前言:
《Presto 分布式SQL查询引擎及原理分析》详细介绍了Presto 的数据模型、技术架构,解释了Presto 对于查询分析有着较高性能。任何SQL引擎,执行过程都是比较复杂的。本篇文章来详细分析 Presto SQL的执行过程以及Presto Connector对索引条件下推良好扩展性技术原理。
Presto执行计划分析
Presto 生成查询执行计划流程
SQL 编译为最终的物理执行计划大概分为:词法分析、语义分析、执行计划生成、优化执行计划、执行计划分段等几个步骤。
逻辑计划生成(简单查询)
一个简单查询,最终构造为一个QueryPlan。对于较复杂的查询,是多个QueryPlan的组合。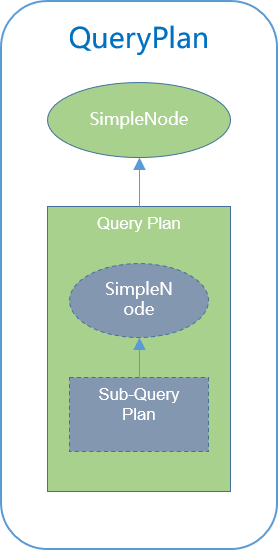
Table:table是 view则处理view生成的关联查询计划;如果是 table,则构建一个 TableScanNode,获得数据源数据;
SampleRelation:简单查询,构建SampleNode添加到执行计划树之上;
Values:获取 Query 语句每一项值,构造 ValuesNode;
TableSubQuery:处理可能存在的子查询,并生成子查询的执行计划;
逻辑计划生成(JOIN)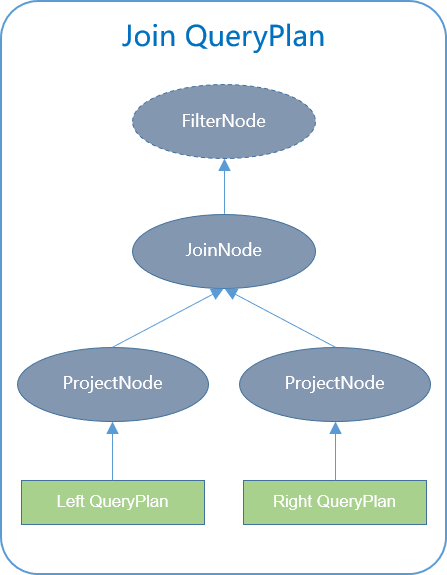
Left QueryPlan:处理 JOIN 左侧的 QueryPlan,生成执行计划树;
Right QueryPlan:处理 JOIN 右侧的 QueryPlan,生成执行计划树;
ProjectNode:把左右两表连接条件提取出来,给 JOIN 两侧的执行计划;树上分别添加 ProjectNode;
JoinNode:生成对应类型的 JoinNode,并添加一个FilterNode,用于过滤连接后的结果集;
逻辑计划生成(Union)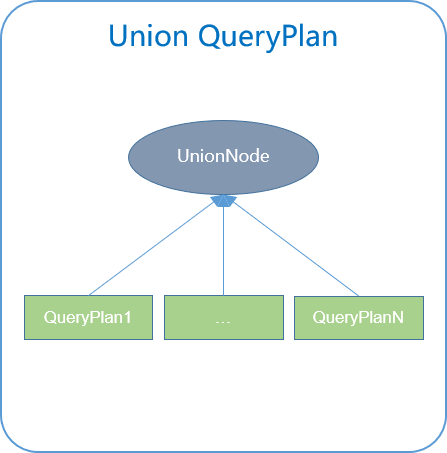
Union 语句处理较为简单:
1.ueryPlan 1..N 分别生成每一个 Union 子句的执行计划树;
2.构造 UnionNode,连接每一个 QueryPlan 的结果集;
Presto 执行计划和节点选择策略
经过执行计划生成和一部分优化后,然后对执行计划进行分段(fragament)。不同阶段的执行计划构成 SubPlan,按照调度类型分为以下几种:
Presto Plugin机制
SPI
Presto 如何初始化 connector?
Presto 没有采用复杂的模块化技术,利用了 JDK 中内置的 ServiceLoader 实现简单的 SPI。ServiceLoader 规范Service Provider Interfaces (http://dwz.date/aAVr),简单来讲就是在src/main/resources/META-INF/services/ 中添加一个名为 io.prestosql.spi.Plugin 的文件, 文件内容的connector中实现了io.prestosql.spi.Plugin 这个接口的类,然后采用如下的伪代码进行隔离加载:
URLClassLoader classLoader = new URLClassLoader(new URL[]{ “plugin-libs” }, Thread.currentThread().getContextClassLoader());ServiceLoader<Plugin> serviceLoader = ServiceLoader.load(Plugin.class, classLoader);Iterator<Plugin> iterator = serviceLoader.iterator();// do something
Google Guice
Google Guice 是从Google 开源的一款轻量级的依赖注入(DI,Dependency Injection)框架。要说依赖注入 Guice 是鼻祖级,但是被 Spring 登了先。Spring功能是越来越全面,但是依赖也越来越重。对于想轻量一点的选择,Guice 是不二之选。
Guice 的一些概念:
Guice:整个框架的门面,通过 Guice 获得 Injector 实例;
Injector:一个依赖的管理上下文
Binder:一个接口和实现的绑定
Module:一组Binder,绑定一组被依赖的中间服务;
Provider:bean的提供者
Scope:Provider的作用域
@Inject:类似Spring Autowired;
@Name:和 Inject 配合使用类似Spring Resource;
在一般的服务,只需要在 构造器上 @Inject 注解,Guice 会自动注入需要的服务和自动处理依赖问题。
Airlift-Guice 注入参数
@Datapublic class AirliftConfigTest {String zookeeperServers;int connectionTimeout = 60_000;@Config("zookeeper.servers")public AirliftConfigTest setZookeeperServers(String zookeeperServers) {this.zookeeperServers = zookeeperServers;return this;}@Config("zookeeper.connection.timeout")public AirliftConfigTest setConnectionTimeout(int connectionTimeout) {this.connectionTimeout = connectionTimeout;return this;}}
实例化且自动注入参数
public static void main(String[] args) {Map<String, String> prop = new HashMap<>();prop.put("zookeeper.connection.timeout", "30000");prop.put("zookeeper.servers", "localhost:2181");try {Bootstrap app = new Bootstrap(new JsonModule(),(binder) -> ConfigBinder.configBinder(binder).bindConfig(AirliftConfigTest.class));Injector injector = app.strictConfig().doNotInitializeLogging().setRequiredConfigurationProperties(prop).initialize();AirliftConfigTest config = injector.getInstance(AirliftConfigTest.class);// config 内参数会自动注入} catch (Exception e) {throw Throwables.propagate(e);}}
Presto Plugin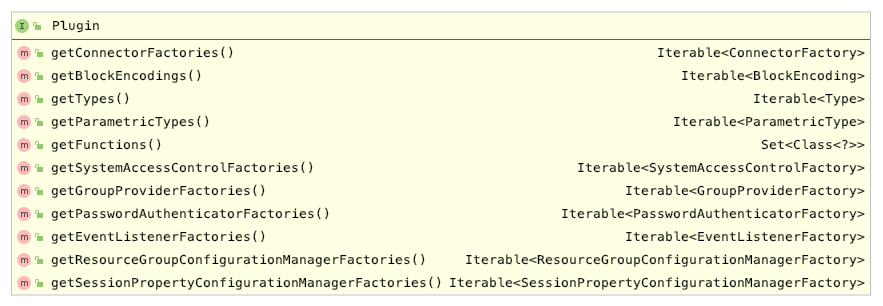
Presto 默认提供的数据类型一般情况下已经足够,一般我们实现一个 Plugin,下面几个方法将会实现:
getFunctions() :类似 Hive UDF;
getGroupProviderFactories():类似 Hive UDAF;
getConnectorFactories() :实现代表 catalog 的 ConnectorFactory;
一个 Plugin 是可以提供多个自定义函数(UDF)、聚合函数(UDAF)和ConnectorFactory,且每个 ConnectorFactory 都可以创建一个 Connector。一个新的 ConnectorFactory 便是一个新的 catalog,可以在 presto-cli 中 —catalog 中指定使用。
Presto Connector 核心API
ConnectorFactory 用于创建一个 Presto Connector。Presto Connector 核心 API,如下图:
ConnectorHandlerResolver:主要是获取该connector中一些handler的类型信息。
ConnectorMetadata :用于支撑 show databases、show tables、desc table; 返回 Connector 的 DB、Table、Column、Index 等信息。
ConnectorIndexResolver:负责根据查询判断是否使用索引,由 Connector 选择实现。
Presto Connector分区执行过程
Hadoop InputFormat
提到分布式架构的分区技术,不得不说说 Hadoop InputFormat,这个是 MapReduce 的基础。
getSplits() 用于在任务启动时计算本次 MR 运行时切分逻辑。如:文件64M一个分片;HBase一个region 一个分片;
createRecordReader(split) 用于在运行时,把每个分片交给一个Task运行。实现分布式运行时数据读取;
split getLocations() 用于返回该分片数据的位置,用于Job调度时能就近调度。如任务运行在数据的节点上,这样可以减少网络开销。
Presto ConnectorSplitManager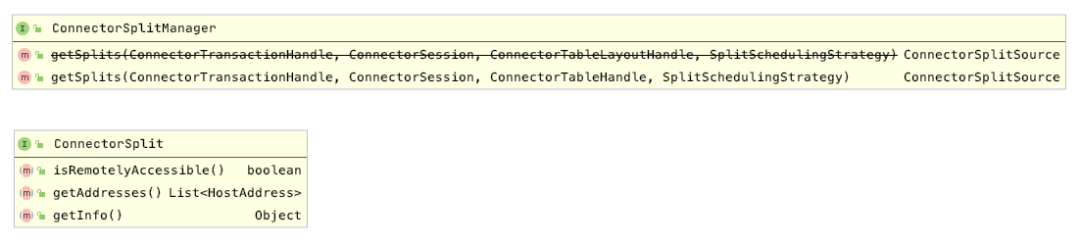
结构上殊途同归!但是,Presto 采用了 Jackon序列反序列化和 Guice IOC 技术,可以在 ConnectorTableHandler 实例化时注入 TupleDomain 对象。TupleDomain 对象包含了完整的 SQL查询经过词法分析后的 WhereCondition 条件信息。可以在Presto Connector 计算数据切分时,根据查询条件缩小数据选择范围。如利用 Hive 分区字段减少数据扫描区间、HBase Region Key减少扫描的Region、数据库索引字段等。
反而,Hadoop InputFormat 在设计时,只是考虑了MapReduce分布式运行下的数据切分,没有考虑到 HIVE、SparkSQL 等引擎在执行时能传入更多底层优化细节。虽然 Hive、SparkSQL能利用分区减少数据读取,但是对于更多SQL优化细节显得力不从心。
ConnectorPageSource
Connector 可通过两个实现:ConnectorPageSourceProvider 和 ConnectorRecordSetProvider 获得数据, 可选择实现任意一个。ConnectorPageSourceProvider 主要创建 ConnectorPageSource 采用 Page 的方式获得数据集。
ConnectorRecordSetProvider 主要适合数据量不大的查询,返回的 RecordSet 类似List。RecordSet 有个 InMemoryRecordSet 默认的实现,用于把返回的数据集直接放到内存List中。如果需要采用游标的方式获得数据需要自行实现 RecordSet 按照 batch 遍历数据。
实际上,Presto Core 也是通过 RecordPageSource 代理 RecordSet 的方式,把 ResourceSet数据集转为 Page的。类图如下: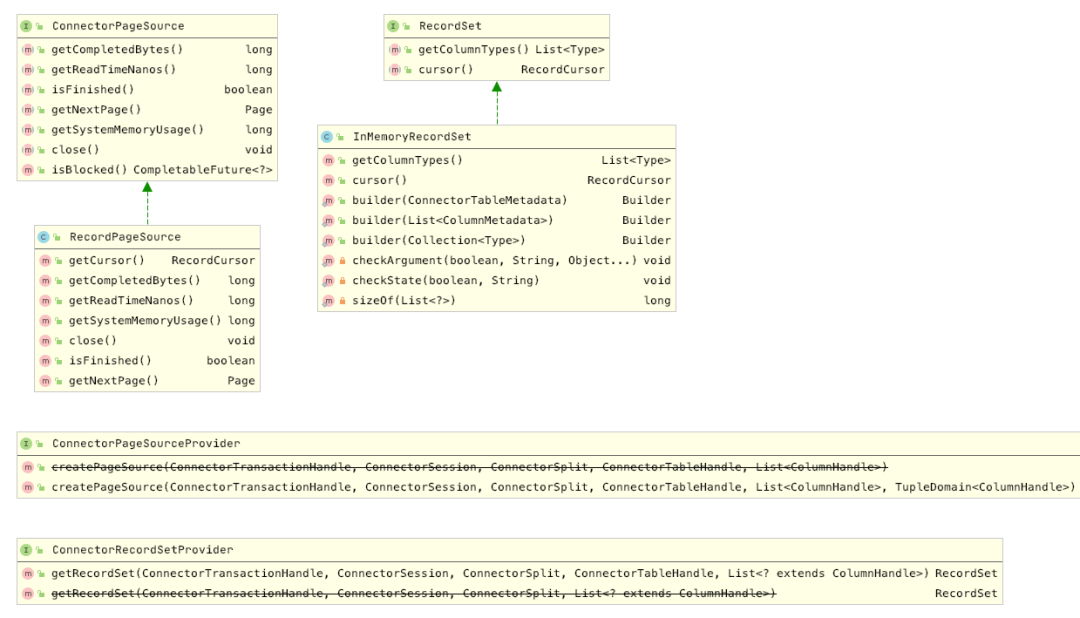
Page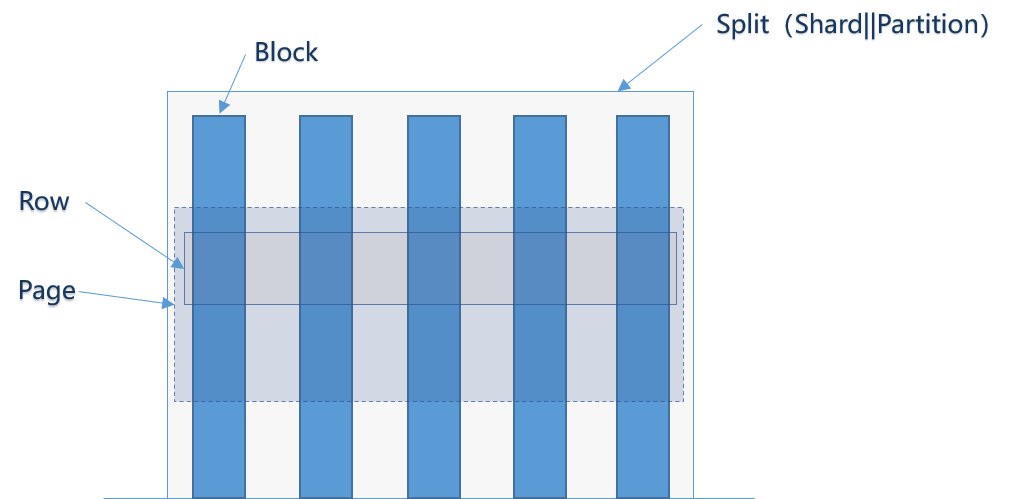
Split:分布式处理的一个数据分区,有的系统叫Shard、Partition等,功能类似;
Page:一个Split中一次返回的多行数据的集合,包含多个列的数据。内部仅提供逻辑行,实际以列式存储。Presto 在判断 isFinish() 为 false时,会一直遍历获得 Page;
Block:一列数据,根据不同类型的数据,通常采取不同的编码方式。如:Slice、Int、Long、Double、Block 等;
Presto查询索引条件下推过程
上文提到,ConnectorSplitManager 在创建 Split 时可以按照查询条件的字段尽量减少数据扫描区间。但有时候查询字段并不包含分区字段,无法明显减少分区数据扫描。这时,Presto 在 Worker 执行 Split 时,仍可再次传入TupleDomain,提供给 ConnectorPageSource 再次利用索引字段查询的能力。
TupleDomain
TupleDomain 初看比较晦涩,但实际上,他是 Presto Core 把用户查询SQL的 Where Clause 按照不同字段做了分组。如:where age > 30 and age < 100 and salary < 10000 会把该查询条件分为两个组。TupleDomain 可以包含零到多组条件,可简单理解为:Map
ColumnHanler:它是一个空接口,由用户实现。一般可包含字段ID、类型、是否索引等;
Domain:是 ValueSet 的浅包装,主要提供了便捷的方法判断字段 IS NULL, IS NOT NULL、等式是单值的还是区间选择等;
ValueSet:一个接口,它有多种实现。实际上所有的判断条件都可以从 ValueSet 来区分。
ValueSet
SortedRangeSet 的 getOrderedRanges() 主要返回了 该 Domain 的查询条件,结合使用 Marker BELOW、EXACTLY、ABOVE 和 Range的左右边界,实现了大于、小于、大于等于、小于等于等逻辑运算。
条件下推的场景
讲了那么多,下推无非就是要把 SQL 的查询逻辑转换为底层可识别的逻辑运算。Presto 只是一个分布式SQL执行引擎,其本身并不管理数据。数据在第三方的存储系统中,因此若要 Presto 高性能执行:
- 需要在 TableScanNode 前期计算分区时返回较少的分区;
- 需要在 Worker 获得 Page 阶段,利用底层索引系统,尽最大可能命中索引的条件,尽量少的返回数据;
底层的存储引擎,可根据业务进行设计,Presto 可把SQL转为具体执行的查询条件,屏蔽底层系统的分库、分区、索引等信息。提供统一的快速的SQL查询引擎,这便是MPP能力。如下:
Solr SolrQuery
ElesticSearch QueryBuilder
MongoDB DocumentQuery
HBase Scan
……

若有收获,就点个赞吧
0 人点赞
