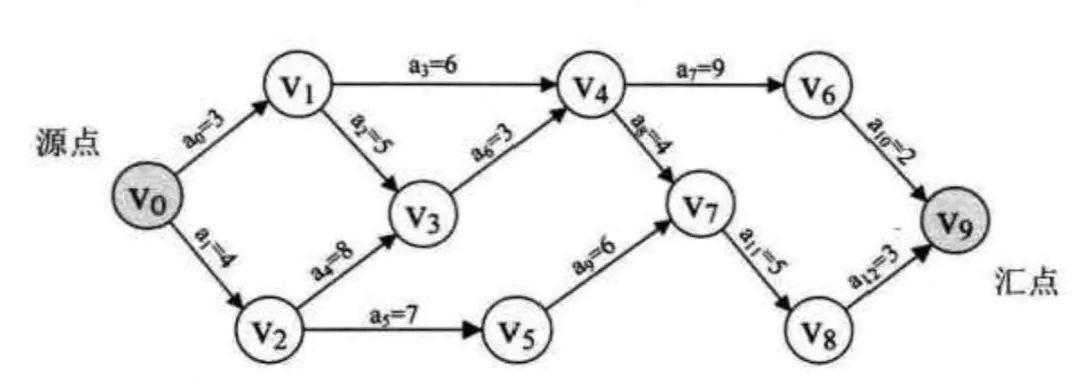
AOE图.png
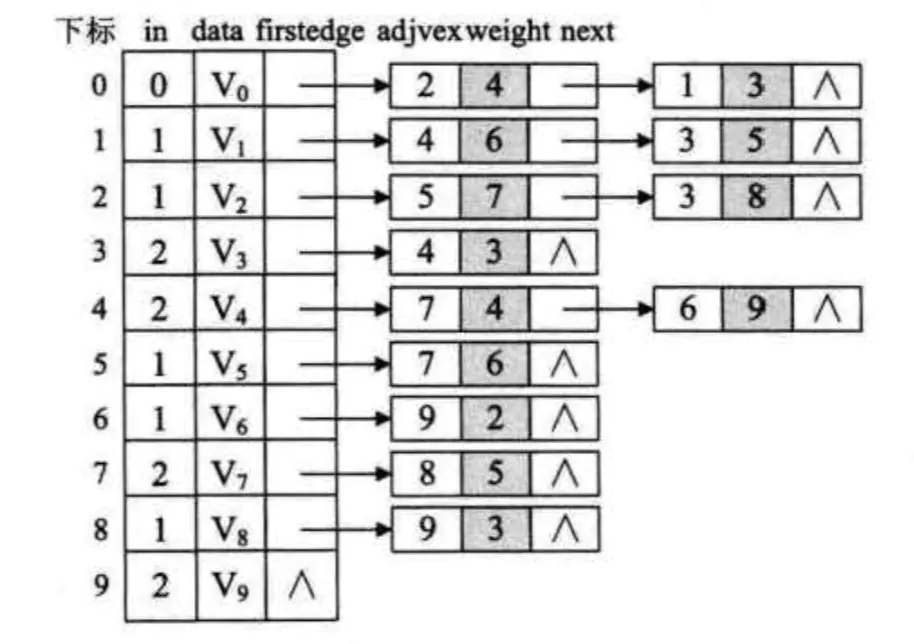
AOE链表显示.png
//V0let v0 = VertexNode()v0.inEdge = 0v0.data = 0let v0E2 = EdgeNode()v0E2.adjex = 2v0E2.weight = 4let v0E1 = EdgeNode()v0E1.adjex = 1v0E1.weight = 3v0.firstEdge = v0E2v0E2.next = v0E1//V1let v1 = VertexNode()v1.inEdge = 1v1.data = 1let v1E4 = EdgeNode()v1E4.adjex = 4v1E4.weight = 6let v1E3 = EdgeNode()v1E3.adjex = 3v1E3.weight = 5v1.firstEdge = v1E4v1E4.next = v1E3//V2let v2 = VertexNode()v2.inEdge = 1v2.data = 2let v2E5 = EdgeNode()v2E5.adjex = 5v2E5.weight = 7let v2E3 = EdgeNode()v2E3.adjex = 3v2E3.weight = 8v2.firstEdge = v2E5v2E5.next = v2E3//V3let v3 = VertexNode()v3.inEdge = 2v3.data = 3let v3E4 = EdgeNode()v3E4.adjex = 4v3E4.weight = 3v3.firstEdge = v3E4//V4let v4 = VertexNode()v4.inEdge = 2v4.data = 4let v4E7 = EdgeNode()v4E7.adjex = 7v4E7.weight = 4let v4E6 = EdgeNode()v4E6.adjex = 6v4E6.weight = 9v4.firstEdge = v4E7v4E7.next = v4E6//V5let v5 = VertexNode()v5.inEdge = 1v5.data = 5let v5E7 = EdgeNode()v5E7.adjex = 7v5E7.weight = 6v5.firstEdge = v5E7//V6let v6 = VertexNode()v6.inEdge = 1v6.data = 6let v6E9 = EdgeNode()v6E9.adjex = 9v6E9.weight = 2v6.firstEdge = v6E9//V7let v7 = VertexNode()v7.inEdge = 2v7.data = 7let v7E8 = EdgeNode()v7E8.adjex = 8v7E8.weight = 5v7.firstEdge = v7E8//V8let v8 = VertexNode()v8.inEdge = 1v8.data = 8let v8E9 = EdgeNode()v8E9.adjex = 9v8E9.weight = 3v8.firstEdge = v8E9//V9let v9 = VertexNode()v9.inEdge = 2v9.data = 9let graphiAdjList = GraphAdjList()graphiAdjList.adjList.append(v0)graphiAdjList.adjList.append(v1)graphiAdjList.adjList.append(v2)graphiAdjList.adjList.append(v3)graphiAdjList.adjList.append(v4)graphiAdjList.adjList.append(v5)graphiAdjList.adjList.append(v6)graphiAdjList.adjList.append(v7)graphiAdjList.adjList.append(v8)graphiAdjList.adjList.append(v9)//etv(earliest time of vertex) => 顶点V的最早发生时间//ltv(latest time of vertex) => 顶点V的最迟发生时间//ete(earliest time of edge) => 弧a的最早发生时间//lte(latest time of edge) => 弧a的最迟发生时间var etv: [Int] = Array(repeating: 0, count: graphiAdjList.numVertexes)var ltv: [Int] = []var stack2: [Int] = []var top2 = 0func TopologicalSort(gl: GraphAdjList) {var count = 0, top = 0, k = 0, getTop = 0var stack: [Int] = []//将有向图所有入度为0的顶点入栈for i in 0..<gl.numVertexes {if gl.adjList[i].inEdge == 0 {stack.append(i)top += 1}}//开始算拓扑序列while top != 0 {getTop = stack.removeLast()top -= 1count += 1/////////////////////stack2.append(getTop) //添加入度为0的顶点top2 += 1////////////////////var edgeNode = gl.adjList[getTop].firstEdgewhile edgeNode != nil {k = (edgeNode?.adjex)!gl.adjList[k].inEdge -= 1if gl.adjList[k].inEdge == 0 {stack.append(k)top += 1}/////////////////////////////////////////////if etv[getTop]+(edgeNode?.weight)! > etv[k] { //顶点的最早发生时间,即到达这个顶点之前最大的花费时间etv[k] = etv[getTop]+(edgeNode?.weight)!}/////////////////////////////////////////////edgeNode = edgeNode?.next}}if count < gl.numVertexes {print("Error")} else {print("OK")}}func CriticalPath(gl: GraphAdjList) {var getTop = 0, k = 0var ete = 0, lte = 0TopologicalSort(gl: gl) //求拓扑序列,计算数组etv和stack2// etv: [0, 3, 4, 12, 15, 11, 24, 19, 24, 27]//stack2: [v0, v1, v2, v3, v4, v5, v6, v7, v8, v9]for _ in 0..<gl.numVertexes {ltv.append(etv[gl.numVertexes-1]) //初始化ltv为27}while top2 != 0 {getTop = stack2.removeLast()top2 -= 1var edgeNode = gl.adjList[getTop].firstEdgewhile edgeNode != nil {k = (edgeNode?.adjex)!if ltv[k]-(edgeNode?.weight)! < ltv[getTop] {ltv[getTop] = ltv[k]-(edgeNode?.weight)! //取最小值,才不会影响该顶点到达其他顶点的时间,也就是最迟发生的时间}edgeNode = edgeNode?.next}}for j in 0..<gl.numVertexes {var edgeNode = gl.adjList[j].firstEdgewhile edgeNode != nil {k = (edgeNode?.adjex)!ete = etv[j]lte = ltv[k]-(edgeNode?.weight)!if ete == lte {print("<\(gl.adjList[j].data), \(gl.adjList[k].data) length: \((edgeNode?.weight)!)>")}edgeNode = edgeNode?.next}}}输出结果:<0, 2 length: 4><2, 3 length: 8><3, 4 length: 3><4, 7 length: 4><7, 8 length: 5><8, 9 length: 3>
- 关键点:
1.etv的计算:比如计算v9点最早开始的时间,那么需要计算终点是v9的所有点的权值,取最大的权值,是因为,在这个点开始,v9之前的所有活动都刚刚结束,也就是说保证v9之前所有活动完成之后才是v9最早开始的时间。
etv计算公式.png
2.ltv的计算:由etv可以知道终点的最早开始时间,那么所有点以这个为初始值,因为最迟开始的时间不可能大于终点最早的开始时间。那么,ltv的计算从终点开始,往回推。比如说要计算v8最迟开始的时间,因为v8需要3天时间工作,那么在保证v8工作完成时不影响v9的工作,那么v8最迟开始的工作时间就是v9最早工作时间减去v8需要的时间。比如说v4,经过v4会到达多个顶点,需要保证不影响所达到的多个的工作时间,那么v4开始的时间就是v4所经过的过个顶点最早的开始时间分别减去v4所需要的时间,取最小的开始时间,才会不影响之后所有的顶点的最早开始时间。

ltv计算公式.png
3.ete本来是表示活动
的。但只有此弧的弧尾顶点vk的事件发生了,它才可以开始,因此 ete=etv[k];lte 表示的是活动
总结:
写这个数据结果,断断续续奋战了几个星期,总算一点一点的把它啃完。敲代码的基础很重要,就像盖房子一样,基础不牢固,建不起高楼大厦。后面会继续推出,算法,设计模式,编译原理,操作系统等等一些列的学习笔记。这世界很大,需要保持一点好奇心😄。最后,献上Demo。

若有收获,就点个赞吧
0 人点赞
