一、全局命令
以下指令对5中数据类型都有效,统计查看类型的会把5种数据类型全部统计进去,操作类型指令对5中数据类型都有效。
- 查看所有键:keys *
- 键总数 dbsize //2个键,如果存在大量键,线上禁止使用此指令
- 检查键是否存在:exists key //存在返回1,不存在返回0
- 删除键:del key //del hello school, 可以一次删除多个键,返回删除键个数,删除不存在键返回0
- 键过期:expire key seconds //set name test expire name 10 //10秒过期
- ttl key 查看剩余的过期时间,单位是秒,永久有效返回-1,已失效或不存在返回-2
- 键的数据结构类型:type key //type hello //返回string,键不存在返回none
二、redis键管理
1、键重命名
格式: rename oldKey newKey //若oldKey之前存在则被覆盖
set name james ;set name1 mike //数据初始化renamenx name name1 //重命名失败,只有当name1不存在才能改名renamenx name name2 //重命名成功
2、键过期
格式:
a、expire key seconds
seconds设置为-2表示直接过期和del一样的效果
expire name:03 20 //键name:03 在10秒后过期expire name:06 -2 //直接过期,和del一样
b、pexpire key milliseconds
设置键过期时间,单位为毫秒
pexpire name:05 20000 //20000毫秒(20S)后过期
c、expireat key timestamp
设置键过期时间,单位是时间戳
expireat name:04 1516971599 //设置在2018/01/26 20:59:59过期
3、取消键过期
格式: persist key
persist user:01 //去掉过期
4、查看键有效时间
ttl name:03 //查看过期按秒到计时,当返回-2说明已删除pttl name:03 //查看过期按毫秒到时计
注意: 对于字符串重设值后,expire无效,
set name jamesexpire name 50ttl nameset name james1 //此时expire取消ttl name //返回-1, 长期有效
5、键的迁移:把部分数据迁移到另一台redis服务器
1, 格式: move key db //reids有16个库, 编号为0-15
set name james1;move name 5 //迁移到第6个库select 5 //数据库切换到第6个库,get name //可以取到james1
补充:这种模式不建议在生产环境使用,在同一个reids里可以玩
2, dump和restore的配合使用
格式:
dump name //得到name的持久化存储格式数据
restore key ttl value//实现不同redis实例的键迁移,ttl=0代表没有过期时间
例子:在A服务器上 192.168.1.111
set name james;dump name; // 得到"\x00\x05james\b\x001\x82;f\"DhJ"
在B服务器上:192.168.1.118
restore name 0 "\x00\x05james\b\x001\x82;f\"DhJ"get name //返回james
6、键的遍历
//数据初始化mset country china city bj name james //设置3个字符串键值对keys * //返回所有的键, *匹配任意字符多个字符keys *y //以结尾的键keys n*e //以n开头以e结尾,返回namekeys n?me // ?问号代表只匹配一个字符 返回name,全局匹配keys n?m* //返回namekeys [j,l]* //返回以j l开头的所有键 keys [j]ames 全量匹配james
注意: 考虑到是单线程, 在生产环境不建议使用,如果键多可能会阻塞
7、渐进式遍历
mset a a b b c c d d e e f f g g h h i i j j k k l l m m n n o o p p q q r r s s t t u u v v w w x x y y z z //初始化26个字母键值对
字符串类型:
SCAN命令用于迭代当前数据库中的数据库键。
返回结果为:用于下一次迭代的新游标18;所有被迭代的元素
如果数据集合不是以哈希表作为底层实现的话,则scan类命令无视count选项,直接返回数据集合中的所有元素
mset n1 1 n2 2 n3 3 n4 4 n5 5 n6 6 n7 7 n8 8 n9 9 n10 10 n11 11 n12 12 n13 13
scan 0 match n //匹配以n开头的键,最大是取10条,第一次scan 0开始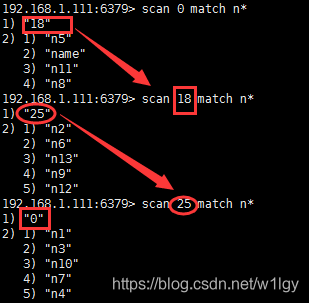
当最后返回0时,键被取完。
这一用法并不是很常用,有兴趣的同学可以去这里看看:http://redisdoc.com/key/scan.html
*注:可有效地解决keys命令可能产生的阻塞问题
除scan字符串外:还有以下
- SCAN 命令用于迭代当前数据库中的数据库键。
- SSCAN 命令用于迭代集合键中的元素。
- HSCAN 命令用于迭代哈希键中的键值对。
- ZSCAN 命令用于迭代有序集合中的元素(包括元素成员和元素分值)。
三、redis数据库管理

1、select
一个redis共16个库, 0 -15, 可以用select切换数据库;eg:
set name jamesselect 1get name //隔离了,取不到,和mysql不同库一样
补充:其中redis3.0以后的版本慢慢弱化了这个功能,如在redis cluster中只允许0数据库
原因:
- redis单线程,如果用多个库,这些库使用同一个CPU,彼此会有影响
- 多数据库,调试与运维麻烦,若有一个慢查询,会影响其它库查询速度
- 来回切换,容易混乱
2、flushdb: 只清空当前数据库的键值对(慎用!!!!)
3、flushall: 清空所有库的键值对 (慎用!!!!)
四、单线程架构
效率极高
redis的命令执行是用单线程的模式,这种模式的效率非常高,这也是redis能处理那么多并发,运行那么快,这么火爆的原因。
而这种模式快的原因是:纯内存访问, 非阻塞I/O(使用多路复用),单线程避免线程切换和竞争产生资源消耗。对此理解不了的同学可以去看一下我之前写的nio的博客:Netty之前篇——NIO基础,和Netty,特别是前一篇,你看完这两篇博客就能非常清楚的了解redis这种模式为什么快了。
弊病
但是这种模式也会有弊病,因为是单线程,执行某个命令,会造成其它命令的阻塞,所以如果在生产环境指行了某个非常耗时的指令,例如:keys * ,那么可能就会造成连锁反应带来灾难。
过程如下:keys * 指令非常耗时,一直在执行,造成其它命令的阻塞,并发量大会造成缓存服务器奔溃,并且大量的请求在redis请求不到结果会到MySQL等本地关系型数据库查询,造成MySQL服务器的奔溃,进而可能造成整个分布式集群系统的奔溃。
前几天就有某公司的工程师执行了keys * 指令导致公司损失了400万,一个小小的指令就有这么大的威力,所以这些耗时指令千万不要在生产环境中使用。
列举例子:三个客户端同时执行命令
客户端1:set name test客户端2:incr num客户端3:incr num
执行过程:发送指令-〉执行命令-〉返回结果
执行命令:单线程执行,所有命令进入队列,按顺序执行,使用I/O多路复用解决I/O问题,后面有介绍(通过select/poll/epoll/kqueue这些I/O多路复用函数库,我们解决了一个线程处理多个连接的问题)

若有收获,就点个赞吧
0 人点赞
