本文主要从源码的角度看一下,ClickHouse是如何实现这两个核心的机制的数据抽象的。
代码组织
首先看一下大体工作量, 理解开发一个数据库, 工作量在哪些主要的地方。 大致分为4大部分:
- 前端SQL的输入执行
- 对象数据的组织
- 后台执行
- 存储压缩
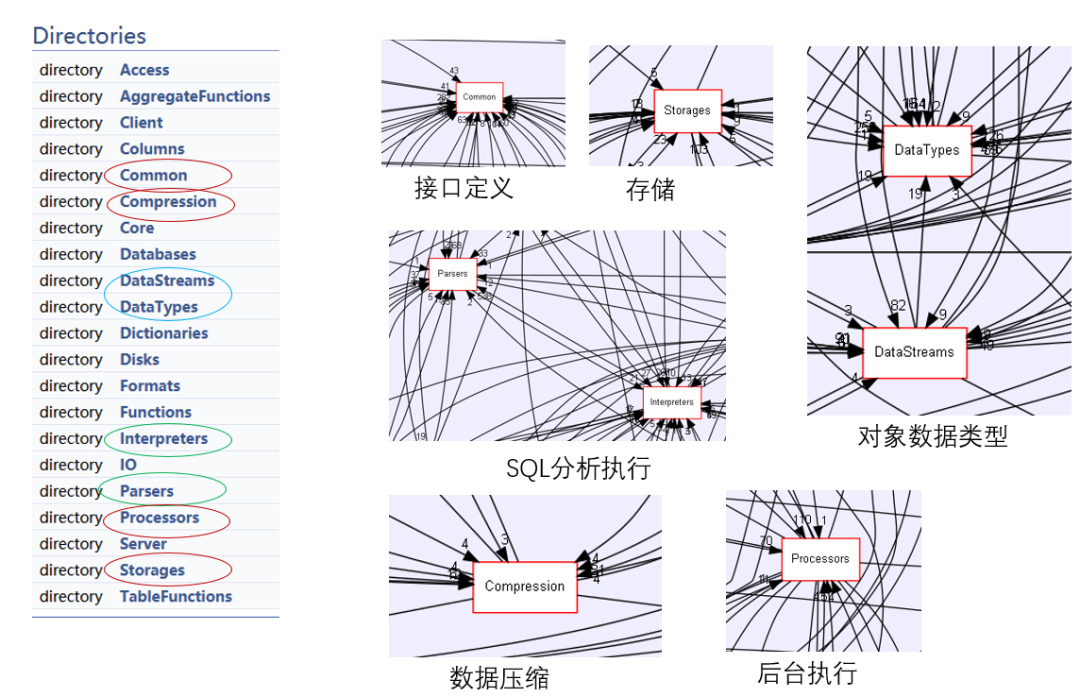
Column组织
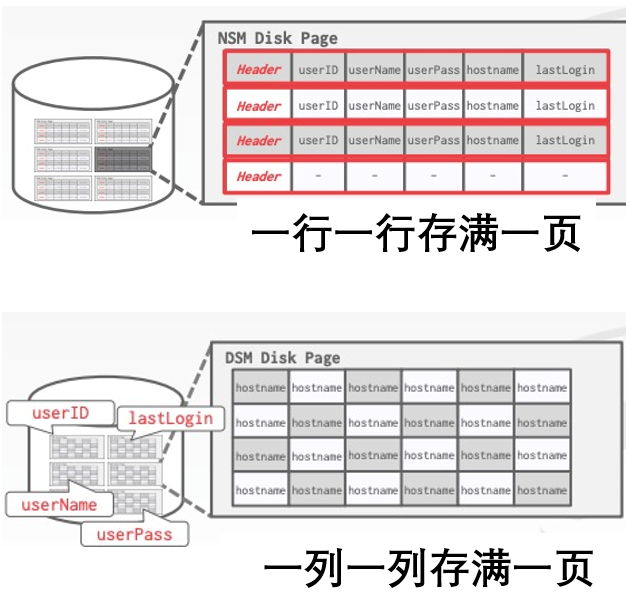
首先看一下回顾一下,”开源大数据平台架构(下)“提到,大数据平台文件存储有3种格式, 行模式Avro, 例模式的Parquent和ORC。 而Non-SQL的Column Family也有两种组织方式,一种是横向划分,如Cassandra, 另外一种是纵向划分,如HBase。 所以回到数据库领域也有两个专业名称叫:
- 行存储:N-ary Storage Model (NSM) - 写优化,读浪费
- 列存储:Decomposition Storage Model (DSM) - 写费劲, 读高效
所以, ClickHouse也是以读为主进行OLAP数据处理的。一般也需要基于例模式进行vectorized query execution, VQE加速。 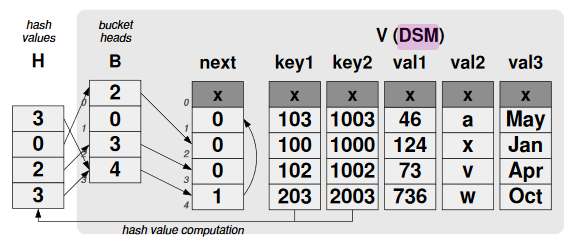
所以,在数据结构上, ClickHouse, CH把所有的对象全部封装成虚类IColumn, 然后COWHelper之上封装。 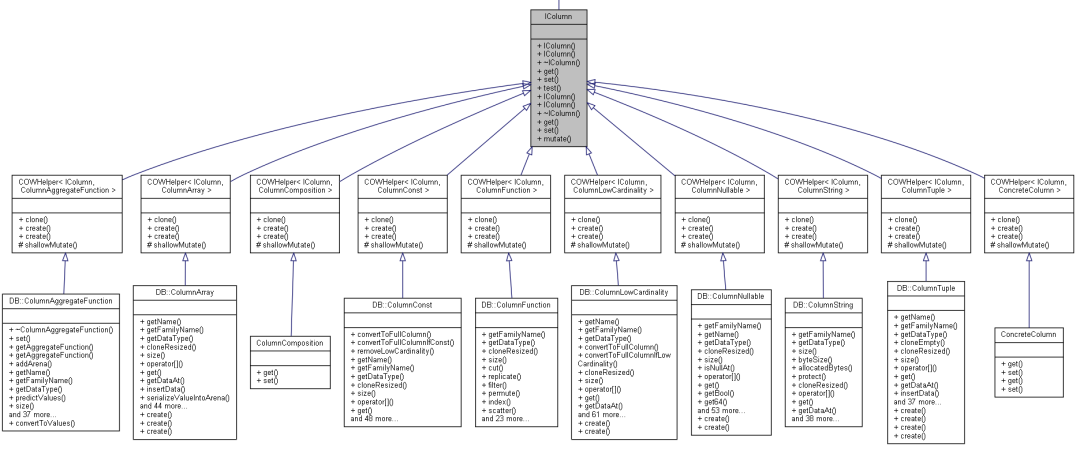
对于定长的数据,就是固定单元存储,对于不定长的数据, ClickHouse,给出两个数组进行存储和Offset维护。 例如:ColumnArray:
对比一下,ColumnUInt8 数据存储
表组织
还有一个存储的基础类叫IStorage,所有的存储都是这个类的延伸。 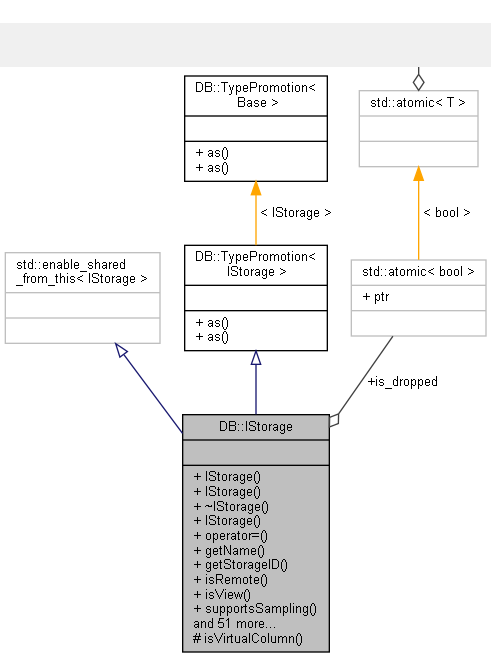
举几个重要相关的, 例如IStorageSystemOneBlock,系统块存储单元。 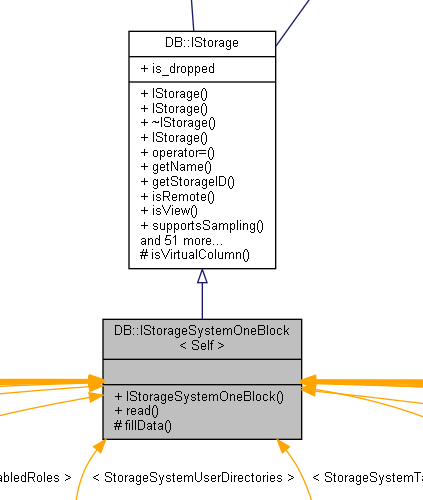
例如MergeTreeData。是实现MergeTree数据组织的核心类。 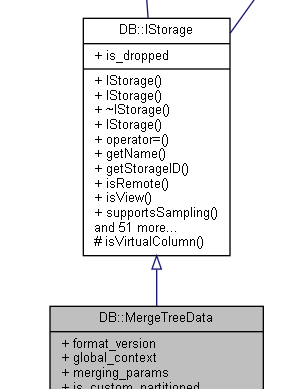
MergeTree组织
另外再看一下,MergeTree大概有以下几种类型。SummingMergeTree
在代码里面, 这些不同的MergeTree共享同样的基础数据类MergeTreeData 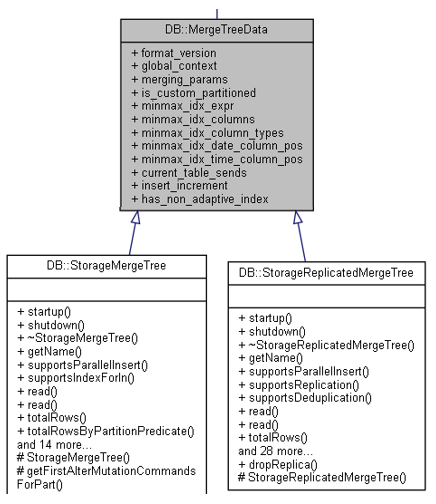
在参数上以7种Mode的方式进行支持 (注意,4没有,可能以前有的一种模式取消了)。 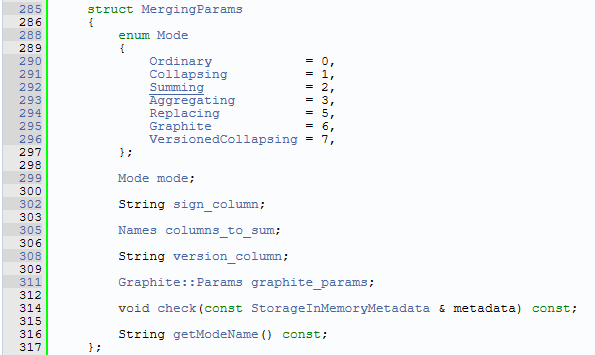
再进一步,我们看一下Policy是如何使用到MergeTree里面的。 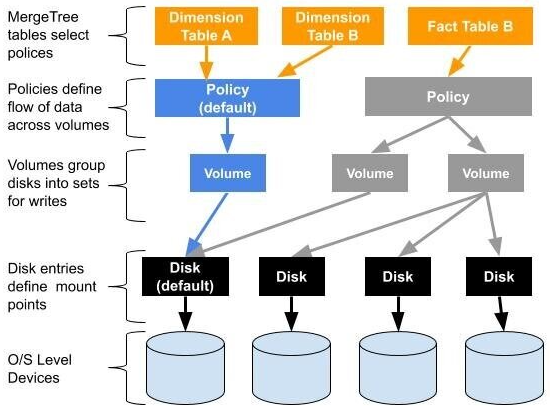
核心的MergeTree功能需要在执行的开始读取Policy: 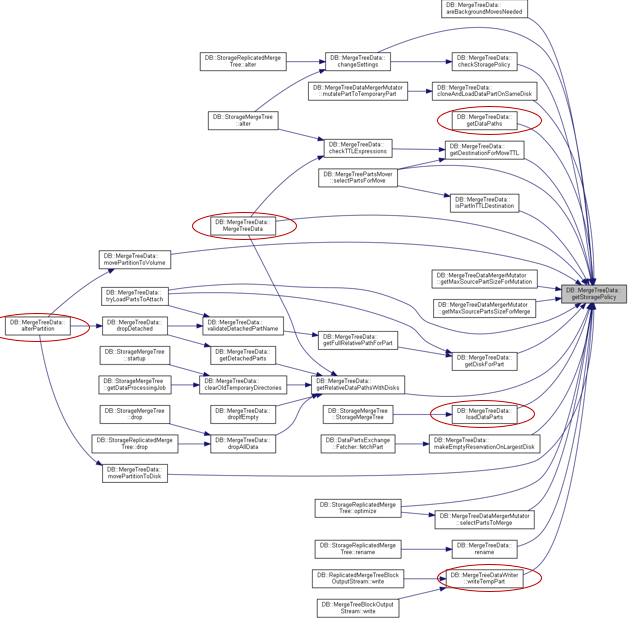
另外MergeTree 和还提供4种Index索引, BloomFilter, MinMax, Set, FullText。 
类似的MergeTreeIndexAggregator也是4种: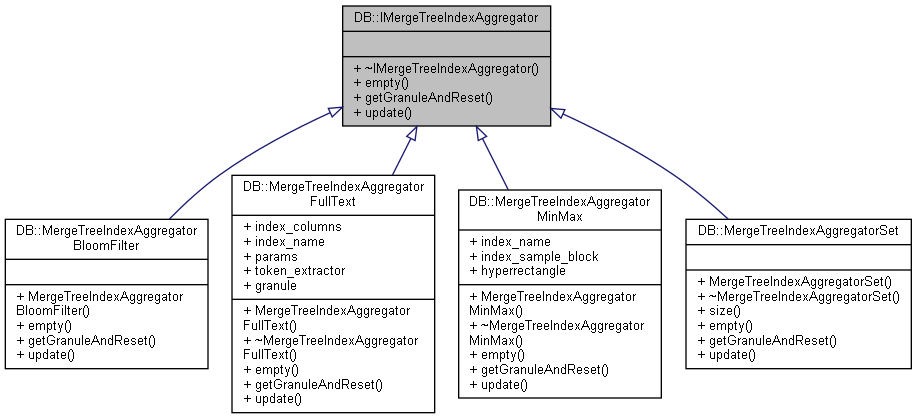
三种Function接口
再进一步, 对于所有的计算函数,都提供向量化版本,通过FunctionMathUnary来实现。 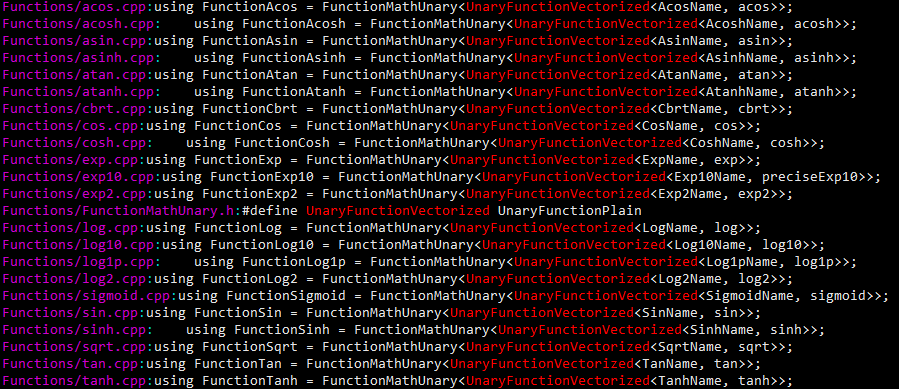
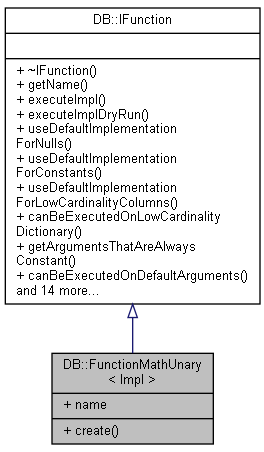
扩展一下, 除了数据的Function外,其实还支持两种类型Function:
- IAggregateFunction
- ITableFunction
IAggregateFunction 主要是数据之间的聚合操作的。后面有庞大的函数实现。 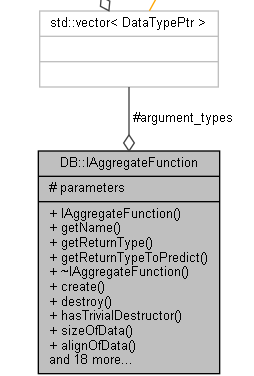
机器学习接口
ITableFunction就是对整张表操作的一些功能。 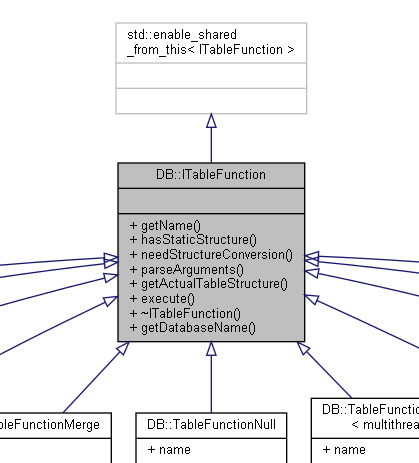
最后,想提醒下ClickHouse也支持了机器学习的接口, IModel。 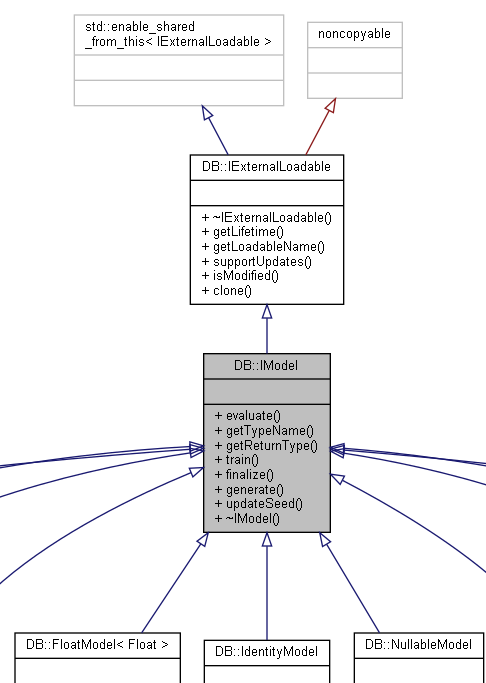
例如著名的Gradient Boost算法 就能直接在ClickHouse里面使用。 可惜的是内嵌的Boost函数是他们直接实现的CatBoost函数, 我想不久就会有同胞把XGBoost也内嵌到CH里面去了。 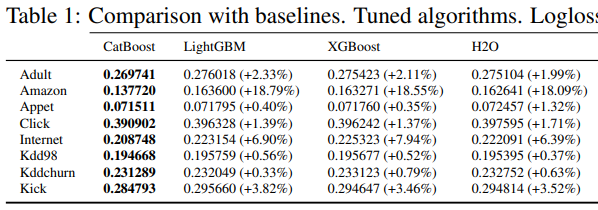
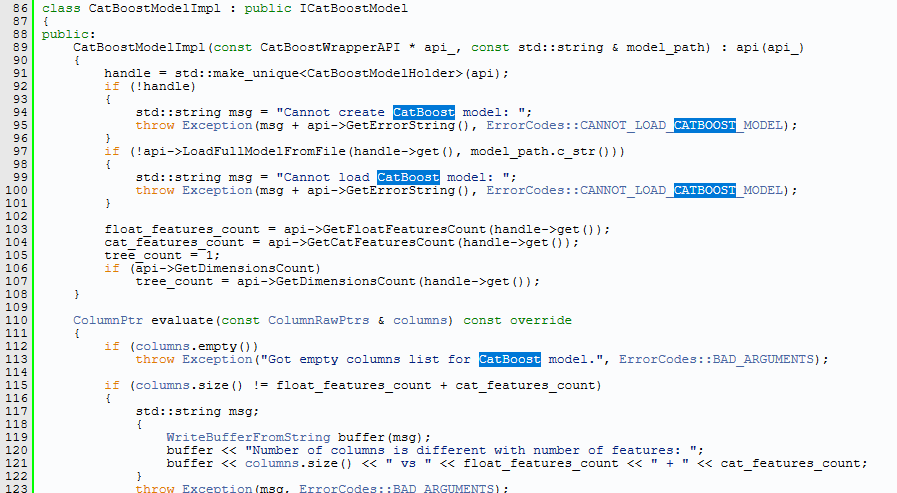
具体算法测试流程大概要5步:
小结:
ClickHouse的代码还是非常清晰可读的, 不过代码量有点大,3000多个文件。 如果能分拆项目成插件形式可能更酷。

若有收获,就点个赞吧
0 人点赞
