PlanOptimizer
// This method was introduced separate logical planning from query analyzing stage// and allow plans to be overwritten by CachedSqlQueryExecutionprotected Plan createPlan(Analysis analysis,Session session,List<PlanOptimizer> planOptimizers,PlanNodeIdAllocator idAllocator,Metadata metadata,TypeAnalyzer typeAnalyzer,StatsCalculator statsCalculator,CostCalculator costCalculator,WarningCollector warningCollector){// 逻辑执行计划器LogicalPlanner logicalPlanner = new LogicalPlanner(session,planOptimizers,idAllocator,metadata,typeAnalyzer,statsCalculator,costCalculator,warningCollector);// 逻辑执行计划return logicalPlanner.plan(analysis);}
优化器进行执行
public Plan plan(Analysis analysis){return plan(analysis, Stage.OPTIMIZED_AND_VALIDATED);}public Plan plan(Analysis analysis, Stage stage){// 获取根节点 root, 从statement 执行计划语句PlanNode root = planStatement(analysis, analysis.getStatement());//检查执行计划的有效性planSanityChecker.validateIntermediatePlan(root, session, metadata, typeAnalyzer, planSymbolAllocator.getTypes(), warningCollector);if (stage.ordinal() >= Stage.OPTIMIZED.ordinal()) {for (PlanOptimizer optimizer : planOptimizers) {if (OptimizerUtils.isEnabledLegacy(optimizer, session, root)) {//对生成的逻辑执行进行优化 执行计划优化器root = optimizer.optimize(root, session, planSymbolAllocator.getTypes(), planSymbolAllocator, idAllocator,warningCollector);requireNonNull(root, format("%s returned a null plan", optimizer.getClass().getName()));}}}if (stage.ordinal() >= Stage.OPTIMIZED_AND_VALIDATED.ordinal()) {// make sure we produce a valid plan after optimizations run. This is mainly to catch programming errorsplanSanityChecker.validateFinalPlan(root, session, metadata, typeAnalyzer, planSymbolAllocator.getTypes(), warningCollector);}TypeProvider types = planSymbolAllocator.getTypes();StatsProvider statsProvider = new CachingStatsProvider(statsCalculator, session, types);CostProvider costProvider = new CachingCostProvider(costCalculator, statsProvider, Optional.empty(), session, types);return new Plan(root, types, StatsAndCosts.create(root, statsProvider, costProvider));}
以PredicatePushDown为例,讲解谓词下沉,如何进行优化
Predicate PushDown优化器用于将过滤条件进行下推, 同样可以减少下层节点所处理的数据量,提高执行效率。
- 当经过Project Node时, 仅下推确定性的过滤条件, 如果包含不确定性的过滤条件如rand函数, 则根据不确定性的过滤条件添加一个Filter Node。
- 当经过Union Node时, 将过滤条件下推到Union的所有子查询中。
- 对于Join Node, 由于Join操作对应的是两张表, 如果过滤条件是针对这两张表的,则将过滤条件下推到读取对应的表上,并且如果过滤条件的列与连接条件中的列相同时, 则将过滤条件同时下推到Join的左右两侧的表上。如:
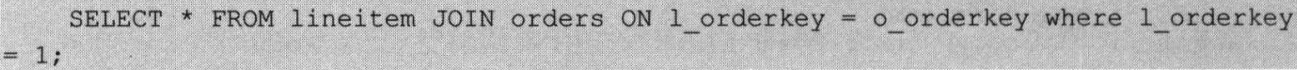
过滤条件l_order key=1会被下推到读取表line item之上, 过滤条件o_order key=1会被下推到读取表orders之上。
顺序

若有收获,就点个赞吧
0 人点赞
