- 1.ConnectorTableMetadata
- 2.ColumnMetadata
- 3.TableMetadata
- 4.CatalogName
- 5.ColumnHandle
- 6.Field
- 7.QualifiedObjectName
- 8.QualifiedName
- 9.Scope
- 10.RelationType
- 11.RelationPlanner
- 12.PlanSymbolAllocator
- 13.RelationPlan
- 14.TableScanNode
- 15.TableHandle
- 16.Symbol
- 17.ReuseExchangeOperator
- 18.RowExpression
- 19.PlanBuilder
- 20.TranslationMap
- 21.CallExpression
- 22.AggregationNode
- 23.PlanOptimizers
- 24.RuleStatsRecorder
- 25.RuleStats
- 26.OptimizerStatsRecorder
- 27.OptimizerStats
- 28.PlanOptimizer
- 29.PlanFragment
- 30.SqlStageExecution
- 31.QuerySnapshotManager
- 32.NodeMap
- 33.NodeTaskMap
- 34.HttpRemoteTask
- 35.ScheduledSplit
- 36.TaskInfo
- 37.ContinuousTaskStatusFetcher
- 38.TaskInfoFetcher
1.ConnectorTableMetadata
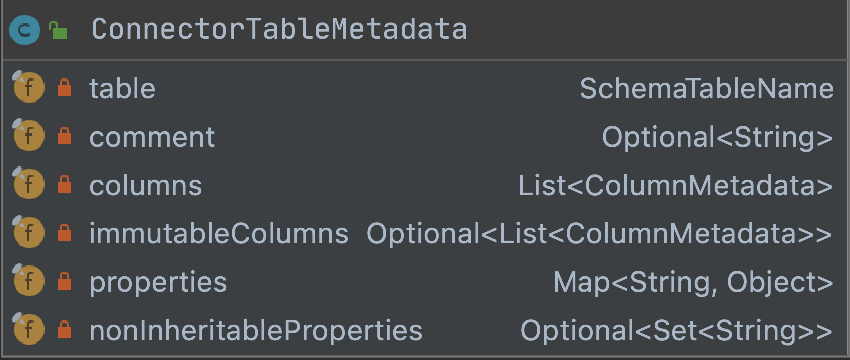
private final SchemaTableName table;private final Optional<String> comment;private final List<ColumnMetadata> columns;private final Optional<List<ColumnMetadata>> immutableColumns;private final Map<String, Object> properties;private final Optional<Set<String>> nonInheritableProperties;
2.ColumnMetadata
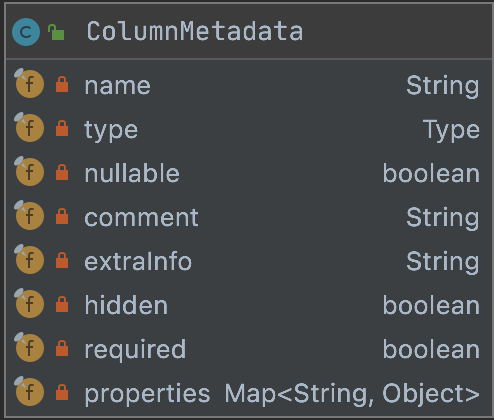
private final String name;private final Type type;private final boolean nullable;private final String comment;private final String extraInfo;private final boolean hidden;private final boolean required;private final Map<String, Object> properties;
3.TableMetadata
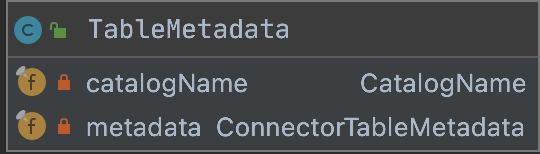
private final CatalogName catalogName;private final ConnectorTableMetadata metadata;
4.CatalogName

private static final String INFORMATION_SCHEMA_CONNECTOR_PREFIX = "$info_schema@";private static final String SYSTEM_TABLES_CONNECTOR_PREFIX = "$system@";private final String catalogName;
5.ColumnHandle
�ColumnHandle是spi模块下的接口类,不同的类型实现的该句柄的信息不一样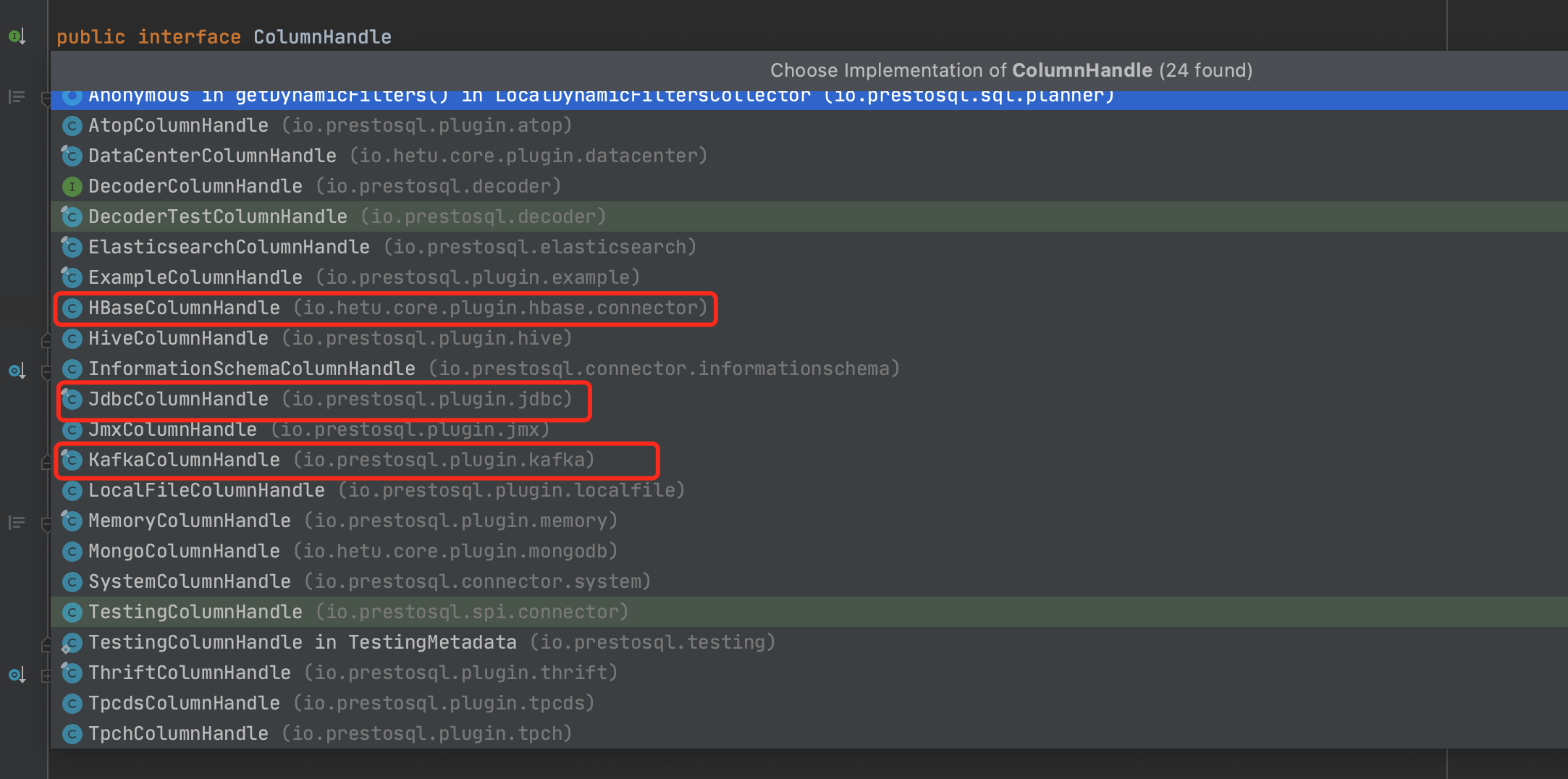
5.1JdbcColumnHandle
以我们最熟悉的JDBC为例,查看对应的列信息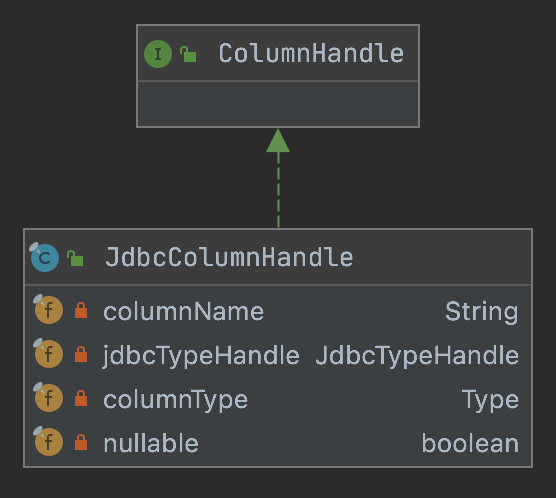
private final String columnName;private final JdbcTypeHandle jdbcTypeHandle;private final Type columnType;private final boolean nullable;
5.1.1 Type
Type是一个接口,不同类型都要实现该类,比如常见:CharType,BigintType等
�
6.Field
字段信息保存的值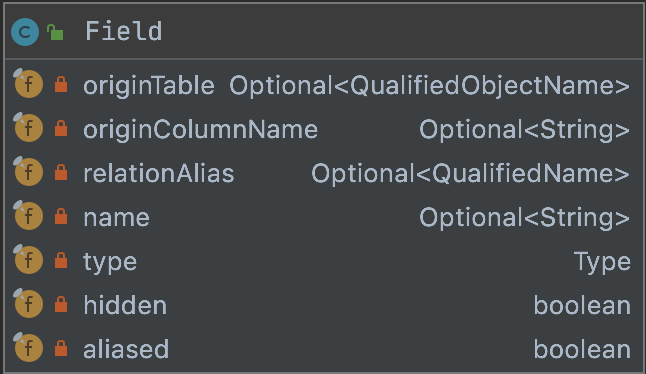
private final Optional<QualifiedObjectName> originTable; // 该字段属于那个catalog的schema下表private final Optional<String> originColumnName; // 原始字段名称private final Optional<QualifiedName> relationAlias;private final Optional<String> name;private final Type type;private final boolean hidden;private final boolean aliased;
7.QualifiedObjectName
限定名,一般用于保存 catalogname.schemaname.object, 类似于:mysql.test.student,其中,mysql是catalogname,test是schemaname,student是object
�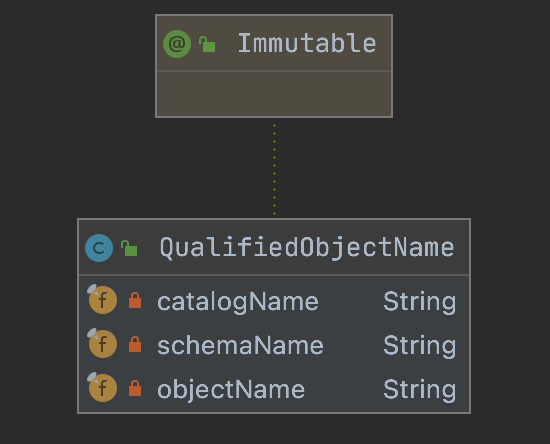
private final String catalogName; // catalogNameprivate final String schemaName; // schemaNameprivate final String objectName; // 对象名
8.QualifiedName
限定名
�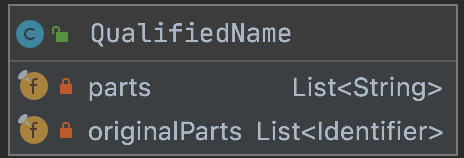
// 用于保存小写格式的限定名,catalog.schema.tableprivate final List<String> parts;// 保存原始的限定名private final List<Identifier> originalParts;
9.Scope
具有范围,作用域的意思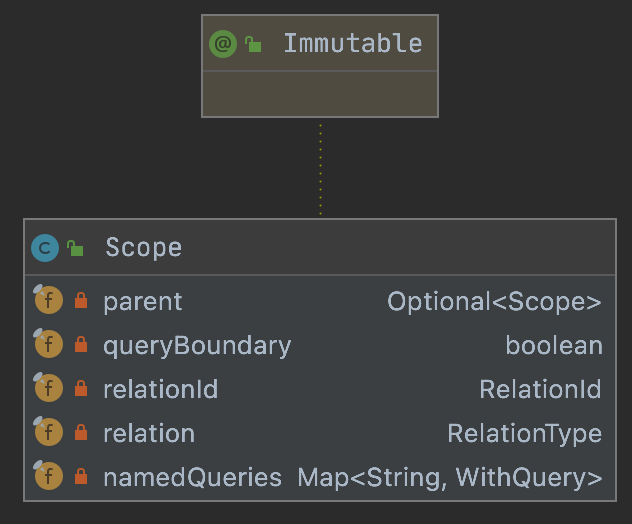
private final Optional<Scope> parent;private final boolean queryBoundary;private final RelationId relationId;private final RelationType relation;private final Map<String, WithQuery> namedQueries;
10.RelationType
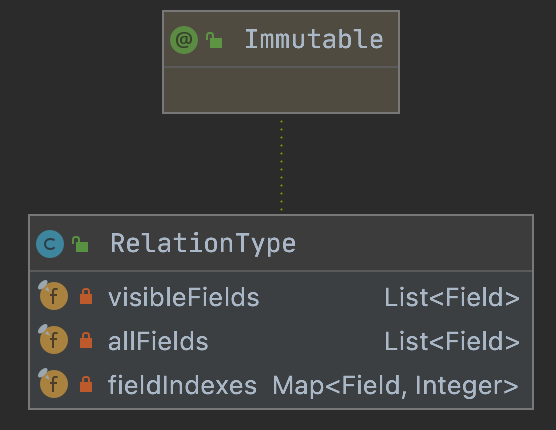
// 可见字段private final List<Field> visibleFields;// 所有字段private final List<Field> allFields;// 字段与索引的映射关系private final Map<Field, Integer> fieldIndexes;
11.RelationPlanner
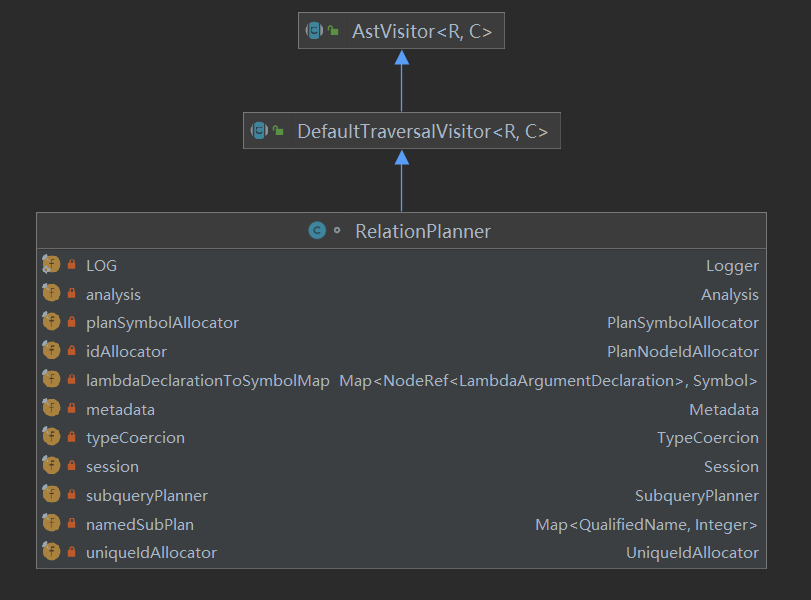
private static final Logger LOG = Logger.get(RelationPlanner.class); // log日志private final Analysis analysis; // 保存分析过程的private final PlanSymbolAllocator planSymbolAllocator; // 标识分配器private final PlanNodeIdAllocator idAllocato // 计划节点分配器private final Map<NodeRef<LambdaArgumentDeclaration>, Symbol> lambdaDeclarationToSymbolMap; // lambda声明到标识映射关系private final Metadata metadata; // 元数据private final TypeCoercion typeCoercion; // 类型private final Session session; // 会话private final SubqueryPlanner subqueryPlanner; // 子计划private final Map<QualifiedName, Integer> namedSubPlan; // 列名 与 索引映射关系private final UniqueIdAllocator uniqueIdAllocator; // 唯一分配器
12.PlanSymbolAllocator
private final Map<Symbol, Type> symbols; //字段映射关系private int nextId; //
13.RelationPlan
private final PlanNode root; // 计划节点// 来自root节点对应的标识号private final List<Symbol> fieldMappings; // for each field in the relation, the corresponding symbol from "root"// 范围private final Scope scope;
14.TableScanNode
TableScanNode继承自PlanNode节点
private final TableHandle table; // 表句柄信息,包含了连接表的信息private final List<Symbol> outputSymbols;private final Map<Symbol, ColumnHandle> assignments; // symbol -> columnprivate final TupleDomain<ColumnHandle> enforcedConstraint;private final Optional<RowExpression> predicate;private final boolean forDelete;private ReuseExchangeOperator.STRATEGY strategy;private UUID reuseTableScanMappingId;private RowExpression filterExpr;private Integer consumerTableScanNodeCount;
15.TableHandle
private final CatalogName catalogName; // 属于哪个catalogprivate final ConnectorTableHandle connectorHandle; // 以及对应的表的连接信息private final ConnectorTransactionHandle transaction; //
16.Symbol
private final String name;
17.ReuseExchangeOperator
enum STRATEGY {REUSE_STRATEGY_DEFAULT, // 默认重启策略REUSE_STRATEGY_PRODUCER, // 生产者重启策略REUSE_STRATEGY_CONSUMER // 消费者重启策略}
18.RowExpression
RowExpression实现不同行表达式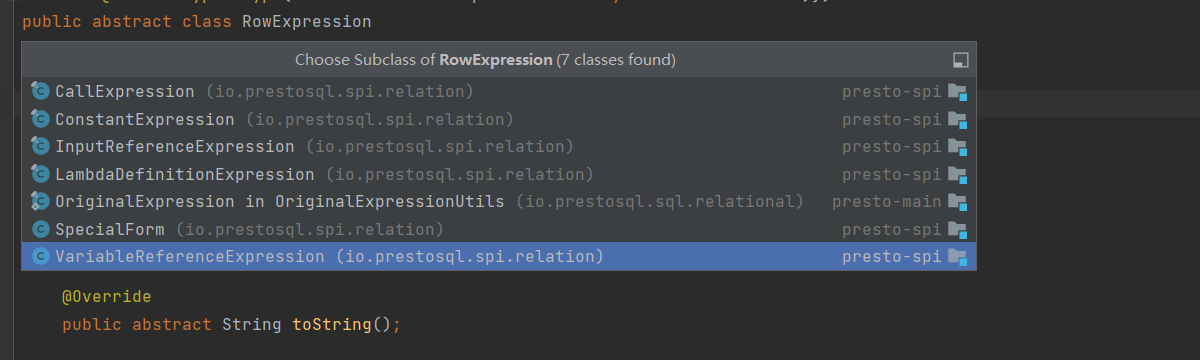
19.PlanBuilder
private final TranslationMap translations;private final List<Expression> parameters;private final PlanNode root;
20.TranslationMap
跟踪字段和表达式以及它们到当前计划中的符号的映射
// all expressions are rewritten in terms of fields declared by this relation plan// 所有表达式都根据此关系计划声明的字段重写private final RelationPlan rewriteBase;private final Analysis analysis;private final Map<NodeRef<LambdaArgumentDeclaration>, Symbol> lambdaDeclarationToSymbolMap;// current mappings of underlying field -> symbol for translating direct field references// 基础字段的当前映射 -> 用于翻译直接字段引用的符号private final Symbol[] fieldSymbols;// current mappings of sub-expressions -> symbolprivate final Map<Expression, Symbol> expressionToSymbols = new HashMap<>();private final Map<Expression, Expression> expressionToExpressions = new HashMap<>();
21.CallExpression
private final String displayName;private final FunctionHandle functionHandle;private final Type returnType;private final List<RowExpression> arguments;private final Optional<RowExpression> filter;

22.AggregationNode
private final PlanNode source;private final Map<Symbol, Aggregation> aggregations;private final GroupingSetDescriptor groupingSets;private final List<Symbol> preGroupedSymbols;private final Step step;private final Optional<Symbol> hashSymbol;private final Optional<Symbol> groupIdSymbol;private final List<Symbol> outputs;
23.PlanOptimizers
PlanOptimizers 优化器集合
private final List<PlanOptimizer> optimizers;private final RuleStatsRecorder ruleStats = new RuleStatsRecorder();private final OptimizerStatsRecorder optimizerStats = new OptimizerStatsRecorder();private final MBeanExporter exporter;
24.RuleStatsRecorder
规则状态记录器
private final Map<Class<?>, RuleStats> stats = new HashMap<>(); // 标识一个类与规则状态映射关系
25.RuleStats
private final AtomicLong hits = new AtomicLong();private final TimeDistribution time = new TimeDistribution(TimeUnit.MICROSECONDS);private final AtomicLong failures = new AtomicLong();
TimeDistribution 需要测试一下
26.OptimizerStatsRecorder
private final Map<Class<?>, OptimizerStats> stats = new HashMap<>();
27.OptimizerStats
private final AtomicLong failures = new AtomicLong();private final TimeDistribution time = new TimeDistribution(TimeUnit.MICROSECONDS);
28.PlanOptimizer
PlanOptimizer是一个接口,所有关于优化相关操作,都需要继承该接口,实现optimize方法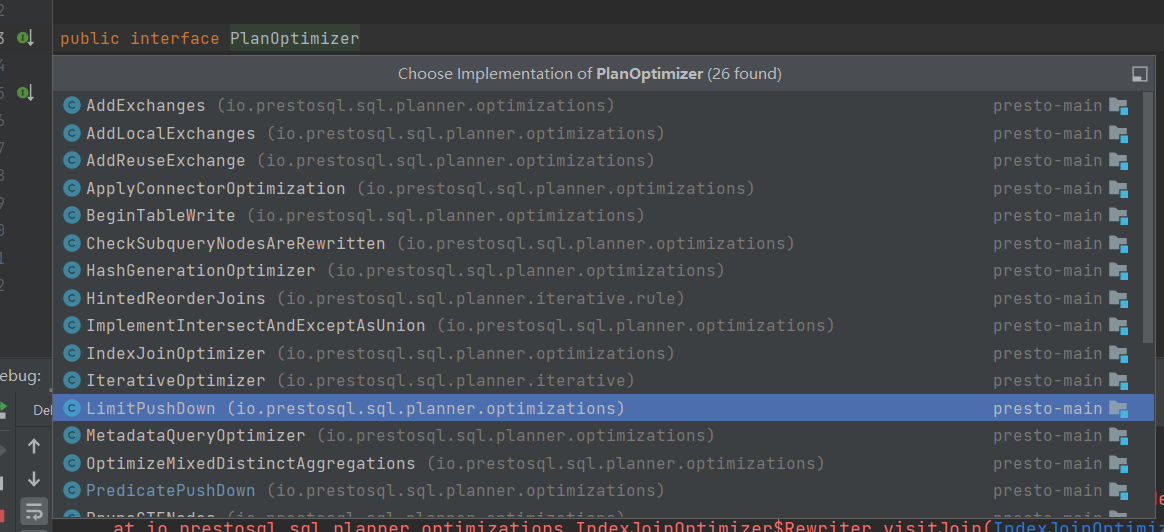
29.PlanFragment
private final PlanFragmentId id; //private final PlanNode root;private final Map<Symbol, Type> symbols;private final PartitioningHandle partitioning;private final List<PlanNodeId> partitionedSources;private final Set<PlanNodeId> partitionedSourcesSet;private final List<Type> types;private final Set<PlanNode> partitionedSourceNodes;private final List<RemoteSourceNode> remoteSourceNodes;private final PartitioningScheme partitioningScheme;private final StageExecutionDescriptor stageExecutionDescriptor;private final StatsAndCosts statsAndCosts;private final Optional<String> jsonRepresentation;private final Optional<PlanFragmentId> feederCTEId;private final Optional<PlanNodeId> feederCTEParentId;
30.SqlStageExecution
private static final Logger log = Logger.get(SqlStageExecution.class);private final StageStateMachine stateMachine; // 状态机private final RemoteTaskFactory remoteTaskFactory; // 任务工厂类private final NodeTaskMap nodeTaskMap; // 保存 node 与 task 的映射关系private final boolean summarizeTaskInfo; // 是否总结任务信息private final Executor executor; // 执行器private final FailureDetector failureDetector; // 失败探测器private final Map<PlanFragmentId, RemoteSourceNode> exchangeSources; // 计划分段与源节点映射关系private final Map<InternalNode, Set<RemoteTask>> tasks = new ConcurrentHashMap<>(); // 节点 与 任务的映射关系, 每个节点所包含的任务个数@GuardedBy("this")private final AtomicInteger nextTaskId = new AtomicInteger(); // 下个taskId@GuardedBy("this")private final Set<TaskId> allTasks = newConcurrentHashSet(); // 所有的任务列表@GuardedBy("this")private final Set<TaskId> finishedTasks = newConcurrentHashSet(); // 已经完成的任务列表@GuardedBy("this")private final Set<TaskId> tasksWithFinalInfo = newConcurrentHashSet(); // 已经完成任务的最终消息@GuardedBy("this")private final AtomicBoolean splitsScheduled = new AtomicBoolean(); // 是否开启切片调度@GuardedBy("this")private final Multimap<PlanNodeId, RemoteTask> sourceTasks = HashMultimap.create(); // 源任务@GuardedBy("this")private final Set<PlanNodeId> completeSources = newConcurrentHashSet(); // 已经完成的 源节点@GuardedBy("this")private final Set<PlanFragmentId> completeSourceFragments = newConcurrentHashSet(); // 已经完成的计划分片private final AtomicReference<OutputBuffers> outputBuffers = new AtomicReference<>(); // 输出缓存private final ListenerManager<Set<Lifespan>> completedLifespansChangeListeners = new ListenerManager<>(); // 已经完成的 生命周期变化 监听器private final DynamicFilterService dynamicFilterService; // 动态过滤服务private final AtomicBoolean dynamicFilterSchedulingInfoPropagated = new AtomicBoolean(); // 传播的动态过滤器调度信息@GuardedBy("SqlStageExecution.class")public static Map<QueryId, List<UUID>> queryIdReuseTableScanMappingIdFinishedMap = new ConcurrentHashMap<>();private PlanNodeId parentId;private final QuerySnapshotManager snapshotManager;private boolean throttledSchedule;
31.QuerySnapshotManager
/*
- On the coordinator, it keeps track of snapshot status of all queries 在协调器节点, 它始终跟踪所有查询的状态
- On workers, it serves as a bridge between TaskSnapshotManager instances and the SnapshotStoreClient 在work节点, 工作节点作为 任务快照管理实例 和 快照存储客户端的 连接桥梁
/
32.NodeMap
private final SetMultimap<HostAddress, InternalNode> nodesByHostAndPort;private final SetMultimap<InetAddress, InternalNode> nodesByHost;private final SetMultimap<NetworkLocation, InternalNode> workersByNetworkPath;private final Set<String> coordinatorNodeIds;
33.NodeTaskMap
private static final Logger log = Logger.get(NodeTaskMap.class);private final ConcurrentHashMap<InternalNode, NodeTasks> nodeTasksMap = new ConcurrentHashMap<>(); // 节点与任务的关系private final FinalizerService finalizerService;
34.HttpRemoteTask
private static final Logger log = Logger.get(HttpRemoteTask.class);private final TaskId taskId; // 任务的IDprivate final Session session; // 会话信息private final String nodeId; // nodeIDprivate final PlanFragment planFragment; // 计划片段private final OptionalInt totalPartitions; // 所有分区数private final AtomicLong nextSplitId = new AtomicLong(); // 下一个splitprivate final RemoteTaskStats stats; // 保存任务统计信息private final TaskInfoFetcher taskInfoFetcher; // 任务信息收集器, 包括任务失败,成功的状态, 链接信息private final ContinuousTaskStatusFetcher taskStatusFetcher; // 持续@GuardedBy("this")private Future<?> currentRequest; // 当前请求信息@GuardedBy("this")private long currentRequestStartNanos; // 当前请求时间@GuardedBy("this")//LinkedHashMultimap is used to preserve the order of insertion in addSplits.//It guarantees that TaskSources and their Splits will be sent in the order they're received.private final SetMultimap<PlanNodeId, ScheduledSplit> pendingSplits = LinkedHashMultimap.create(); // 保存已经添加的split集合@GuardedBy("this")private volatile int pendingSourceSplitCount; // 已经添加源split的个数@GuardedBy("this")private final SetMultimap<PlanNodeId, Lifespan> pendingNoMoreSplitsForLifespan = HashMultimap.create();@GuardedBy("this")// The keys of this map represent all plan nodes that have "no more splits".// The boolean value of each entry represents whether the "no more splits" notification is pending delivery to workers.// 这个map中的key表示所有计划节点没有split// value的boolean表示否是将"no more splits" 通知信息发送给worker节点private final Map<PlanNodeId, Boolean> noMoreSplits = new HashMap<>();@GuardedBy("this")private final AtomicReference<OutputBuffers> outputBuffers = new AtomicReference<>(); // 输出缓存private final FutureStateChange<?> whenSplitQueueHasSpace = new FutureStateChange<>(); //@GuardedBy("this")private boolean splitQueueHasSpace = true;@GuardedBy("this")private OptionalInt whenSplitQueueHasSpaceThreshold = OptionalInt.empty();private final boolean summarizeTaskInfo;private final HttpClient httpClient;private final Executor executor;private final ScheduledExecutorService errorScheduledExecutor; // 调度错误的执行期private final Codec<TaskInfo> taskInfoCodec; // 序列化任务信息private final Codec<TaskUpdateRequest> taskUpdateRequestCodec; // 序列化任务更新请求private final RequestErrorTracker updateErrorTracker; //private final AtomicBoolean needsUpdate = new AtomicBoolean(true);private final AtomicBoolean sendPlan = new AtomicBoolean(true);private final PartitionedSplitCountTracker partitionedSplitCountTracker;private final AtomicBoolean aborting = new AtomicBoolean(false);private final AtomicBoolean abandoned = new AtomicBoolean(false);private final AtomicBoolean cancelledToResume = new AtomicBoolean(false);private final boolean isBinaryEncoding;private Optional<PlanNodeId> parent; // 是否有父节点
35.ScheduledSplit
private final long sequenceId; // 顺序IDprivate final PlanNodeId planNodeId; // 节点的IDprivate final Split split; // 节点对应的split
36.TaskInfo
private final TaskStatus taskStatus; // 任务状态数据private final DateTime lastHeartbeat; // 记录最后一次的时间private final OutputBufferInfo outputBuffers; // 输出的缓存信息private final Set<PlanNodeId> noMoreSplits; // planNode集合private final TaskStats stats; // 任务统计信息private final boolean needsPlan; //
37.ContinuousTaskStatusFetcher
private static final Logger log = Logger.get(ContinuousTaskStatusFetcher.class);private final TaskId taskId; // task IDprivate final Consumer<Throwable> onFail; // task失败进行的回调函数private final StateMachine<TaskStatus> taskStatus; // 任务状态机private final Codec<TaskStatus> taskStatusCodec; // 序列化任务状态信息private final Duration refreshMaxWait;private final Executor executor;private final HttpClient httpClient;private final RequestErrorTracker errorTracker;private final RemoteTaskStats stats;private final boolean isBinaryEncoding;private final AtomicLong currentRequestStartNanos = new AtomicLong();@GuardedBy("this")private boolean running;@GuardedBy("this")private ListenableFuture<BaseResponse<TaskStatus>> future;private final QuerySnapshotManager snapshotManager;
38.TaskInfoFetcher
用于收集worker任务信息。保存的信息与ContinuousTaskStatusFetcher类似
private final TaskId taskId;private final Consumer<Throwable> onFail;private final StateMachine<TaskInfo> taskInfo;private final StateMachine<Optional<TaskInfo>> finalTaskInfo;private final Codec<TaskInfo> taskInfoCodec;private final long updateIntervalMillis;private final AtomicLong lastUpdateNanos = new AtomicLong();private final ScheduledExecutorService updateScheduledExecutor;private final Executor executor;private final HttpClient httpClient;private final RequestErrorTracker errorTracker;private final boolean summarizeTaskInfo;@GuardedBy("this")private final AtomicLong currentRequestStartNanos = new AtomicLong();private final RemoteTaskStats stats;private final boolean isBinaryEncoding;@GuardedBy("this")private boolean running;
�

若有收获,就点个赞吧
0 人点赞
