1. 一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎Apache Lucene基础上的搜索引擎1)分布式实时文件存储,将每一个字段都编入索引,使其可以被搜索2)实时分析的分布式搜索引擎3)可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据2. Elasticsearch是面向文档型数据库,一条数据就是一个JSON格式的文档例:{"name" : "John","sex" : "Male","age" : 25,"birthDate": "1990/05/01","about" : "I love to go rock climbing","interests": [ "sports", "music" ]}
术语
1. 一个Elasticsearch集群可以包含多个索引(数据库),也就是说其中包含了很多类型(表),这些类型中包含了很多的文档(行),然后每个文档中又包含了很多的字段(列)例:Mysql中的一张User表中包含的一行行的数据,在Elasticsearch里就是一个文档,这个文档属于一个User的类型,各种各样的类型存在于一个索引当中2. 简易的Elasticsearch和关系型数据术语对照表:关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)Elasticsearch ⇒ 索引(Index) ⇒ 类型(type) ⇒ 文档(Docments) ⇒ 字段(Fields)
Elasticsearch接口
1.使用Java API 或者 HTTP的Restful API方式如:插入一条记录,可以发送一个HTTP请求,更新,查询也是类似这样的操作PUT /megacorp/employee/1{"name" : "John","sex" : "Male","age" : 25,"about" : "I love to go rock climbing","interests": [ "sports", "music" ]}
Elasticsearch索引
1.Elasticsearch索引: 一切设计都是为了提高搜索的性能2.为了提高搜索的性能,难免会牺牲某些其他方面,比如插入/更新。往Elasticsearch里插入一条记录,其实就是直接PUT一个json对象,这个对象有多个fields,如上面例子中的name, sex, age, about, interests那么在插入这些数据到Elasticsearch的同时,Elasticsearch还默默的为这些字段建立索引--倒排索引
B-Tree索引
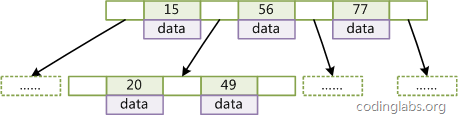
1. 二叉树查找效率是logN,同时插入新的节点不必移动全部节点,所以用树型结构存储索引,能同时兼顾插入和查询的性能。2. 因此在这个基础上,再结合磁盘的读取特性(顺序读/随机读),传统关系型数据库采用了B-Tree/B+Tree这样的数据结构,3. 为了提高查询效率,减少磁盘寻道次数,将多个值作为一个数组通过连续区间存放,一次寻道读取多个数据,同时也降低树的高度
倒排索引
Term Index -> Term Dictionary -> Posting List
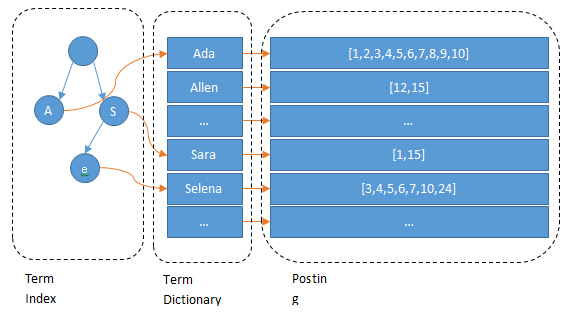
以上表为例(为了简单去掉about, interests两个field) //ID是Elasticsearch自建的文档idElasticsearch建立的索引:Name:| Term | Posting List || -- |:----:|| Kate | 1 || John | 2 || Bill | 3 |Age:| Term | Posting List || -- |:----:|| 24 | [1,2] || 29 | 3 |Sex:| Term | Posting List || -- |:----:|| Female | 1 || Male | [2,3] |
Posting List
1.Elasticsearch为每个field都建立了一个倒排索引,Kate,24, Female..这些叫term,而[1,2]就是Posting List2.Posting list就是一个int的数组,存储了所有符合某个term的文档id,通过posting list这种索引方式可以很快的查找age=24的同学
Term Dictionary
为了快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像字典查找一样
Term Index
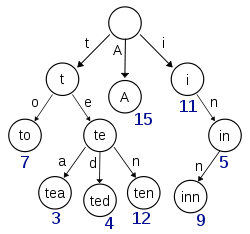
1. B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树(如下图)2. 这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找3. term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数
压缩技巧
1.FST例:mop, moth, pop, star, stop and top(term index里的term前缀)映射到序号:0,1,2,3,4,5(term dictionary的block位置)//最简单的做法就是定义个Map<string, integer="">//FST以字节的方式存储所有的term,这种压缩方式可以有效的缩减存储空间,使得term index足以放进内存2.Frame Of Reference增量编码压缩,将大数变小数,按字节存储
索引注意
1.ElaaticSearch索引思路将磁盘里的东西尽量搬进内存减少磁盘随机读取次数(同时也利用磁盘顺序读特性)结合各种压缩算法,用及其苛刻的态度使用内存2.索引注意1)不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的2)同样的,对于String类型的字段,不需要analysis的也需要明确定义出来,因为默认也是会analysis的3)选择有规律的ID很重要,随机性太大的ID(比如java的UUID)不利于查询3.ID上面看到的压缩算法,都是对Posting list里的大量ID进行压缩的:1)那如果ID是顺序的,或者是有公共前缀等具有一定规律性的ID,压缩比会比较高2)可能是最影响查询性能的,应该是最后通过Posting list里的ID到磁盘中查找Document信息的那步,因为Elasticsearch是分Segment存储的,根据ID这个大范围的Term定位到Segment的效率直接影响了最后查询的性能,如果ID是有规律的,可以快速跳过不包含该ID的Segment,从而减少不必要的磁盘读次数,所以通过选择一个高效的全局ID方案可以提高查询效率

若有收获,就点个赞吧
0 人点赞
