OpenLookeng 我理解其实就是基于异构数据源上的统一查询引擎。这一层其实可以理解为替换掉Hive。实际底层物理存储可以是多种多样的,可以是RDB,HDFS(Hive),GuassDB(OLAP DB),Hbase等等。这样也就同一个了查询接口,基于标准SQL 2003语法,屏蔽了不同数据源查询的学习成本。
- 什么是OpenLookeng
数据虚拟化引擎 openLooKeng:我们不搬运数据,我们是数据的”连接器“
- OpenLookeng的架构
底层其实是基于Presto的查询架构,所以也是M-S架构
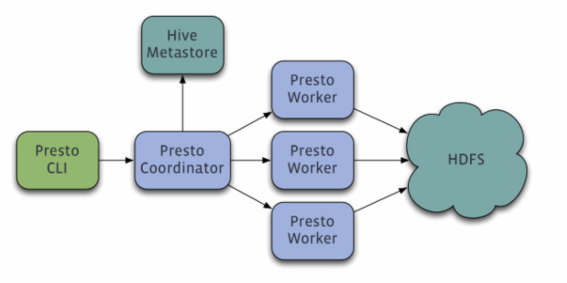
- Master-Slave的架构,由下面三部分组成:
- 一个Coordinator节点
- 一个Discovery Server节点
- 多个Worker节点
- 现状及问题
无论是关系型数据库中的 PostgreSQL 或者 MySQL,抑或是 Hadoop 体系下的 Hive 或者 HBase,这些目前业界通用的数据管理系统都有自成体系的一套 SQL 方言。数据分析师想要分析某一种数据管理系统的数据,就得熟练掌握某一种 SQL 方言;为了对不同数据源进行联合查询,那么就得在应用程序逻辑中使用不同的客户端去连接不同的数据源,整个分析过程架构复杂、编程入口多、系统集成困难,这对于涉及海量数据的数据分析师而言这样的分析过程十分痛苦。
为了解决多数据源形成的数据孤岛的联合查询问题,业界正在广泛使用数据仓库这一解决方案。
数据仓库在过去的数年里快速发展,它通过抽取(Extract)、转换(Transform)、加载(Load)各种各样数据源中的数据,经过 ETL 这一整套流程,将加工后的数据集中保存在专题数据仓库中,供数据分析师或用户使用。
但随着数据规模的进一步增长,业界已经逐渐认识到将数据搬运到数据仓库的过程是昂贵的,除了数据仓库的硬件或软件的成本,维护与更新整个 ETL 逻辑系统的人力成本也逐渐成为数据仓库的重要开销之一。
数据仓库 ETL 流程同时也是笨重且耗时的,为了获取到想要的数据,数据分析师或用户不得不妥协于数据仓库 T+1 的数据分析模式,想要快速进行业务分析探索对于数据分析师来说一直是一个待解的难题。
人们为了解决各种各样的数据管理系统的数据孤岛问题,针对不同的业务应用又发明了专题数据仓库,但随着业务应用的增多,日益增多的专题数据仓库又变成了数据孤岛。
是否有一种系统架构简洁、编程入口统一、系统集成度好的解决方案呢?
- 使用场景
高性能的交互式查询场景:openLooKeng 基于内存的计算框架,充分利用内存并行处理、索引、Cache、分布式的流水线作业等技术手段来快速的进行查询分析,可以处理 TB 甚至 PB 级的海量数据。以往使用 Hive、Spark 甚至 Impala 来构建查询任务的交互式分析应用系统都可以使用 openLooKeng 查询引擎来进行换代升级,从而获取更快的查询性能。
跨源异构的查询场景:正如前文所述,RDBMS、NoSQL 等数据管理系统在客户的各种应用系统中广泛使用;为了处理这些数据而建立起来的 Hive 或者 MPPDB 等专题数据仓库也越来越多。而这些数据库或者数据仓库往往彼此孤立形成独立的数据孤岛,数据分析师常常苦于:查询各种数据源需要使用不同的连接方式或者客户端,以及运行不同的 SQL 方言,这些不同导致额外的学习成本以及复杂的应用开发逻辑。
如果不将各种数据源的数据再次汇聚到一起,则无法对不同系统的数据进行联邦查询
查询各种数据源需要使用不同的连接方式或者客户端,以及运行不同的 SQL 方言,这些不同导致额外的学习成本以及复杂的应用开发逻辑。
如果不将各种数据源的数据再次汇聚到一起,则无法对不同系统的数据进行联邦查询。
使用 openLooKeng 可实现 RDBMS、NoSQL 等数据库以及 Hive 或 MPPDB 等数据仓库的联合查询,借助 openLooKeng 的跨源异构查询能力,数据分析师可实现海量数据的分钟级甚至秒级查询分析。
跨域跨 DC 的查询场景:对于省-市、总部-分部这样两级或者多级数据中心的场景,用户常常需要从省级(总部)数据中心查询市级(分部)数据中心的数据,这种跨域查询的主要瓶颈在于多个数据中心之间的网络问题(带宽不足、时延大、丢包等),从而导致查询时延长、性能不稳定等。
openLooKeng 专为这种跨域查询设计了跨域跨 DC 的解决方案 DataCenter Connector,通过 openLooKeng 集群之间传输计算结果的方式,避免了大量原始数据的网络传输,规避了带宽不足、丢包等带来的网络问题,一定程度上解决了跨域跨 DC 查询的难题,在跨域跨 DC 的查询场景有较高的实用价值。
计算存储分离的场景:openLooKeng 自身是不带存储引擎的,其数据源主要来自各种异构的数据管理系统,因而是一个典型的存储计算分离的系统,可以方便的进行计算、存储资源的独立水平扩展。
openLooKeng 存储计算分离的技术架构可实现集群节点的动态扩展,实现不断业务的资源弹性伸缩,适合于需要计算存储分离的业务场景。
快速进行数据探索的场景:如前文所述,客户为了查询多种数据源中的数据,通常的做法是通过 ETL 过程建立专门的数据仓库,但这样带来昂贵的人力成本、ETL 时间成本等问题。
对于需要快速进行数据探索而不想构建专门的数据仓库的客户,将数据复制并加载到数据仓库的做法显得既费时又费力,而且还可能得不到用户想要的分析结果。
openLooKeng 可通过标准语法定义出一个虚拟的数据集市,结合跨源异构的查询能力连接到各个数据源,从而在这个虚拟的数据集市语义层定义出用户需要探索的各种分析任务。
使用 openLooKeng 的这种数据虚拟化能力,客户可快速的建立起基于各种数据源的探索分析服务,而无需构建复杂的、专门的数据仓库,从而节约人力与时间成本,对于想快速进行数据探索从而开发新业务的场景使用 openLooKeng 是最佳的选择之一。
- 优点和不足
软件行业有一句名言:从来没有银弹。任何一门技术不能解决所有的问题,都是有其诞生的背景及适用情况。
优点:
- 融合场景查询
- 跨数据中心/云
- 数据源扩展
- 性能
- 可靠性
让数据治理、使用更简单
不足:
- 秒级的性能,对于实时性很高的系统,不满足

若有收获,就点个赞吧
0 人点赞
