为什么需要模块化编程
网页越来越像桌面程序,需要一个团队分工协作、进度管理、单元测试等等……开发者不得不使用软件工程的方法,管理网页的业务逻辑。理想情况下,开发者只需要实现核心的业务逻辑,其他都可以加载别人已经写好的模块。
ES5 下模块化
立即执行函数写法
使用”立即执行函数”(Immediately-Invoked Function Expression,IIFE),可以达到不暴露私有成员的目的。
var module1 = (function(){var _count = 0;var m1 = function(){//...};var m2 = function(){//...};return {m1 : m1,m2 : m2};})();
使用上面的写法,外部代码无法读取内部的 _count 变量。
console.info(module1._count); // undefined
module1 就是 Javascript 模块的基本写法。
放大模式
如果一个模块很大,必须分成几个部分,或者一个模块需要继承另一个模块,这时就有必要采用”放大模式”(augmentation)。
var module1 = (function (mod){mod.m3 = function () {//...};return mod;})(module1);
上面的代码为 module1 模块添加了一个新方法 m3(),然后返回新的 module1 模块。
宽放大模式
在浏览器环境中,模块的各个部分通常都是从网上获取的,有时无法知道哪个部分会先加载。如果采用上一节的写法,第一个执行的部分有可能加载一个不存在空对象,这时就要采用”宽放大模式”。
var module1 = ( function (mod){//...return mod;})(window.module1 || {});
与”放大模式”相比,"宽放大模式"就是”立即执行函数”的参数可以是空对象。
输入全局变量
独立性是模块的重要特点,模块内部最好不与程序的其他部分直接交互。为了在模块内部调用全局变量,必须显式地将其他变量输入模块。
var module1 = (function ($, YAHOO) {//...})(jQuery, YAHOO);
上面的 module1 模块需要使用 jQuery 库和 YUI 库,就把这两个库(其实是两个模块)当作参数输入 module1。这样做除了保证模块的独立性,还使得模块之间的依赖关系变得明显。这方面更多的讨论,参见 Ben Cherry 的著名文章 JavaScript Module Pattern: In-Depth。
模块的规范
先想一想,为什么模块很重要?因为有了模块,我们就可以更方便地使用别人的代码,想要什么功能,就加载什么模块。但是,这样做有一个前提,那就是大家必须以同样的方式编写模块,否则你有你的写法,我有我的写法,岂不是乱了套!
Javascript 模块规范共有四种:CommonJS、AMD、CMD、ES Modules。我主要介绍 AMD,但是要先从 CommonJS 讲起。
CommonJS
2009年,美国程序员 Ryan Dahl 创造了 node.js 项目,将 javascript 语言用于服务器端编程。

这标志”Javascript模块化编程”正式诞生。因为老实说,在浏览器环境下,没有模块也不是特别大的问题,毕竟网页程序的复杂性有限;但是在服务器端,一定要有模块,与操作系统和其他应用程序互动,否则根本没法编程。
node.js 的模块系统,就是参照 CommonJS 规范实现的。在 CommonJS 中,有一个全局性方法 require(),用于加载模块。假定有一个数学模块 math.js,就可以像下面这样加载。
var math = require('math');
然后,就可以调用模块提供的方法:
var math = require('math');math.add(2,3); // 5
因为这个系列主要针对浏览器编程,不涉及 node.js,所以对 CommonJS 就不多做介绍了。我们在这里只要知道,require() 用于加载模块就行了。
浏览器环境
有了服务器端模块以后,很自然地,大家就想要客户端模块。而且最好两者能够兼容,一个模块不用修改,在服务器和浏览器都可以运行。
但是,由于一个重大的局限,使得 CommonJS 规范不适用于浏览器环境。还是上一节的代码,如果在浏览器中运行,会有一个很大的问题,你能看出来吗?
var math = require('math');math.add(2, 3);
第二行 math.add(2, 3),在第一行 require(‘math’)之后运行,因此必须等 math.js 加载完成。也就是说,如果加载时间很长,整个应用就会停在那里等。
这对服务器端不是一个问题,因为所有的模块都存放在本地硬盘,可以同步加载完成,等待时间就是硬盘的读取时间。但是,对于浏览器,这却是一个大问题,因为模块都放在服务器端,等待时间取决于网速的快慢,可能要等很长时间,浏览器处于”假死”状态。
因此,浏览器端的模块,不能采用”同步加载”(synchronous),只能采用”异步加载”(asynchronous)。这就是AMD 规范诞生的背景。
AMD
AMD 是”Asynchronous Module Definition”的缩写,意思就是”异步模块定义”。它采用异步方式加载模块,模块的加载不影响它后面语句的运行。所有依赖这个模块的语句,都定义在一个回调函数中,等到加载完成之后,这个回调函数才会运行。
AMD 也采用 require() 语句加载模块,但是不同于 CommonJS,它要求两个参数:
require([module], callback);
第一个参数[module],是一个数组,里面的成员就是要加载的模块;第二个参数callback,则是加载成功之后的回调函数。如果将前面的代码改写成AMD形式,就是下面这样:
require(['math'], function (math) {math.add(2, 3);});
math.add() 与 math 模块加载不是同步的,浏览器不会发生假死。所以很显然,AMD 比较适合浏览器环境。
目前,主要有两个 Javascript 库实现了 AMD 规范:require.js 和 curl.js。
ES Modules
当你在使用模块进行开发时,其实是在构建一张依赖关系图。不同模块之间的连线就代表了代码中的导入语句。
正是这些导入语句告诉浏览器或者 Node 该去加载哪些代码。
我们要做的是为依赖关系图指定一个入口文件。从这个入口文件开始,浏览器或者 Node 就会顺着导入语句找出所依赖的其他代码文件。
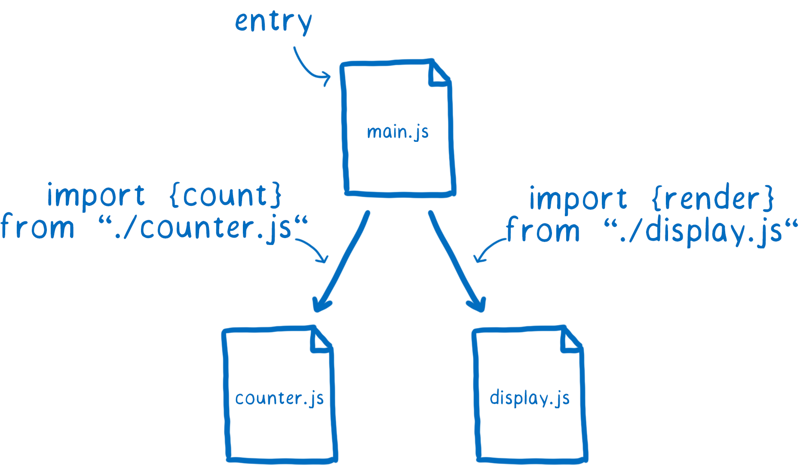
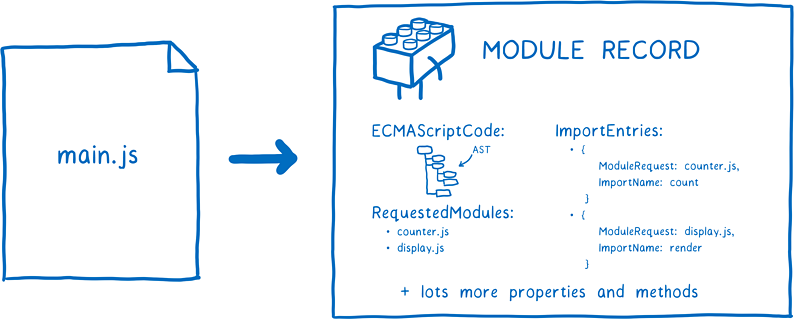
但是呢,浏览器并不能直接使用这些代码文件。它需要解析所有的文件,并把它们变成一种称为模块记录(Module Record)的数据结构。只有这样,它才知道代码文件中到底发生了什么。
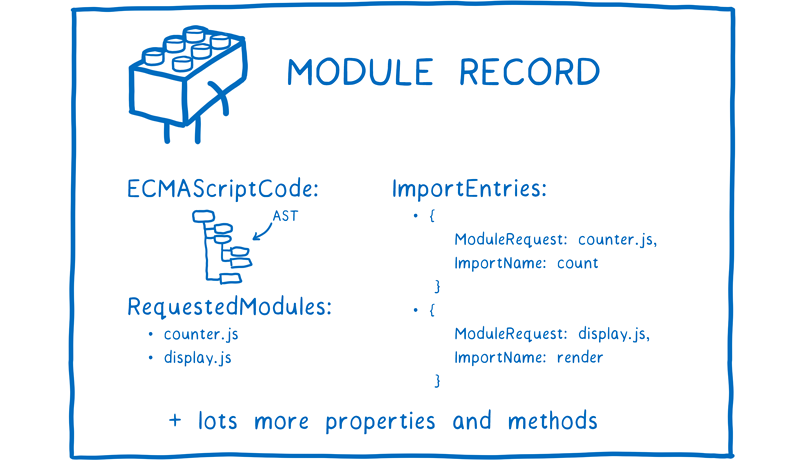
解析之后,还需要把模块记录变成一个模块实例。模块实例会把代码和状态结合起来。所谓代码,基本上是一组指令集合。它就像是制作某样东西的配方,指导你该如何制作。但是它本身并不能让你完成制作。你还需要一些原料,这样才可以按照这些指令完成制作。所谓状态,它就是原料。具体点,状态是变量在任何时候的真实值。当然,变量实际上就是内存地址的别名,内存才是正在存储值的地方。所以,可以看出,模块实例中代码和状态的结合,就是指令集和变量值的结合。
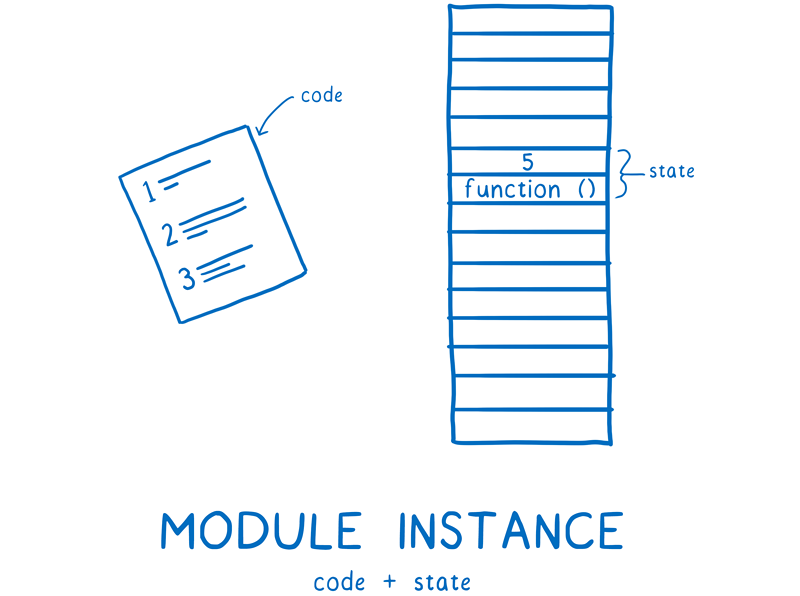
对于模块而言,我们真正需要的是模块实例。模块加载会从入口文件开始,最终生成完整的模块实例关系图。对于 ESM ,这个过程包含三个阶段:
- 构建:查找,下载,然后把所有文件解析成模块记录。
- 实例化:为所有模块分配内存空间(此刻还没有填充值),然后依照导出、导入语句把模块指向对应的内存地址。这个过程称为链接(Linking)。
- 运行:运行代码,从而把内存空间填充为真实值。
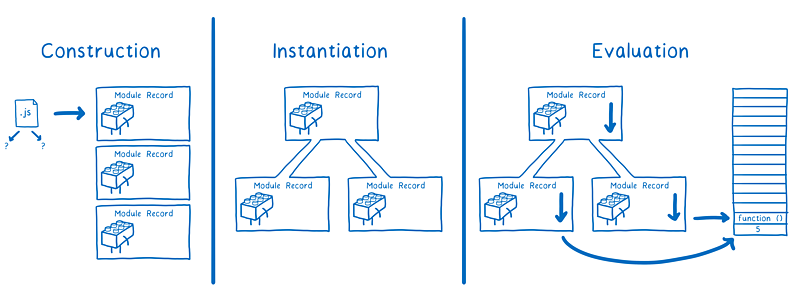
大家都说 ESM 是异步的。因为它把整个过程分为了三个不同的阶段:加载、实例化和运行,并且这三个阶段是可以独立进行的。这意味着,ESM 规范确实引入了一种异步方式,且这种异步方式在 CJS 中是没有的。后面我们会详细说到为什么,然而在 CJS 中,一个模块及其依赖的加载、实例化和运行是一起顺序执行的,中间没有任何间断。
不过,这三个阶段本身是没必要异步化。它们可以同步执行,这取决于它是由谁来加载的。因为 ESM 标准并没有明确规范所有相关内容。实际上,这些工作分为两部分,并且分别是由不同的标准所规范的。
其中,ESM 标准 规范了如何把文件解析为模块记录,如何实例化和如何运行模块。但是它没有规范如何获取文件。
文件是由加载器来提取的,而加载器由另一个不同的标准所规范。对于浏览器来说,这个标准就是 HTML。但是你还可以根据所使用的平台使用不同的加载器。
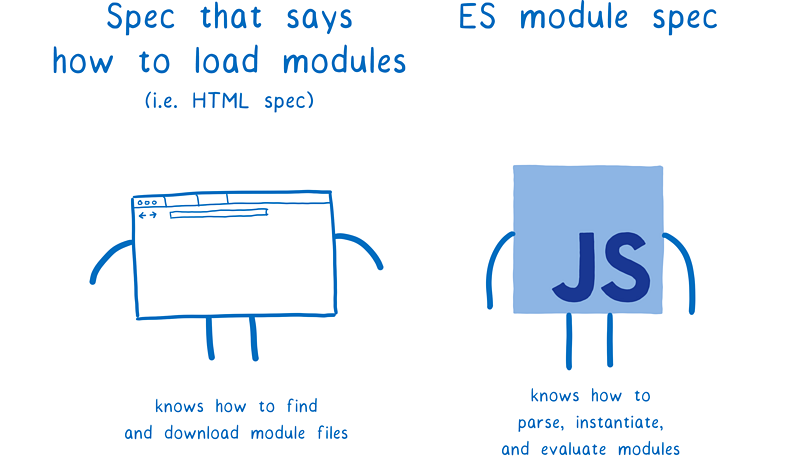
加载器也同时控制着如何加载模块。它会调用 ESM 的方法,包括 ParseModule、Module.Instantiate 和 Module.Evaluate 。它就像是控制着 JS 引擎的木偶。
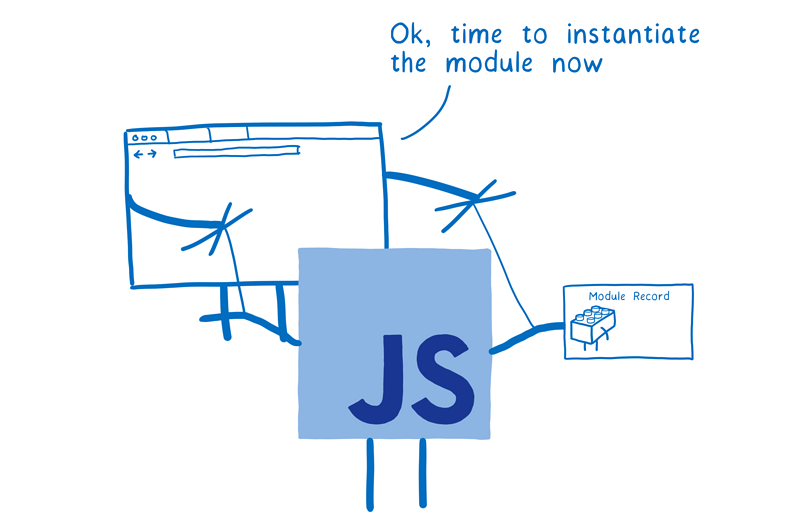
下面我们将更加详细地说明每一步。
构建
对于每个模块,在构建阶段会做三个处理:
- 确定要从哪里下载包含该模块的文件,也称为模块定位(Module Resolution)
- 提取文件,通过从 URL 下载或者从文件系统加载
- 解析文件为模块记录
下载模块
加载器负责定位文件并且提取。首先,它需要找到入口文件。在 HTML 中,你可以通过 <script> 标签来告诉加载器。
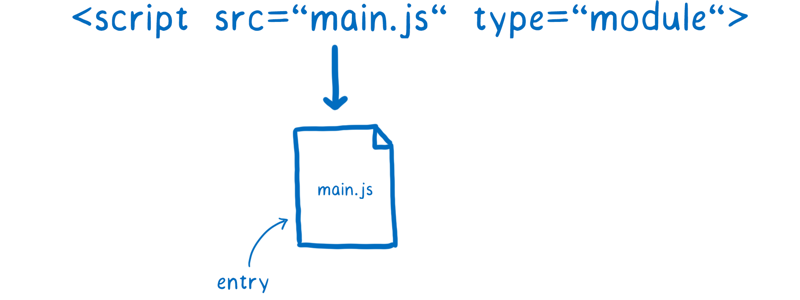
但是,加载器要如何定位 main.js 直接依赖的模块呢?
这个时候导入语句就派上用场了。导入语句中有一部分称为模块定位符(Module Specifier),它会告诉加载器去哪定位模块。

对于模块定位符,有一点要注意的是:它们在浏览器和 Node 中会有不同的处理。每个平台都有自己的一套方式来解析模块定位符。这些方式称为模块定位算法,不同的平台会使用不同的模块定位算法。
当前,一些在 Node 中能工作模块定位符并不能在浏览器中工作,但是已经有一项工作正在解决这个问题。
在这个问题被解决之前,浏览器只接受 URL 作为模块定位符。
它们会从 URL 加载模块文件。但是,这并不是在整个关系图上同时发生的。因为在解析完这个模块之前,你根本不知道它依赖哪些模块。而且在它下载完成之前,你也无法解析它。
这就意味着,我们必须一层层遍历依赖树,先解析文件,然后找出依赖,最后又定位并加载这些依赖,如此往复。
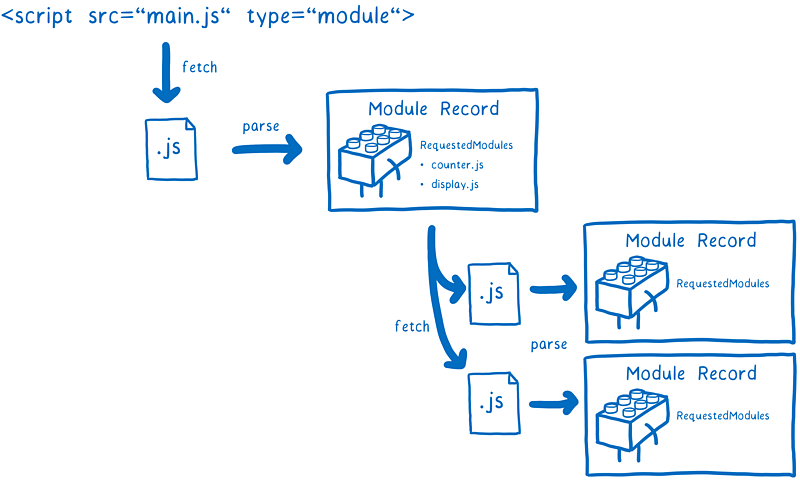
如果主线程正在等待这些模块文件下载完成,许多其他任务将会堆积在任务队列中,造成阻塞。这是因为在浏览器中,下载会耗费大量的时间。
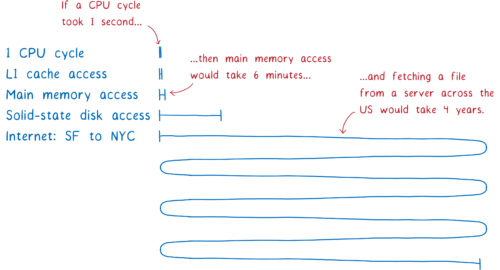
而阻塞主线程会使得应用变得卡顿,影响用户体验。这是 ESM 标准把算法分成多个阶段的原因之一。将构建划分为一个独立阶段后,浏览器可以在进入同步的实例化过程之前下载文件然后理解模块关系图。
ESM 和 CJS 之间最主要的区别之一就是,ESM 把算法化为为多个阶段。
CJS 使用不同的算法是因为它从文件系统加载文件,这耗费的时间远远小于从网络上下载。因此 Node 在加载文件的时候可以阻塞主线程,而不造成太大影响。而且既然文件已经加载完成了,那么它就可以直接进行实例化和运行。所以在 CJS 中实例化和运行并不是两个相互独立的阶段。
这也意味着,你可以在返回模块实例之前,顺着整颗依赖树去逐一加载、实例化和运行每一个依赖。
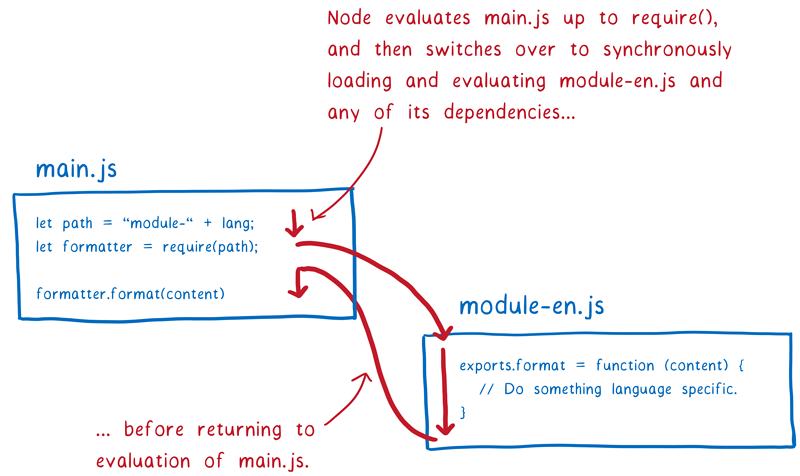
CJS 的方式对 ESM 也有一些启发,这个后面会解释。
其中一个就是,在 Node 的 CJS 中,你可以在模块定位符中使用变量。因为已经执行了 require 之前的代码,所以模块定位符中的变量此刻是有值的,这样就可以进行模块定位的处理了。
但是对于 ESM,在运行任何代码之前,你首先需要建立整个模块依赖的关系图。也就是说,建立关系图时变量是还没有值的,因为代码都还没运行。

不过呢,有时候我们确实需要在模块定位符中使用变量。比如,你可能需要根据当前的状况加载不同的依赖。
为了在 ESM 中实现这种方式,人们已经提出了一个动态导入提案。该提案允许你可以使用类似 import(\${path}/foo.js)的导入语句。
这种方式实际上是把使用 import() 加载的文件当成了一个入口文件。动态导入的模块会开启一个全新的独立依赖关系树。
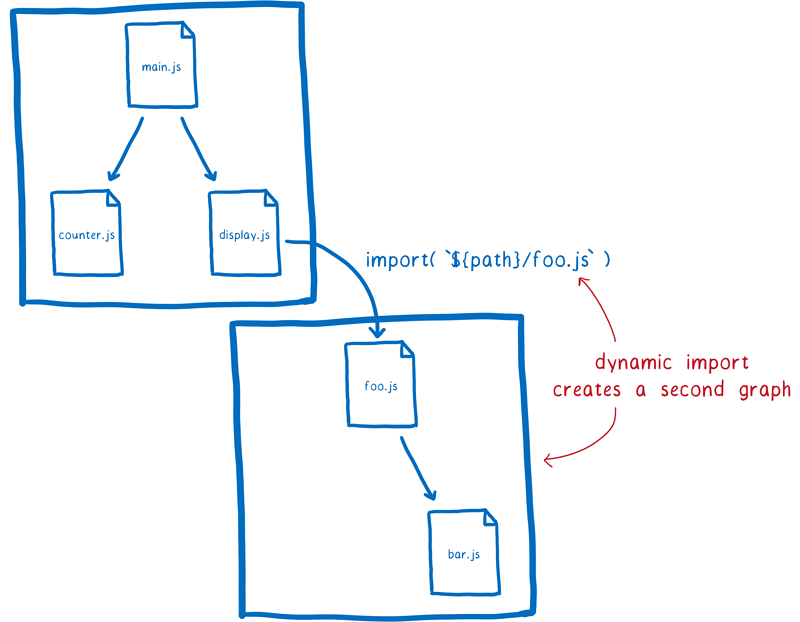
不过有一点要注意的是,这两棵依赖关系树共有的模块会共享同一个模块实例。这是因为加载器会缓存模块实例。在特定的全局作用域中,每个模块只会有一个与之对应的模块实例。
这种方式有助于提高 JS 引擎的性能。例如,一个模块文件只会被下载一次,即使有多个模块依赖它。这也是缓存模块的原因之一,后面说到运行的时候会介绍另一个原因。
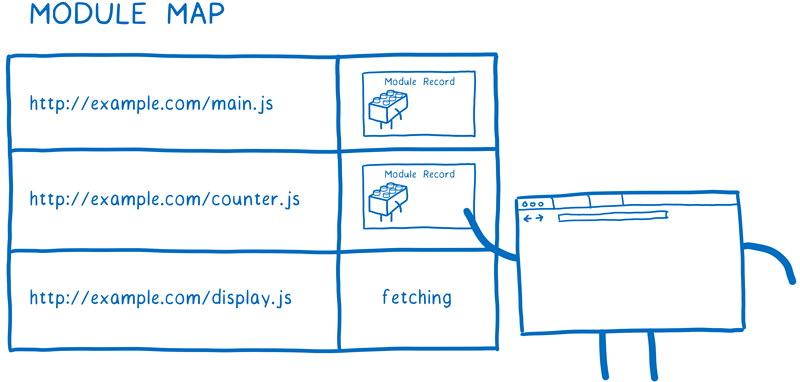
加载器使用模块映射(Module Map)来管理缓存。每个全局作用域都在一个单独的模块映射中跟踪其模块。
当加载器要从一个 URL 加载文件时,它会把 URL 记录到模块映射中,并把它标记为正在下载的文件。然后它会发出这个文件请求并继续开始获取下一个文件。
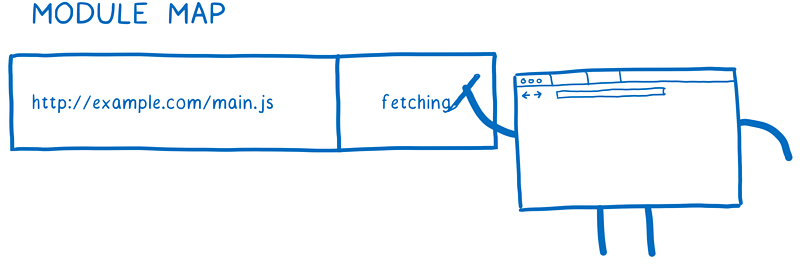
当其他模块也依赖这个文件的时候会发生什么呢?加载器会查找模块映射中的每一个 URL 。如果发现 URL 的状态为正在下载,则会跳过该 URL ,然后开始下一个依赖的处理。
不过,模块映射的作用并不仅仅是记录哪些文件已经下载。下面我们将会看到,模块映射也可以作为模块的缓存。
解析模块
至此,我们已经拿到了模块文件,我们需要把它解析为模块记录。
这有助于浏览器理解模块的不同部分。
一旦模块记录创建完成,它就会被记录在模块映射中。所以,后续任何时候再次请求这个模块时,加载器就可以直接从模块映射中获取该模块。
解析过程中有一个看似微不足道的细节,但是实际造成的影响却很大。那就是所有的模块都按照严格模式来解析的。
也还有其他的小细节,比如,关键字 await 在模块的最顶层是保留字, this 的值为 undefinded。
这种不同的解析方式称为解析目标(Parse Goal)。如果按照不同的解析目标来解析相同的文件,会得到不同的结果。因此,在解析文件之前,必须清楚地知道所解析的文件类型是什么,不管它是不是一个模块文件。
在浏览器中,知道文件类型是很简单的。只需要在 <script> 脚本中添加 type="module" 属性即可。这告诉浏览器这个文件需要被解析为一个模块。而且,因为只有模块才能被导入,所以浏览器以此推测所有的导入也都是模块文件。
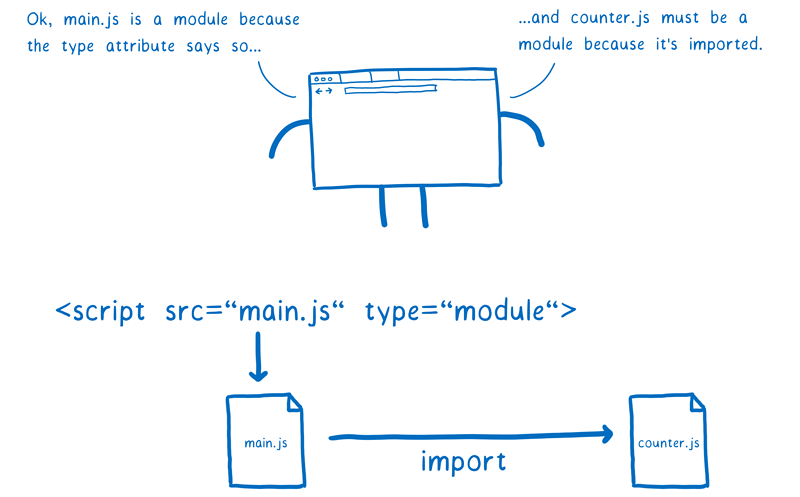
不过在 Node 中,我们并不使用 HTML 标签,所以也没办法通过 type 属性来辨别。社区提出一种解决办法是使用 .mjs拓展名。使用该拓展名会告诉 Node 说“这是个模块文件”。你会看到大家正在讨论把这个作为解析目标。不过讨论仍在继续,所以目前仍不明确 Node 社区最终会采用哪种方式。
无论最终使用哪种方式,加载器都会决定是否把一个文件作为模块来解析。如果是模块,而且包含导入语句,那它会重新开始处理直至所有的文件都已提取和解析。
到这里,构建阶段差不多就完成了。在加载过程处理完成后,你已经从最开始只有一个入口文件,到现在得到了一堆模块记录。
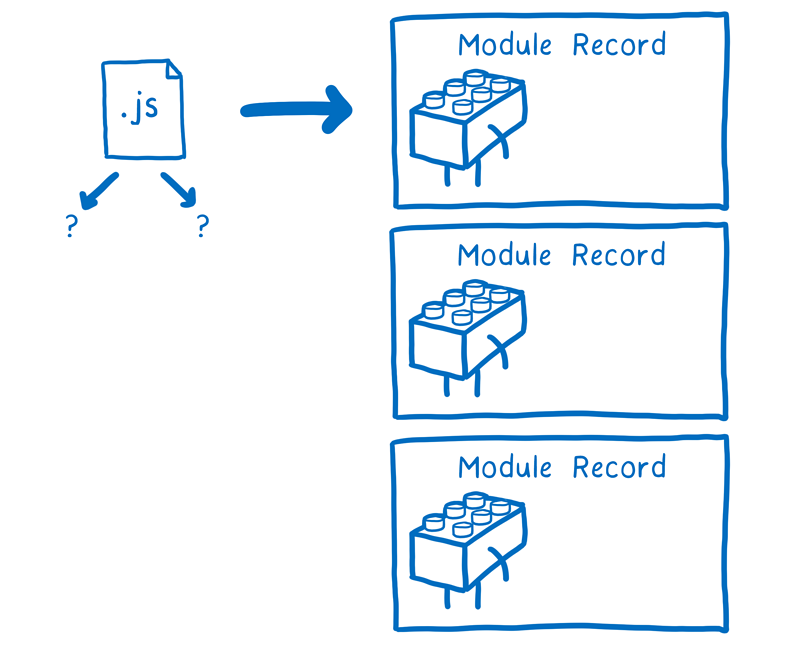
下一步会实例化这些模块并且把所有的实例链接起来。
实例化
正如前文所述,一个模块实例结合了代码和状态。状态存储在内存中,所以实例化的过程就是把所有值写入内存的过程。
首先,JS 引擎会创建一个模块环境记录(Module Environment Record)。它管理着模块记录的所有变量。然后,引擎会找出导出在内存中的地址。模块环境记录会跟踪每个导出对应于哪个内存地址。
这些内存地址此时还没有值,只有等到运行后它们才会被填充上实际值。有一点要注意,所有导出的函数声明都在这个阶段初始化,这会使得后面的运行阶段变得更加简单。
为了实例化模块关系图,引擎会采用深度优先的后序遍历方式。即,它会顺着关系图到达最底端没有任何依赖的模块,然后设置它们的导出。
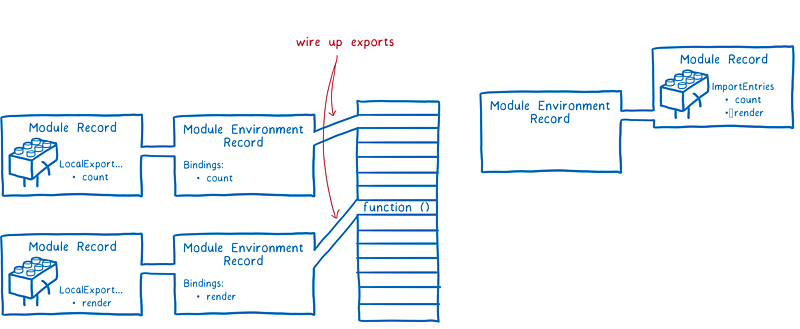
最终,引擎会把模块下的所有依赖导出链接到当前模块。然后回到上一层把模块的导入链接起来。
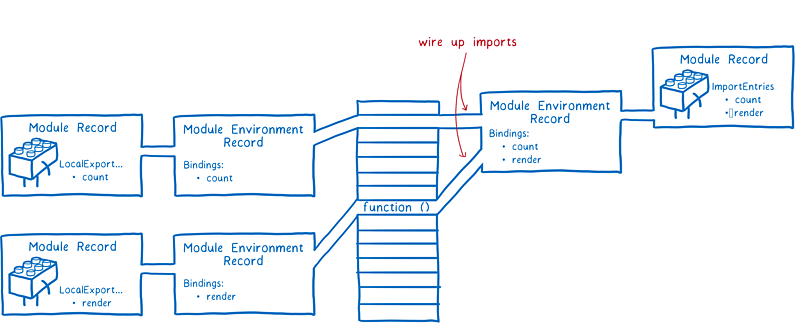
这个过程跟 CJS 是不同的。在 CJS 中,整个导出对象在导出时都是值拷贝。即,所有的导出值都是拷贝值,而不是引用。所以,如果导出模块内导出的值改变了,导入模块中导入的值也不会改变。
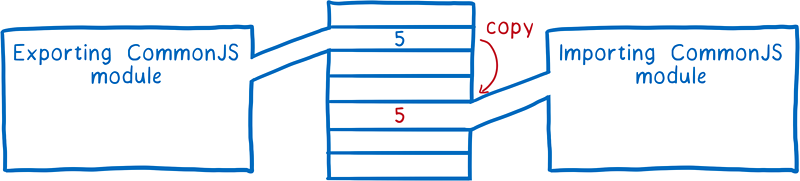
相反,ESM 则使用称为实时绑定(Live Binding)的方式。导出和导入的模块都指向相同的内存地址(即值引用)。所以,当导出模块内导出的值改变后,导入模块中的值也实时改变了。
模块导出的值在任何时候都可以能发生改变,但是导入模块却不能改变它所导入的值,因为它是只读的。
举例来说,如果一个模块导入了一个对象,那么它只能改变该对象的属性,而不能改变对象本身。
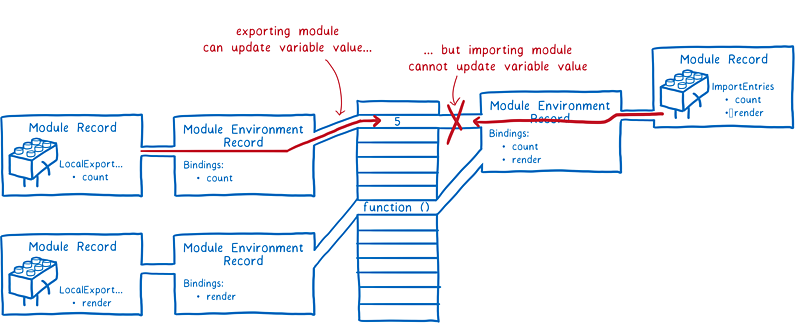
ESM 采用这种实时绑定的原因是,引擎可以在不运行任何模块代码的情况下完成链接。后面会解释到,这对解决运行阶段的循环依赖问题也是有帮助的。
实例化阶段完成后,我们得到了所有模块实例,以及已完成链接的导入、导出值。现在我们可以开始运行代码并且往内存空间内填充值了。
运行
最后一步是往已申请好的内存空间中填入真实值。JS 引擎通过运行顶层代码(函数外的代码)来完成填充。
除了填充值以外,运行代码也会引发一些副作用(Side Effect)。例如,一个模块可能会向服务器发起请求。

因为这些潜在副作用的存在,所以模块代码只能运行一次。
前面我们看到,实例化阶段中发生的链接可以多次进行,并且每次的结果都一样。但是,如果运行阶段进行多次的话,则可能会每次都得到不一样的结果。
这正是为什么会使用模块映射的原因之一。模块映射会以 URL 为索引来缓存模块,以确保每个模块只有一个模块记录。这保证了每个模块只会运行一次。跟实例化一样,运行阶段也采用深度优先的后序遍历方式。
那对于前面谈到的循环依赖会怎么处理呢?
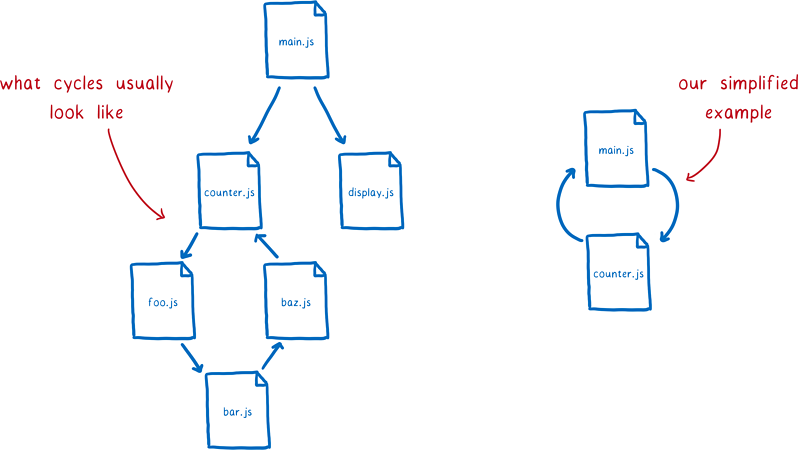
循环依赖会使得依赖关系图中出现一个依赖环,即你依赖我,我也依赖你。通常来说,这个环会非常大。不过,为了解释好这个问题,这里我们举例一个简单的循环依赖。
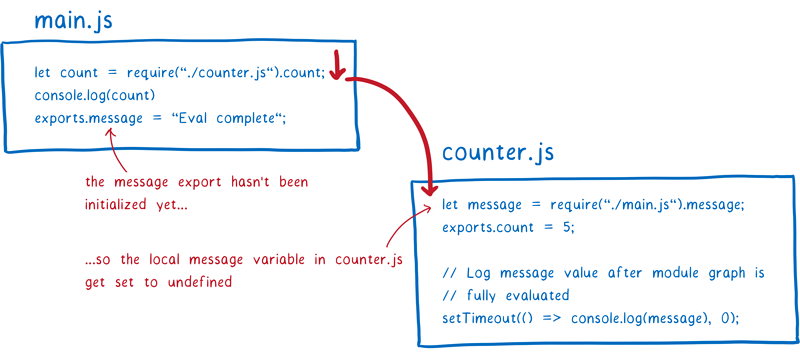
首先来看下这种情况在 CJS 中会发生什么。
最开始时,main 模块会运行 require 语句。紧接着,会去加载 counter 模块。
counter 模块会试图去访问导出对象的 message 。不过,由于 main 模块中还没运行到 message 处,所以此时得到的 message 为 undefined。JS 引擎会为本地变量分配空间并把值设为 undefined 。

运行阶段继续往下执行,直到 counter 模块顶层代码的末尾处。我们想知道,当 counter 模块运行结束后,message 是否会得到真实值,所以我们设置了一个超时定时器。之后运行阶段便返回到 main.js 中。
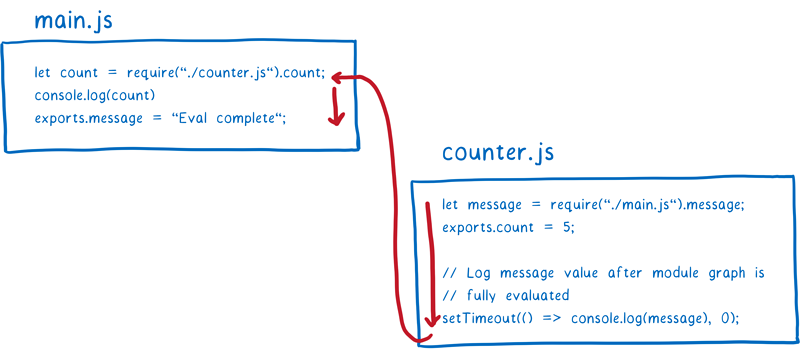
这时,message 将会被初始化并添加到内存中。但是这个 message 与 counter 模块中的 message 之间并没有任何关联关系,所以 counter 模块中的 message 仍然为 undefined。
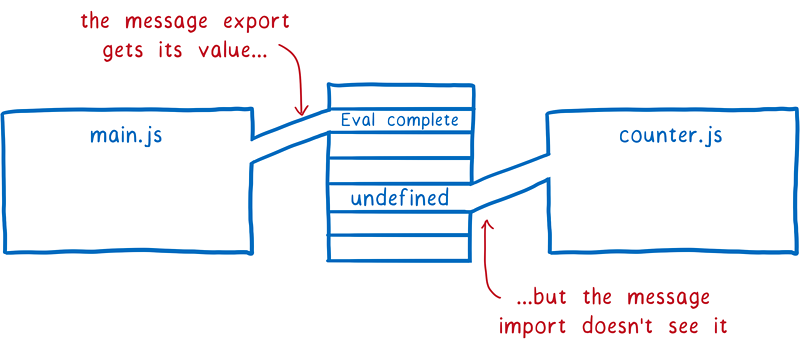
如果导出值采用的是实时绑定方式,那么 counter 模块最终会得到真实的 message 值。当超时定时器开始计时时,main.js 的运行就已经完成并设置了 message 值。
支持循环依赖是 ESM 设计之初就考虑到的一大原因。也正是这种分段设计使其成为可能。
ESM 的当前状态
等到 2018 年 5 月 Firefox 60 发布后,所有的主流浏览器就都默认支持 ESM 了。Node 也正在添加 ESM 支持,为此还成立了工作小组来专门研究 CJS 和 ESM 之间的兼容性问题。
所以,在未来你可以直接在 <script> 标签中使用 type="module",并且在代码中使用 import 和 export 。
同时,更多的模块功能也正在研究中。
比如动态导入提案已经处于 Stage 3 状态;import.meta也被提出以便 Node.js 对 ESM 的支持;模块定位提案 也致力于解决浏览器和 Node.js 之间的差异。
相信在不久的未来,跟模块一起玩耍将会变成一件更加愉快的事!
参考
【1】Javascript模块化编程(一):模块的写法 | 阮一峰网络日志
【2】Javascript模块化编程(二):AMD规范 | 阮一峰网络日志
【3】图说 ES Modules

若有收获,就点个赞吧
0 人点赞
