使用canal client-adapter完成mysql到es数据同步教程
本文为我在学习canal的client-adapter的过程中所记录下来的一些知识点与操作步骤,虽然canal官方也有对应的文档但是我在看官方的文档时感觉官方的wiki有的操作步骤写的不是很清楚,特此记录与君共勉!
官方clientAdapter文档:https://github.com/alibaba/canal/wiki/ClientAdapter
canal的client-adapter是为了让用户能快速的运行canal而开发的一个模块,通过它可以快速地完成从mysql到其他数据源的数据同步功能,本文将演示adapter中elasticsearch部分功能
环境说明
canal 版本
为了体验新功能的特性,这里采用源码的方式进行项目的运行。选择当前master分支的代码进行本地运行(当前时间为2019年8月31号)
mysql版本
mysql采用的是5.7.19版本,运行于docker内。
其运行脚本为:
docker pull mysql:5.7.19docker run -p 3306:3306 -v $PWD/mysql:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=root --name mysql5719 -d mysql:5.7.19# docker中将进入mysql# 查询docker所有容器 docker container ls --all# 查询docker当前运行容器 docker ps# 刚刚启动的时候设置了容器名称mysql5719,-d代表后台运行,使用命令可以进入mysql的docker# 默认账号密码为rootdocker exec -it mysql5719 bash# 退出命令exit
canal环境安装
开启mysql的bin_log
运行时需要注意确保mysql开启了bin_log,因为canal的原理是基于bin_log来实现的。
验证方法为:
mysql> show variables like 'binlog_format';+---------------+-------+| Variable_name | Value |+---------------+-------+| binlog_format | ROW |+---------------+-------+mysql> show variables like 'log_bin';+---------------+-------+| Variable_name | Value |+---------------+-------+| log_bin | ON |+---------------+-------+
如上上面的语句返回的为ROW和ON,则说明是开启了bin_log的
如果没有开启可以参考canal的wiki,地址为:https://github.com/alibaba/canal/wiki/AdminGuide
[mysqld]log-bin=mysql-bin #添加这一行就okbinlog-format=ROW #选择row模式server_id=1 #配置mysql replaction需要定义,不能和canal的slaveId重复
在docker中可通过进入容器的bash进行配置:
docker exec -it mysql5719 bashecho '[mysqld]' >> /etc/mysql/conf.d/mysql.cnfecho 'log-bin=mysql-bin' >> /etc/mysql/conf.d/mysql.cnfecho 'binlog-format=ROW' >> /etc/mysql/conf.d/mysql.cnfecho 'server-id=123454' >> /etc/mysql/conf.d/mysql.cnf
es安装
es选择6.8.1版本,之所以选择6.8.1版本是因为这是目前还算比较靠前的es版本,同时也是许多虚拟云支持的es版本
在这里测试也采用docker来进行安装
脚本为:
docker pull docker.elastic.co/elasticsearch/elasticsearch:6.8.1docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:6.8.1
kibana安装
为方便看到es的数据,这里再安装一个kibana
安装时同样安装在docker内,并让其link到es的容器内。脚本为:
docker pull docker.elastic.co/kibana/kibana:6.8.1docker run --link 41f6e52d3c8b:elasticsearch -p 5601:5601 docker.elastic.co/kibana/kibana:6.8.1# 查询docker所有容器可以看到容器iddocker container ls --all
其中上面的41f6e52d3c8b为elasticsearch的容器id
canal server安装与运行
canal的运行可以直接参考官方的WIKI,其地址为:https://github.com/alibaba/canal/wiki/Docker-QuickStart
下载好canal server
docker pull canal/canal-server
再下载canal的运行脚本
sudo wget https://github.com/alibaba/canal/blob/master/docker/run.sh# 国内无法下载该文件,window中下载下来存为sh脚本# 执行sh ./xxx.sh出现:“Syntax error: “(” unexpected”的解决方法,选nosudo dpkg-reconfigure dash# "line2: $'\r': 未找到命令" , win下的脚本放在liux下执行有问题sudo apt-get install dos2unixdos2unix **.sh
然后根据条件进行启动即可,如我这里的:
run.sh -e canal.instance.master.address=127.0.0.1:3306 \-e canal.destinations=example \-e canal.instance.dbUsername=root \-e canal.instance.dbPassword=root \-e canal.instance.connectionCharset=UTF-8 \-e canal.instance.tsdb.enable=true \-e canal.instance.gtidon=false \-e canal.instance.filter.regex=.*\\\..*
canal.instance.filter.regex参数代表mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠()
常见例子:
mysql 数据解析关注的表,Perl正则表达式. 多个正则之间以逗号(,)分隔,转义符需要双斜杠() 常见例子:
- 所有表:. or .\…*
- canal schema下所有表: canal\…*
- canal下的以canal打头的表:canal.canal.*
- canal schema下的一张表:canal.test1
- 多个规则组合使用:canal\…*,mysql.test1,mysql.test2 (逗号分隔)
环境配置完毕后的验证
- mysql检查3306端口,检查bin_log是否开启
- es检查9200,9300端口是否开启
- kibana检查5601端口是否开启
- canal server检查11111和11112端口是否开启,1.1.4版本的会开启11110端口
如果上面的都没有问题的话,则环境部分OK了
mysql中创建测试库和测试表及数据
为了演示的方便,这里先将mysql的数据创建好,这里简单创建一下:
建库
CREATE SCHEMA `test` ;
建表导数据 ``` SET FOREIGN_KEY_CHECKS=0;
— Table structure for stu_info
DROP TABLE IF EXISTS stu_info;
CREATE TABLE stu_info (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(45) DEFAULT NULL,
age int(11) DEFAULT NULL,
update_time datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
— Records of stu_info
INSERT INTO stu_info VALUES (‘1’, ‘aaa’, ‘11’, ‘2019-08-31 03:23:11’);
INSERT INTO stu_info VALUES (‘2’, ‘bbb’, ‘12’, ‘2019-08-31 04:33:22’);
INSERT INTO stu_info VALUES (‘3’, ‘ccc’, ‘13’, ‘2019-08-31 05:43:33’);
<a name="3c984ecd"></a>#### es索引验证及创建目标索引1. 测试可用性<br />访问kibana,输入查询语句列出目前系统中的所有索引
GET /_cat/indices
2. 创建索引因为es连接采用的是rest客户端,需要先将索引创建好,否则会报错
put mytest_user { “mappings”: { “doc”: { “properties”: { “name”: { “type”: “text” }, “age”: { “type”: “long” }, “update_time”: { “type”: “date” } } } } }
<a name="75deba97"></a>## canal adapter在idea中测试运行这里为了研究canal adapter方便决定在idea中进行运行<br />首选确保idea中已经导入了canal的源码(在1.1.4的下载源码包)<a name="556f1be8"></a>### canal maven install将canal的源码导入到idea中后,找到manven模块中有root的那个模块,然后点击install进行安装<br />也就是下图中的这个:<br />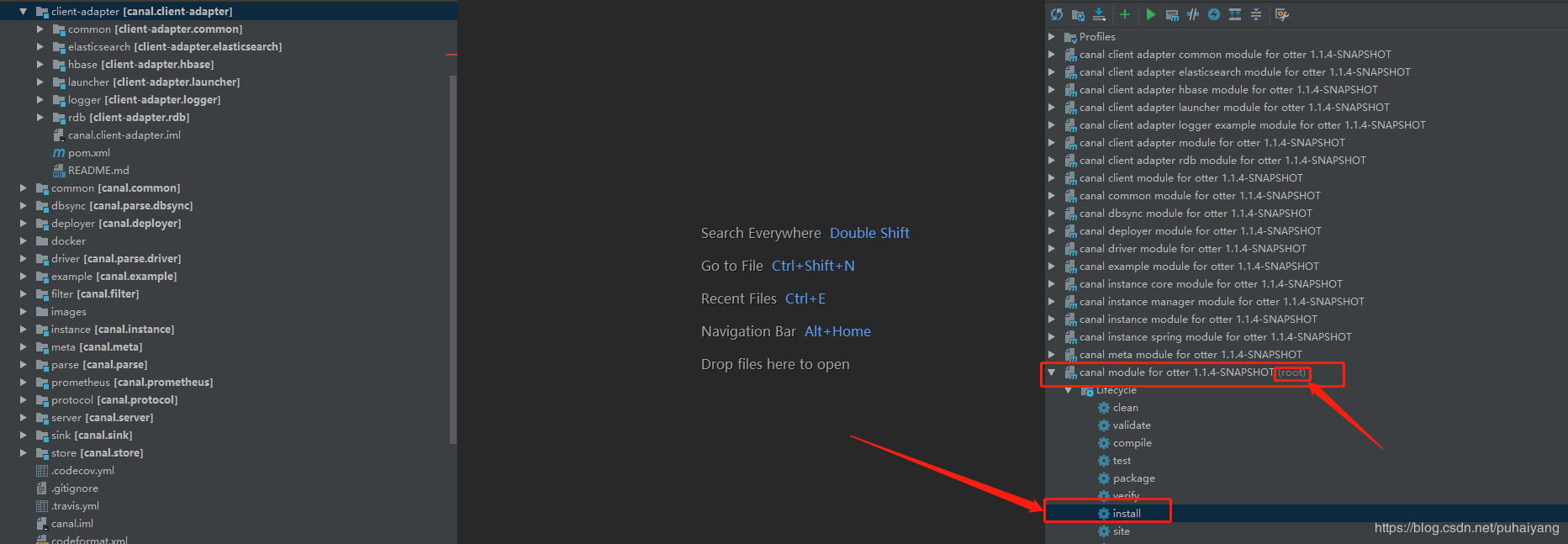<br />待安装完成后,会在对应的项目的target目录下产生相应的运行包,如果不想在开发工具中运行的话,直接拷贝对应的包即可<a name="dddbb060"></a>### canal adapter运行<a name="796b7043"></a>#### launcher的application.yml配置找到canal adapter的模块,修改application.yml配置文件<br />主要修改点为:1. 指定canal server的地址,并采用tcp方式进行连接1. 配置mysql数据源的连接信息1. 开启esAdapter并配置es的连接信息我这里是这样配置的:
server: port: 8081 spring: jackson: date-format: yyyy-MM-dd HH:mm:ss time-zone: GMT+8 default-property-inclusion: non_null
canal.conf: mode: tcp canalServerHost: 192.168.1.66:11111 batchSize: 500 syncBatchSize: 1000 retries: 0 timeout: accessKey: secretKey: srcDataSources: defaultDS: url: jdbc:mysql://192.168.1.66:3306/test?useUnicode=true username: root password: 123456 canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
- name: es hosts: 192.168.1.66:9300 # 127.0.0.1:9200 for rest mode properties: mode: transport # or rest cluster.name: docker-cluster ```
- groupId: g1
outerAdapters:
其中192.168.1.66是运行docker虚拟机的ip地址
es adapter配置
在launcher项目中的配置文件下创建es目录并加入所需要同步的配置文件即可
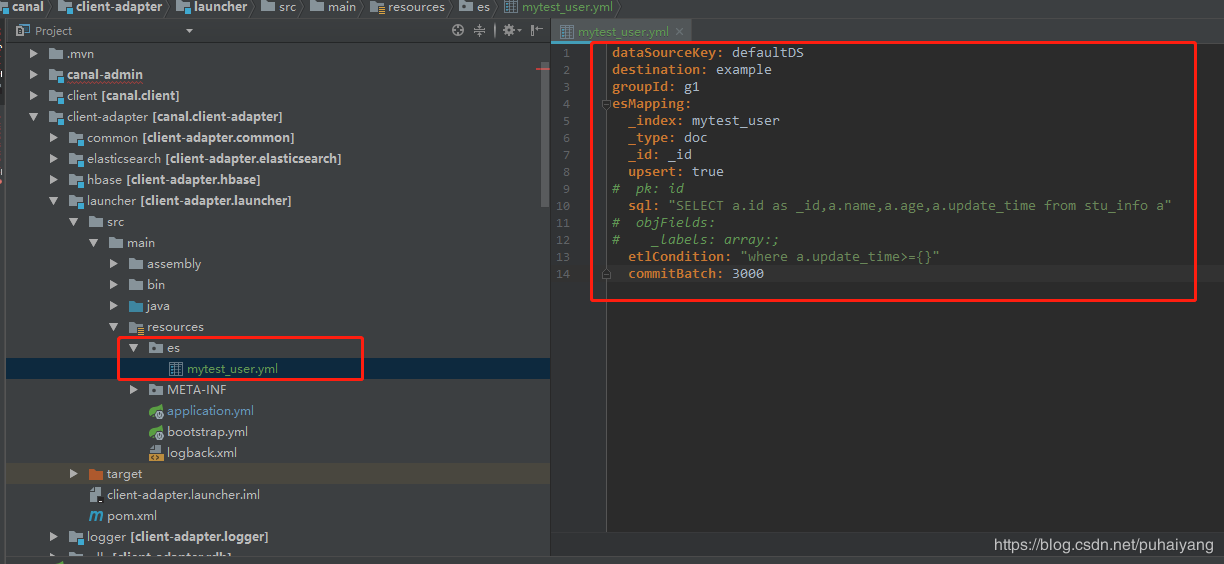
如我这里的mytest_user.yml
dataSourceKey: defaultDSdestination: examplegroupId: g1esMapping:_index: mytest_user_type: doc_id: _idupsert: true# pk: idsql: "SELECT a.id as _id,a.name,a.age,a.update_time from stu_info a"# objFields:# _labels: array:;etlCondition: "where a.update_time>={}"commitBatch: 3000
launcher adapter运行
配置完毕后,直接运行launcher这个springBoot项目即可,也就是运行CanalAdapterApplication这个类就可以了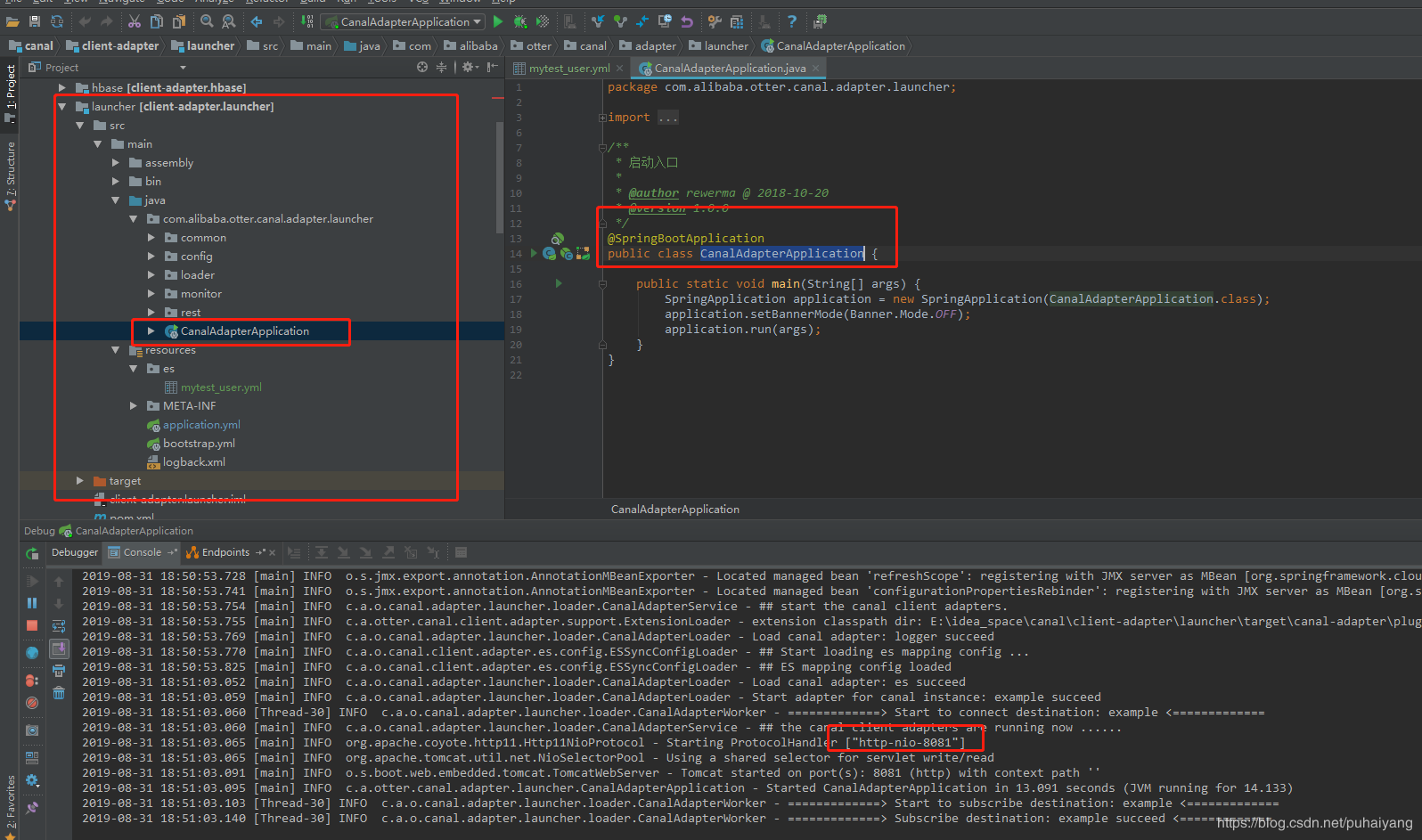
当看日志提示启动成功后就代表启动成功了!
canal测试
当canal adapter启动完毕后就可以进行测试了
canal除了能实现自动增量同步数据的功能外还具有etl的功能
其同步的实现细节会根据数据量的大小自动采用多线程进行同步,也是采用的游标的方式进行查询的,在提高了性能的同时也确保了不容易发生oom,详见博文:canal源码解析之esAdapter etl功能
canal全表同步(etl功能,手动触发)
launcher项目是一个spring boot项目,在其中的rest包下有一个controller类,里面提供了一些接口,其中一个用于全量同步数据的接口
/*** ETL curl http://127.0.0.1:8081/etl/hbase/mytest_person2.yml -X POST** @param type 类型 hbase, es* @param task 任务名对应配置文件名 mytest_person2.yml* @param params etl where条件参数, 为空全部导入*/@PostMapping("/etl/{type}/{task}")public EtlResult etl(@PathVariable String type, @PathVariable String task,@RequestParam(name = "params", required = false) String params) {return etl(type, null, task, params);}
类上也有注释,我们按照注释的内容发送一个http请求即可
curl http://192.168.1.100:8081/etl/es/mytest_user.yml -X POST
其中192.168.1.100为我本地电脑的ip,mytest_user.yml为es目录下的配置文件
运行后就可以让mytest_user.yml配置的数据表的所有数据全同步到es中了.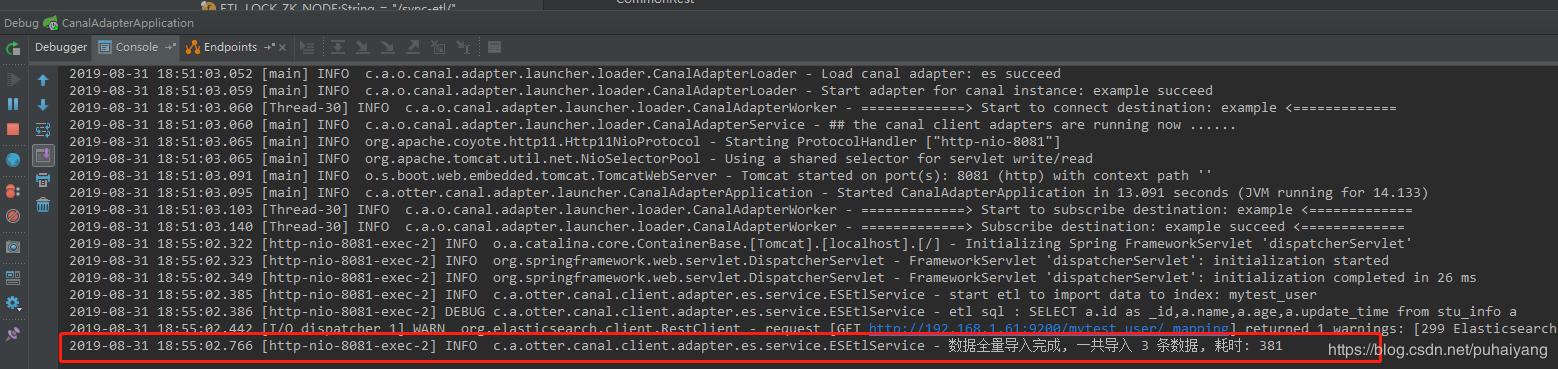
然后再在kibana中看一下es中的数据:
get mytest_user/_search
{"took" : 19,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0},"hits" : {"total" : 3,"max_score" : 1.0,"hits" : [{"_index" : "mytest_user","_type" : "doc","_id" : "2","_score" : 1.0,"_source" : {"name" : "bbb","age" : 12,"update_time" : "2019-08-31T05:43:50+08:00"}},{"_index" : "mytest_user","_type" : "doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "aaa","age" : 13,"update_time" : "2019-08-30T02:43:41+08:00"}},{"_index" : "mytest_user","_type" : "doc","_id" : "3","_score" : 1.0,"_source" : {"name" : "ccc","age" : 11,"update_time" : "2019-08-30T05:39:38+08:00"}}]}}
canal条件同步(etl功能,手动触发)
如果想执行从某一个时刻的数据同步,在上面的测试URL后加上对应的参数就可以了,其参数由es的配置项决定的,也就是上面配置文件中的etlCondition,比如我这里写的where a.update_time>={},而{}之内的就是条件
dataSourceKey: defaultDSdestination: examplegroupId: g1esMapping:_index: mytest_user_type: doc_id: _idupsert: true# pk: idsql: "SELECT a.id as _id,a.name,a.age,a.update_time from stu_info a"# objFields:# _labels: array:;etlCondition: "where a.update_time>={}"commitBatch: 3000
那么如果只想同步stu_info表中update_time为2019-08-31 00:00:00之后的数据,那么这里执行的请求为:
curl http://192.168.1.11:8081/etl/es/mytest_user.yml -X POST -d “params=2019-08-31 00:00:00”
响应为:
{"succeeded":true,"resultMessage":"导入ES 数据:3 条"}root@ubuntu:~# curl http://192.168.1.11:8081/etl/es/mytest_user.yml -X POST -d "params=2019-08-31 00:00:00"{"succeeded":true,"resultMessage":"导入ES 数据:1 条"}root@ubuntu:~#
这个controller的源码如下,想要操作其他功能,也可以自行看源码进行了解:
/*** 适配器操作Rest** @author rewerma @ 2018-10-20* @version 1.0.0*/@RestControllerpublic class CommonRest {private static Logger logger = LoggerFactory.getLogger(CommonRest.class);private static final String ETL_LOCK_ZK_NODE = "/sync-etl/";private ExtensionLoader<OuterAdapter> loader;@Resourceprivate SyncSwitch syncSwitch;@Resourceprivate EtlLock etlLock;@Resourceprivate AdapterCanalConfig adapterCanalConfig;@PostConstructpublic void init() {loader = ExtensionLoader.getExtensionLoader(OuterAdapter.class);}/*** ETL curl http://127.0.0.1:8081/etl/rdb/oracle1/mytest_user.yml -X POST** @param type 类型 hbase, es* @param key adapter key* @param task 任务名对应配置文件名 mytest_user.yml* @param params etl where条件参数, 为空全部导入*/@PostMapping("/etl/{type}/{key}/{task}")public EtlResult etl(@PathVariable String type, @PathVariable String key, @PathVariable String task,@RequestParam(name = "params", required = false) String params) {OuterAdapter adapter = loader.getExtension(type, key);String destination = adapter.getDestination(task);String lockKey = destination == null ? task : destination;boolean locked = etlLock.tryLock(ETL_LOCK_ZK_NODE + type + "-" + lockKey);if (!locked) {EtlResult result = new EtlResult();result.setSucceeded(false);result.setErrorMessage(task + " 有其他进程正在导入中, 请稍后再试");return result;}try {boolean oriSwitchStatus;if (destination != null) {oriSwitchStatus = syncSwitch.status(destination);if (oriSwitchStatus) {syncSwitch.off(destination);}} else {// task可能为destination,直接锁taskoriSwitchStatus = syncSwitch.status(task);if (oriSwitchStatus) {syncSwitch.off(task);}}try {List<String> paramArray = null;if (params != null) {paramArray = Arrays.asList(params.trim().split(";"));}return adapter.etl(task, paramArray);} finally {if (destination != null && oriSwitchStatus) {syncSwitch.on(destination);} else if (destination == null && oriSwitchStatus) {syncSwitch.on(task);}}} finally {etlLock.unlock(ETL_LOCK_ZK_NODE + type + "-" + lockKey);}}/*** ETL curl http://127.0.0.1:8081/etl/hbase/mytest_person2.yml -X POST** @param type 类型 hbase, es* @param task 任务名对应配置文件名 mytest_person2.yml* @param params etl where条件参数, 为空全部导入*/@PostMapping("/etl/{type}/{task}")public EtlResult etl(@PathVariable String type, @PathVariable String task,@RequestParam(name = "params", required = false) String params) {return etl(type, null, task, params);}/*** 统计总数 curl http://127.0.0.1:8081/count/rdb/oracle1/mytest_user.yml** @param type 类型 hbase, es* @param key adapter key* @param task 任务名对应配置文件名 mytest_person2.yml* @return*/@GetMapping("/count/{type}/{key}/{task}")public Map<String, Object> count(@PathVariable String type, @PathVariable String key, @PathVariable String task) {OuterAdapter adapter = loader.getExtension(type, key);return adapter.count(task);}/*** 统计总数 curl http://127.0.0.1:8081/count/hbase/mytest_person2.yml** @param type 类型 hbase, es* @param task 任务名对应配置文件名 mytest_person2.yml* @return*/@GetMapping("/count/{type}/{task}")public Map<String, Object> count(@PathVariable String type, @PathVariable String task) {return count(type, null, task);}/*** 返回所有实例 curl http://127.0.0.1:8081/destinations*/@GetMapping("/destinations")public List<Map<String, String>> destinations() {List<Map<String, String>> result = new ArrayList<>();Set<String> destinations = adapterCanalConfig.DESTINATIONS;for (String destination : destinations) {Map<String, String> resMap = new LinkedHashMap<>();boolean status = syncSwitch.status(destination);String resStatus;if (status) {resStatus = "on";} else {resStatus = "off";}resMap.put("destination", destination);resMap.put("status", resStatus);result.add(resMap);}return result;}/*** 实例同步开关 curl http://127.0.0.1:8081/syncSwitch/example/off -X PUT** @param destination 实例名称* @param status 开关状态: off on* @return*/@PutMapping("/syncSwitch/{destination}/{status}")public Result etl(@PathVariable String destination, @PathVariable String status) {if (status.equals("on")) {syncSwitch.on(destination);logger.info("#Destination: {} sync on", destination);return Result.createSuccess("实例: " + destination + " 开启同步成功");} else if (status.equals("off")) {syncSwitch.off(destination);logger.info("#Destination: {} sync off", destination);return Result.createSuccess("实例: " + destination + " 关闭同步成功");} else {Result result = new Result();result.setCode(50000);result.setMessage("实例: " + destination + " 操作失败");return result;}}/*** 获取实例开关状态 curl http://127.0.0.1:8081/syncSwitch/example** @param destination 实例名称* @return*/@GetMapping("/syncSwitch/{destination}")public Map<String, String> etl(@PathVariable String destination) {boolean status = syncSwitch.status(destination);String resStatus;if (status) {resStatus = "on";} else {resStatus = "off";}Map<String, String> res = new LinkedHashMap<>();res.put("stauts", resStatus);return res;}}
增量同步测试(自动触发)
canal增量同步是通过监听mysql的bin log进行实现了,那么当数据表里的内容有变化时canal client就会从canal server处获取到监听的内容
这里我做几个测试来对数据进行验证
- 新增记录
INSERT INTO
test.stu_info(id,name,age,update_time) VALUES (‘4’, ‘ddd’, ‘13’, ‘2019-08-31 11:28:11’);
结果:数据插入后,es立即同步过去了
- 删除记录
DELETE from stu_info where id=4
结果:数据执行了删除后es中id为4的数据也立即进行了删除
- 修改记录
update stu_info set age =23 where id=3
结果:es中id为3的数据也立即进行了变更
- 修改表结构
新增一列后
结果:es数据无变化 - 修改表结构
删除一列后
结果:es数据无变化
canal admin监控(本地启动)
canal为了管理和监控的方便也提供了ui界面模块,其模块为canal-admin
导入canal-admin配置库
找到canal-admin-server模块资源目录下的canal_manager.sql,将其导入到mysql中
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `canal_manager` /*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_bin */;USE `canal_manager`;SET NAMES utf8mb4;SET FOREIGN_KEY_CHECKS = 0;-- ------------------------------ Table structure for canal_adapter_config-- ----------------------------DROP TABLE IF EXISTS `canal_adapter_config`;CREATE TABLE `canal_adapter_config` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`category` varchar(45) NOT NULL,`name` varchar(45) NOT NULL,`status` varchar(45) DEFAULT NULL,`content` text NOT NULL,`modified_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;-- ------------------------------ Table structure for canal_cluster-- ----------------------------DROP TABLE IF EXISTS `canal_cluster`;CREATE TABLE `canal_cluster` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`name` varchar(63) NOT NULL,`zk_hosts` varchar(255) NOT NULL,`modified_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;-- ------------------------------ Table structure for canal_config-- ----------------------------DROP TABLE IF EXISTS `canal_config`;CREATE TABLE `canal_config` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`cluster_id` bigint(20) DEFAULT NULL,`server_id` bigint(20) DEFAULT NULL,`name` varchar(45) NOT NULL,`status` varchar(45) DEFAULT NULL,`content` text NOT NULL,`content_md5` varchar(128) NOT NULL,`modified_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`id`),UNIQUE KEY `sid_UNIQUE` (`server_id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;-- ------------------------------ Table structure for canal_instance_config-- ----------------------------DROP TABLE IF EXISTS `canal_instance_config`;CREATE TABLE `canal_instance_config` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`cluster_id` bigint(20) DEFAULT NULL,`server_id` bigint(20) DEFAULT NULL,`name` varchar(45) NOT NULL,`status` varchar(45) DEFAULT NULL,`content` text NOT NULL,`content_md5` varchar(128) DEFAULT NULL,`modified_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`id`),UNIQUE KEY `name_UNIQUE` (`name`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;-- ------------------------------ Table structure for canal_node_server-- ----------------------------DROP TABLE IF EXISTS `canal_node_server`;CREATE TABLE `canal_node_server` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`cluster_id` bigint(20) DEFAULT NULL,`name` varchar(63) NOT NULL,`ip` varchar(63) NOT NULL,`admin_port` int(11) DEFAULT NULL,`tcp_port` int(11) DEFAULT NULL,`metric_port` int(11) DEFAULT NULL,`status` varchar(45) DEFAULT NULL,`modified_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;-- ------------------------------ Table structure for canal_user-- ----------------------------DROP TABLE IF EXISTS `canal_user`;CREATE TABLE `canal_user` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`username` varchar(31) NOT NULL,`password` varchar(128) NOT NULL,`name` varchar(31) NOT NULL,`roles` varchar(31) NOT NULL,`introduction` varchar(255) DEFAULT NULL,`avatar` varchar(255) DEFAULT NULL,`creation_date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;SET FOREIGN_KEY_CHECKS = 1;-- ------------------------------ Records of canal_user-- ----------------------------BEGIN;INSERT INTO `canal_user` VALUES (1, 'admin', '6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9', 'Canal Manager', 'admin', NULL, NULL, '2019-07-14 00:05:28');COMMIT;SET FOREIGN_KEY_CHECKS = 1;
上面的脚本将会在mysql中建立一个名为canal_manager的数据库,并创建好canal库的基本数据表
canal-admin-server运行
修改canal-admin-server项目的application.yml,主要修改配置库的数据源,我这里的配置如下:
server:port: 8089spring:jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT+8spring.datasource:url: jdbc:mysql://192.168.1.61:3306/canal_manager?useUnicode=true&characterEncoding=UTF-8&useSSL=falseusername: rootpassword: 123456driver-class-name: com.mysql.jdbc.Driverhikari:maximum-pool-size: 10minimum-idle: 1canal:adminUser: adminadminPasswd: admin
然后启动canal-admin-server的项目即可,即运行CanalAdminApplication,如果运行成功,则会开启8089端口遍可以进行访问了,如我这里的:
http://localhost:8089
默认账号为:admin 密码为:123456
登录后再手动添加之前的server节点,遍可对此canal server进行一监控和管理了
通过canal client-adapter中esAdapter的实践了解了canal的特性,通过canal可以快速完成mysql到其他数据源的数据同步,并支持全量和增量同步的功能,同是canal也提供了canal-admin-server作为ui界面可供用户对canal进行管理和监控,本文中为了方便部署的是单节点的canal,对于canal的高可用其官方也有对应的支持.
cannal admin监控(docker) [有问题]
# 下载镜像docker pull canal/canal-admin:v1.1.4# wget https://github.com/alibaba/canal/blob/master/docker/run_admin.sh 官网文件,被墙# 类似canal server的安装,window上传后转换为linx中的文件,会出现没有最新版本的提示# 修改脚本中最后的cmd中启动镜像命令的canal/canal-admin指定为canal/canal-admin:v1.1.4sh run_admin.sh -e server.port=8089 \-e canal.adminUser=admin \-e canal.adminPasswd=admin# 查看容器docker ps# 访问地址:http://IP地址:8089/,账号admin,初始密码123456(登陆密码并不是admin,连接密码才是admin)

canal-admin的核心模型主要有:
- instance,对应canal-server里的instance,一个最小的订阅mysql的队列
- server,对应canal-server,一个server里可以包含多个instance
- 集群,对应一组canal-server,组合在一起面向高可用HA的运维
我们用docker安装启动canal-admin后,就会在本地创建一个数据库,ip是容器所在服务器本地ip,端口3306,这里我的是192.168.45.129:3306,账号密码都是canal

若有收获,就点个赞吧
0 人点赞
