1. 背景
calcite作为一款开源的动态数据管理框架(https://calcite.apache.org/),它具备很多典型数据库管理系统的功能,比如SQL解析、SQL校验、SQL查询优化、SQL生成以及数据连接查询等,但是又省略了一些关键的功能,比如Calcite并不存储相关的元数据和基本数据,不完全包含相关处理数据的算法等。
也正是因为Calcite本身与数据存储和处理的逻辑无关,所以这让它成为与多个数据存储位置(数据源)和多种数据处理引擎之间进行调解的绝佳选择。
Calcite所做的工作就是将各种SQL语句解析成抽象语法树(AST Abstract Syntax Tree),并根据一定的规则或成本对AST的算法与关系进行优化,最后推给各个数据处理引擎进行执行。
Calcite整体架构如下图所示: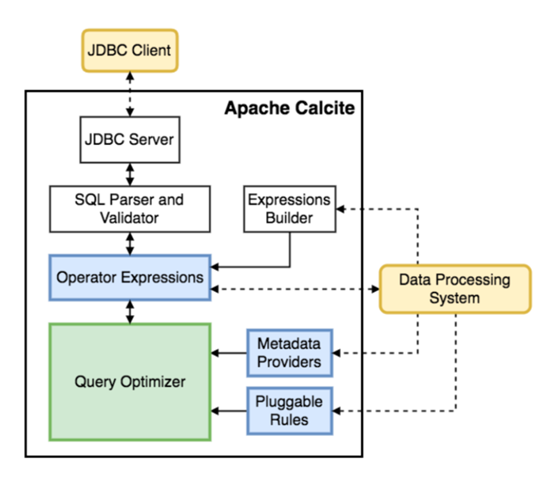
Hive,Flink,Storm都使用Calcite作为其SQL解析优化引擎。
2. Calcite适配器
这里需要提到一个重要的概念:Schema adapters(https://calcite.apache.org/docs/adapter.html)
A schema adapter allows Calcite to read particular kind of data, presenting the data as tables within a schema.
Calcite默认支持的Schema adapters如下: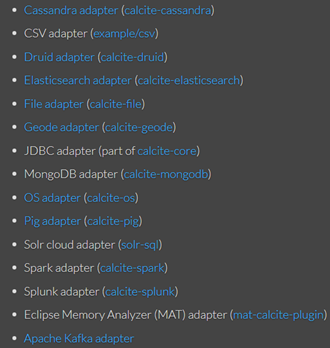
换句话说,calcite为了能够适配各类数据源,需要添加适配器来对接,适配程度和适配器完善程度相关,例如JDBC adapter当前就存在一定限制,只能下推scan到底层JDBC源,其他操作无法下推:
3. Calcite自定义适配器Adapters
1、定义schema,需先构建对应适配器schema类(例如DB数据库里,schema对应DataBase,这里就需要返回对应DataBase对象),然后实现SchemaFactory、Table、TableScan等接口
2、实现Table,表示某种类型的表,需实现TableFactory接口
3、实现SQL到DQL/DML/DDL的转换,需实现QueryableTable、FilterableTable(或者ProjectableFilterableTable)、ModifiableTable等接口。如果需要处理流式数据,需实现StreamableTable接口
4、如果需要自定义字段类型,需实现RelDataTypeSystem接口
简单来说,实现只有全表扫描功能的adapter步骤:
- 自定义Schema
- 自定义Schema Factory
- 自定义Table
- 自定义Enumerator
4. SQL Dialect方言转换
Calcite支持接收和自定义SQL方言:
目前有许多实现SqlDialect方言类接口的类,如果要自定义方言类,继承这个SqlDialect接口,并在SqlDialectFactoryImpl、SqlDialect中添加对应case即可
注意继承SqlDialect接口的时候,实现unparseCall方法最为重要,Default也需要根据对应方言类型的要求进行构造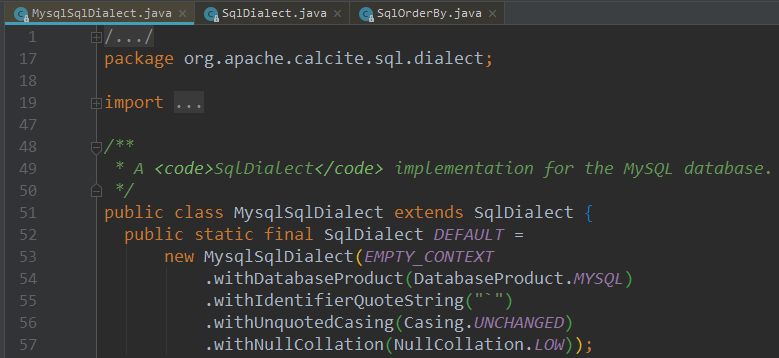
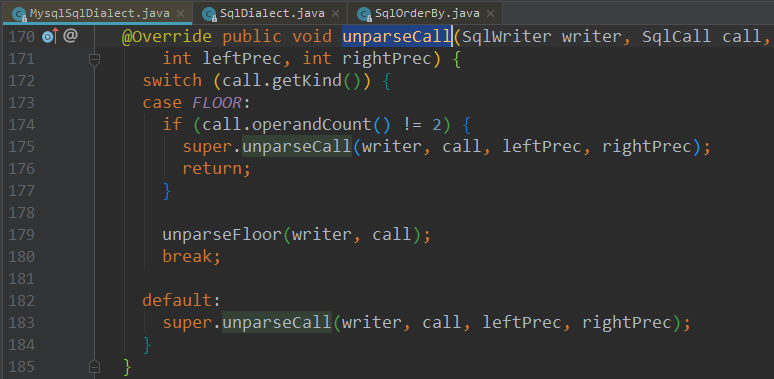
5. 方言转换Demo
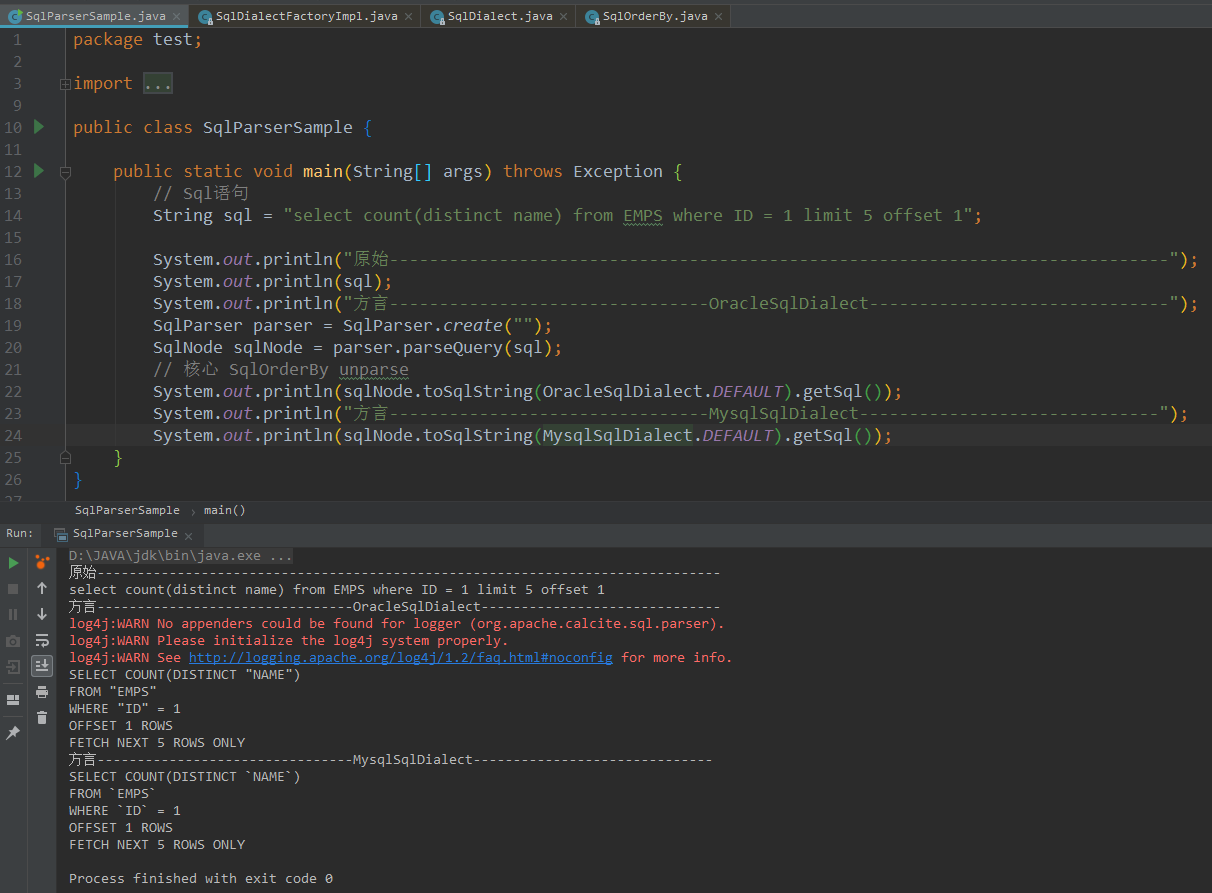
从这个demo可以看到sql经过不同方言类转换得到的sql均不相同,debug sqlNode.toSqlString方法即可看到sql组装的过程

若有收获,就点个赞吧
0 人点赞
