redis是一种基于键值对(key-value)的内存数据库,redis数据结构可以分为string、hash、list、set、sorted set。
1. redis的五种数据结构和相关指令之String
字符串string
redis的字符串不限存储格式,实际上可以是字符串(包括XML JSON),还有数字(整形 浮点数),二进制(图片 音频 视频),最大不能超过512MB。
a、基本命令
- SET:为一个key设置value,可以配合EX/PX参数指定key的有效期,通过NX/XX参数针对key是否存在的情况进行区别操作,时间复杂度O(1)
- GET:获取某个key对应的value,时间复杂度O(1)
- GETSET:为一个key设置value,并返回该key的原value,时间复杂度O(1)
- MSET:为多个key设置value,时间复杂度O(N)
- MSETNX:同MSET,如果指定的key中有任意一个已存在,则不进行任何操作,时间复杂度O(N)
- MGET:获取多个key对应的value,时间复杂度O(N)
eg:
set age 23 ex 10 //10秒后过期 px 10000 毫秒过期setnx name test //不存在键name时,返回1设置成功;存在的话失败0set age 25 xx //存在键age时,返回1成功get age //获值命令:存在则返回value, 不存在返回nilmset country china city beijing //批量设值:mget country city address //批量获取:返回china beigjin, address为nil
补充说明
带“m”的批量指令能减少指令的网络请求时间,提高效率。例如若没有mget命令,则要执行n次get命令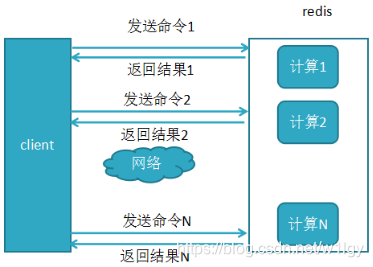
使用mget=1次网络请求+redis内部n次查询
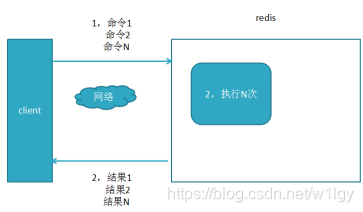
b、数值操作
当string的值为数值的时候就可以进行一些针对数值的增减操作:
incr age //必须为整数自加1,非整数返回错误,无age键从0自增返回1decr age //整数age减1incrby age 2 //整数age+2decrby age 2//整数age -2incrbyfloat score 1.1 //浮点型score+1.1
c、普通字符串操作
追加指令:
set name hello; append name world //追加后成helloworld
字符串长度:
set hello “世界”;strlen hello//结果6,每个中文占3个字节
截取字符串:
set name helloworld ; getrange name 2 4//返回 llo
d、key的使用技巧
- 不要使用过长的Key。例如使用一个1024字节的key就不是一个好主意,不仅会消耗更多的内存,还会导致查找的效率降低
- Key短到缺失了可读性也是不好的,例如”u1000flw”比起”user:1000:followers”来说,节省了寥寥的存储空间,却引发了可读性和可维护性上的麻烦
- 最好使用统一的规范来设计Key,比如”object-type: id:attr”,以这一规范设计出的Key可能是”user:1000″或”comment: 1234:reply-to”
- Redis允许的最大Key长度是512MB(对Value的长度限制也是512MB)
2. redis的五种数据结构和相关指令之Hash
哈希hash
哈希hash是一个string类型的field和value的映射表,hash特适合用于存储对象,用Hash中的field对应对象的field即可。
每个hash对象有三个属性:key、field和value;每个hash对象有一个key值,每个key可以对应多个field,每个field对应一个value。
比如将关系型数据表转成redis存储: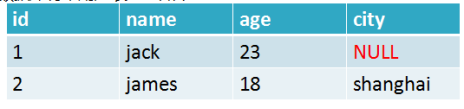
使用hash后的存储方式为: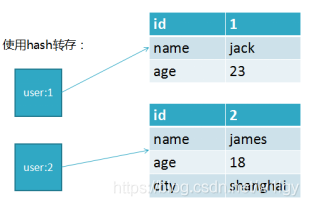
a、基本命令
设值:hset key field value
hset user:1 name james //成功返回1,失败返回0
取值:hget key field
hget user:1 name //返回james
删值:hdel key field
hdel user:1 age //返回删除的个数
计算个数:hlen key
hset user:1 name james; hset user:1 age 23;hlen user:1 //返回2,user:1有两个属性值
批量设值:
hmset user:2 name james age 23 sex boy //返回OK
批量取值:
hmget user:2 name age sex //返回三行:james 23 boy
判断field是否存在:
hexists user:2 name //若存在返回1,不存在返回0
获取所有field,时间复杂度O(N),慎用:
hkeys user:2 // 返回name age sex三个field
获取user:2所有value,时间复杂度O(N),慎用:
hvals user:2 // 返回james 23 boy
获取user:2所有field与value,时间复杂度O(N),慎用:
hgetall user:2 //name age sex james 23 boy值
增加数值:
hincrby user:2 age 1 //age+1hincrbyfloat user:2 age 2 //浮点型加2
b、三种方案实现用户信息存储优缺点:
1、string原生:
set user:1:name james;set user:1:age 23;set user:1:sex boy;
优点: 简单直观,每个键对应一个值
缺点: 键数过多,占用内存多,用户信息过于分散,不用于生产环境
2、将对象序列化存入redis
set user:1 serialize(userInfo);
优点: 编程简单,若使用序列化合理内存使用率高
缺点: 序列化与反序列化有一定开销,更新属性时需要把userInfo全取出来进行反序列化,更新后再序列化到redis
3、使用hash类型:
hmset user:1 name james age 23 sex boy
优点: 简单直观,使用合理可减少内存空间消耗
缺点: 要控制ziplist与hashtable两种编码转换,且hashtable会消耗更多内存
总结: 对于更新不多的情况下,可以使用序列化,对于VALUE值不大于64字节可以使用hash类型
3. redis的五种数据结构和相关指令之List
列表list
Redis的List是链表型的数据结构,用来存储多个有序的字符串,一个列表最多可存2的32次方减1个元素,可以使用LPUSH/RPUSH/LPOP/RPOP等命令在List的两端执行插入元素和弹出元素的操作。虽然List也支持在特定index上插入和读取元素的功能,但其时间复杂度较高(O(N)),应小心使用。
a、常用命令
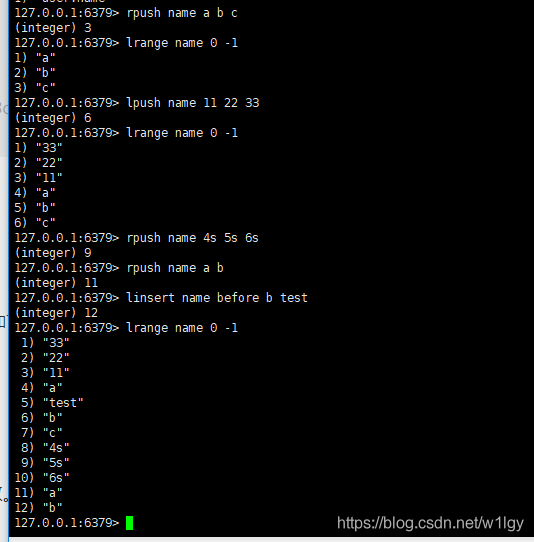
添加命令:
rpush james a b c //从右向左插入cba, 返回值3lrange james 0 -1 //从左到右获取列表所有元素 返回 c b alpush key 11 22 33 //从左向右插入11 22 33linsert james before b test //在b之前插入test, after为之后,如果有相同的元素,以从左到右第一个为准,使用lrange james 0 -1 查看,如下图
查找命令:
lrange key start end //索引下标特点:从左到右为0到N-1lindex key -1 //返回最右末尾a,-2返回bllen key //返回当前列表长度
删除命令
lpop key //把最左边的第一个元素c删除rpop key //把最右边的元素a删除lrem key count value//删除指定元素lrem test 4 b //从左右开始删除b的元素,删除4个,若不够4个则删除已有的ltrim key start endltrim name 1 3 //只保留从第2到第4(下标从0开始)的元素,其它全删
修改
lset key index valuelset name 2 java // 把第3个元素z替换成java
应用场景
每个用户有多个订单key为 order:1 order:2 order:3, 结合hmset
hmset order:1 orderId 1 money 36.6 time 2018-01-01hmset order:2 orderId 2 money 38.6 time 2018-01-01hmset order:3 orderId 3 money 39.6 time 2018-01-01
把订单信息的key放到队列
lpush user:1:order order:1 order:2 order:3
每新产生一个订单,
hmset order:4 orderId 4 money 40.6 time 2018-01-01
追加一个order:4放入队列第一个位置
lpush user:1:order order:4
当需要查询用户订单记录时:
List orderKeys = lrange user:1 0 -1 //查询user:1 的所有订单key值for(Order order: orderKeys){hmget order:1}
4. redis的五种数据结构和相关指令之set
集合set
集合(set)与列表类似,都是用来保存多个字符串,但集合与列表有两点不同:集合中的元素是无序的,因此不能通过索引来操作元素;集合中的元素不能有重复。
一个集合中最多可以存储2^32-1个元素;除了支持常规的增删改查,Redis还支持多个集合取交集、并集、差集。
1、常用命令

查看指令
exists user //检查user键值是否存在smembers user //获取user的所有元素,返回结果无序scard user //返回2,计算元素个数srandmember user 2 //随机返回2个元素,2为元素个数sismember user a //判断元素是否在集合存在,存在返回1,不存在0
增删指令
sadd user a b c//向user插入3个元素,返回3sadd user a b //若再加入相同的元素,则重复无效,返回0srem user a //返回1,删除a元素spop user 2 //随机返回2个元素a b,并将a b从集合中删除
集合的交集
sadd user:1:fav basball fball pqsadd user:2:fav basball fballsinter user:1:fav user:2:fav //求两集合交集, 此时返回basball fballsadd user:3:fav Badminton basball //新增第三个元素sinter user:1:fav user:2:fav user:3:fav //求三个集合的交集,此时返回basball
集合的并集(集合合并去重):
sunion user:1:fav user:2:fav user:3:fav //三集合合并(并集),得到所有有人喜欢的球
集合的差集
sdiff user:1:fav user:2:fav//1和2差集,得到结果pq
将交集、并集、差集的结果保存:
sinterstore、sunionstore、sdiffstore分别对应sinter、sunion、sdiff的功能,只是把它们的结果保存起来
语法为:
sinterstore/sunionstore/sdiffstore destination key [key …]
eg:
sinterstore user:sinfav user:1:fav user:2:fav
5. redis的五种数据结构和相关指令之有序集合sorted set
有序集合sorted set
有序集合与集合一样,元素都不能重复;Sorted Set中的每个元素都需要指派一个分数(score),Sorted Set会根据score对元素进行升序排序。如果多个member拥有相同的score,则以字典序进行升序排序。
常用于排行榜,如视频网站需要对用户上传视频做排行榜,或点赞数与集合有联系,不能有重复的成员。

与LIST和SET对比
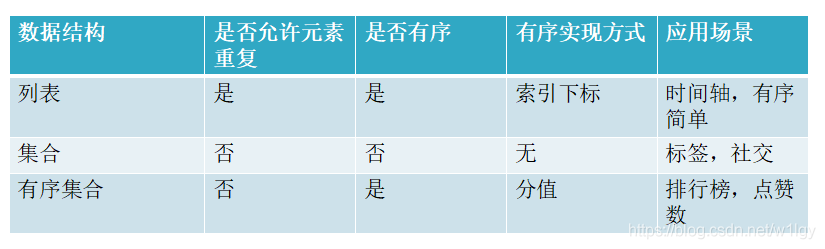
1、常用命令
2、增删指令
添加指令
zadd key [NX|XX] [CH] [INCR] score member [score member…]
- XX: 仅仅更新存在的成员,不添加新成员。
- NX: 不更新存在的成员。只添加新成员。
- CH: 修改返回值为发生变化的成员总数,原始是返回新添加成员的总数 (CH 是 changed 的意思)。更改的元素是新添加的成员,已经存在的成员更新分数。 所以在命令中指定的成员有相同的分数将不被计算在内。注:在通常情况下,ZADD返回值只计算新添加成员的数量,注意: 如果和incr一起使用的时候,返回的会是incr的结果。
- INCR: 当ZADD指定这个选项时,成员的操作就等同ZINCRBY命令,对成员的分数进行递增操作。
zadd user:3 200 james //james的点赞数1, 返回操作成功的条数1zadd user:3 200 james 120 mike 100 lee// 返回3zadd test:1 nx 100 james //键test:1必须不存在,主用于添加zadd test:1 xx incr 200 james //键test:1必须存在,主用于修改,此时为300zadd test:1 xx ch incr -299 james //返回操作结果1,300-299=1zrange test:1 0 -1 withscores //查看点赞(分数)与成员名1234567
增加分数
zincrby user:3 10 lee //成员lee的分数加10zadd user:3 xx incr 10 lee //和上面效果一样
删除指令
zrem user:zan jame mike //返回成功删除2个成员,还剩lee
删除指定排名内的升序元素:
zremrangebyrank user:3 0 1 //分数升序排列,删除第0个与第1个,只剩james
删除指定分数范围的成员
zadd user:5 200 james 120 mike 100 lee//先插入测试数据zremrangebyscore user:5 100 300 //删除分数在100与300范围的成员zremrangebyscore user:5 (100 +inf //删除分数大于100(不包括100),还剩lee
3、查看指令
查看分数
zscore user:3 james //查看james的点赞数(分数),返回200
查看排名
zrank user:3 james //返回名次:第3名返回2,从0开始到2,共3名zrevrank user:3 james //返回0, 反排序,点赞数越高,排名越前
返回指定排名范围的分数与成员
zadd user:4 200 james 120 mike 100 lee//先插入数据zrange user:4 0 -1 withscores //返回结果如下图

zrevrange user:4 0 -1 withscores //倒序,结果如下图

返回指定分数范围的成员
zrangebyscore user:4 110 300 withscores //返回120 lee ,200 James, 由低到高zrevrangebyscore user:4 300 110 withscores //返回200james 120lee,由高到低zrangebyscore user:4 (110 +inf withscores//110到无限大,120mike 200jameszrevrangebyscore user:4 (110 -inf withscores//无限小到110,返回100 lee
返回指定分数范围的成员个数:
zcount user:4 110 300 //返回2,由mike120和james200两条数据
统计成员数量
zcard test:1 //计算成员个数, 返回1
4、有序集合交集
格式:
zinterstore destination numkeys key ... [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]
- destination:交集产生新的元素存储键名称。
- numkeys: 要做交集计算的键个数,匹配不上会有语法错误,会执行不了。
- key :元素键值。
- weights:每个被选中的键对应值乘weight, 默认为1。
初始化数据:
zadd user:7 1 james 2 mike 4 jack 5 kate //初始化user:7数据zadd user:8 3 james 4 mike 4 lucy 2 lee 6 jim //初始化user:8数据
交集例子:
zinterstore user_jj 2 user:7 user:8 aggregate sum //2代表键合并个数,//aggregate sum可加也不可加上,因为默认是sum//结果user_jj:4james(1+3), 6mike(2+4)zinterstore user_jjmax 2 user:7 user:8 aggregate max 或min//取交集最大的分数,返回结果 3james 4mike, min取最小
weights的使用:
zinterstore user_jjweight 2 user:7 user:8 weights 8 4 aggregate max//1,取两个成员相同的交集,user:7->1 james 2 mike; user:8->3 james 4 mike//2,将user:7->james 1*8=8, user:7->mike 2*8 =16, 最后user:7结果 8 james 16 mike;//3,将user:8-> james 3*4=12, user:8->mike 4*4=16,最后user:8结果12 james 16 mike//4,最终相乘后的结果,取最大值为 12 james 16mike//5, zrange user_jjweight 0 -1 withscores 查询结果为 12 james 16mike
5、有序集合并集(合并去重)
格式:
zunionstore destination numkeys key ... [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]
- destination:交集产生新的元素存储键名称
- numkeys: 要做交集计算的键个数 key :元素键值
- weights:每个被选中的键对应值乘weight, 默认为1
eg:
zunionstore user_jjweight2 2 user:7 user:8 weights 8 4 aggregate max//与以上zinterstore一样,只是取并集,指令一样
6、有序集合应用场景
排行榜系统,如视频网站需要对用户上传的视频做排行榜
点赞数:
zadd user:1:20180106 3 mike //mike获得3个赞
再获一赞:
zincrby user:1:20180106 1 mike //在3的基础上加1
用户作弊,将用户从排行榜删掉:
zrem user:1:20180106 mike
展示赞数最多的5个用户:
zrevrangebyrank user:1:20180106 0 4
查看用户赞数与排名:
zscore user:1:20180106 mikezrank user:1:20180106 mike

若有收获,就点个赞吧
0 人点赞
