一、快速入门
Phoenix作为应用层和HBASE之间的中间件,以下特性使它在大数据量的简单查询场景有着独有的优势。
- 二级索引支持(global index + local index)
- 编译SQL成为原生HBASE的可并行执行的scan
- 在数据层完成计算,server端的coprocessor执行聚合
- 下推where过滤条件到server端的scan filter上
- 利用统计信息优化、选择查询计划(5.x版本将支持CBO)
- skip scan功能提高扫描速度
一般可以使用以下三种方式访问Phoenix
- JDBC API
- 使用Python编写的命令行工具(sqlline, sqlline-thin和psql等)
- SQuirrel
1、命令行工具psql使用示例
1)创建一个建表的sql脚本文件us_population.sql:
CREATE TABLE IF NOT EXISTS us_population (state CHAR(2) NOT NULL,city VARCHAR NOT NULL,population BIGINTCONSTRAINT my_pk PRIMARY KEY (state, city));
2)创建csv格式的数据文件us_population.csv:
NY,New York,8143197CA,Los Angeles,3844829IL,Chicago,2842518TX,Houston,2016582PA,Philadelphia,1463281AZ,Phoenix,1461575TX,San Antonio,1256509CA,San Diego,1255540TX,Dallas,1213825CA,San Jose,912332
3)创建一个查询sql脚本文件us_population_queries.sql
SELECT state as "State",count(city) as "City Count",sum(population) as "Population Sum"FROM us_populationGROUP BY stateORDER BY sum(population) DESC;
4) 执行psql.py工具运行sql脚本
./psql.py <your_zookeeper_quorum> us_population.sql us_population.csv us_population_queries.sql
2、JDBC API使用示例
1)使用Maven构建工程时,需要添加以下依赖
<dependencies><dependency><groupId>com.aliyun.phoenix</groupId><artifactId>ali-phoenix-core</artifactId><version>${version}</version></dependency></dependencies>
2) 创建名为test.java的文件
import java.sql.Connection;import java.sql.DriverManager;import java.sql.ResultSet;import java.sql.SQLException;import java.sql.PreparedStatement;import java.sql.Statement;public class test {public static void main(String[] args) throws SQLException {Statement stmt = null;ResultSet rset = null;Connection con = DriverManager.getConnection("jdbc:phoenix:[zookeeper]");stmt = con.createStatement();stmt.executeUpdate("create table test (mykey integer not null primary key, mycolumn varchar)");stmt.executeUpdate("upsert into test values (1,'Hello')");stmt.executeUpdate("upsert into test values (2,'World!')");con.commit();PreparedStatement statement = con.prepareStatement("select * from test");rset = statement.executeQuery();while (rset.next()) {System.out.println(rset.getString("mycolumn"));}statement.close();con.close();}}
3)执行test.java
javac test.javajava -cp "../phoenix-[version]-client.jar:." test
二、数据类型
目前Phoenix支持24种简单数据类型和1个一维Array的复杂类型。以下是对支持数据类型的说明:
三、DML语法
云HBASE上Phoenix支持的DML
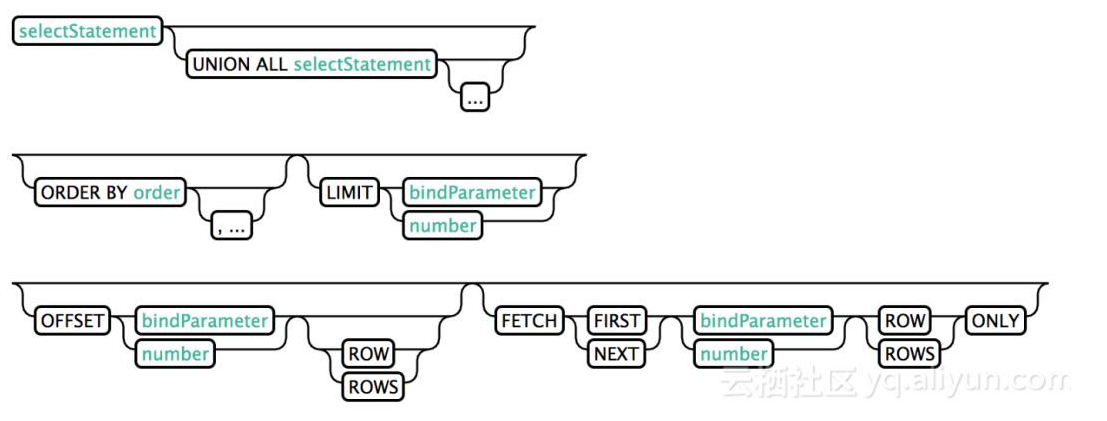
从一个或者多个表中查询数据。 LIMIT(或者FETCH FIRST) 在ORDER BY子句后将转换为top-N查询。 OFFSET子句指定返回查询结果前跳过的行数。
示例
SELECT * FROM TEST LIMIT 1000;SELECT * FROM TEST LIMIT 1000 OFFSET 100;SELECT full_name FROM SALES_PERSON WHERE ranking >= 5.0UNION ALL SELECT reviewer_name FROMCUSTOMER_REVIEW WHERE score >= 8.0
2. UPSERT VALUES
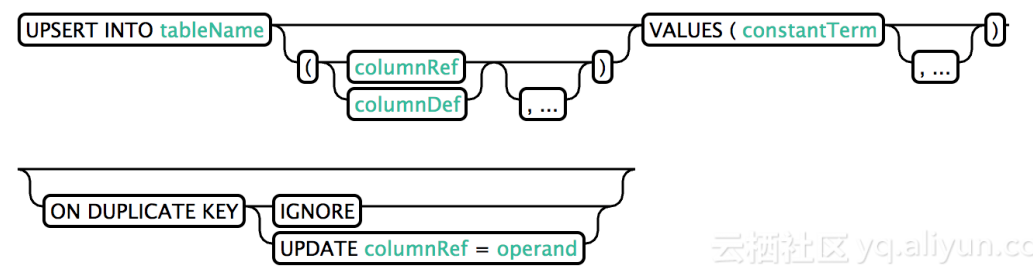
此处upsert语义有异于标准SQL中的Insert,当写入值不存在时,表示写入数据,否则更新数据。其中列的声明是可以省略的,当省略时,values指定值的顺序和目标表中schema声明列的顺序需要一致。
ON DUPLICATE KEY是4.9版本中的功能,表示upsert原子写入的语义,在写入性能上弱于非原子语义。相同的row在同一batch中按照执行顺序写入。
示例
UPSERT INTO TEST VALUES('foo','bar',3);UPSERT INTO TEST(NAME,ID) VALUES('foo',123);UPSERT INTO TEST(ID, COUNTER) VALUES(123, 0) ON DUPLICATE KEY UPDATE COUNTER = COUNTER + 1;UPSERT INTO TEST(ID, MY_COL) VALUES(123, 0) ON DUPLICATE KEY IGNORE;
3. UPSERT SELECT

从另外一张表中读取数据写入到目标表中,如果数据存在则更新,否则插入数据。插入目标表的值顺序和查询表指定查询字段一致。当auto commit被打开并且select子句没有聚合时,写入目标表这个过程是在server端完成的,否则查询的数据会先缓存在客户端再写入目标表中(phoenix.mutate.upsertBatchSize表示从客户端一次commit的行数,默认10000行)。
示例
UPSERT INTO test.targetTable(col1, col2) SELECT col3, col4 FROM test.sourceTable WHERE col5 < 100UPSERT INTO foo SELECT * FROM bar;
4. DELETE
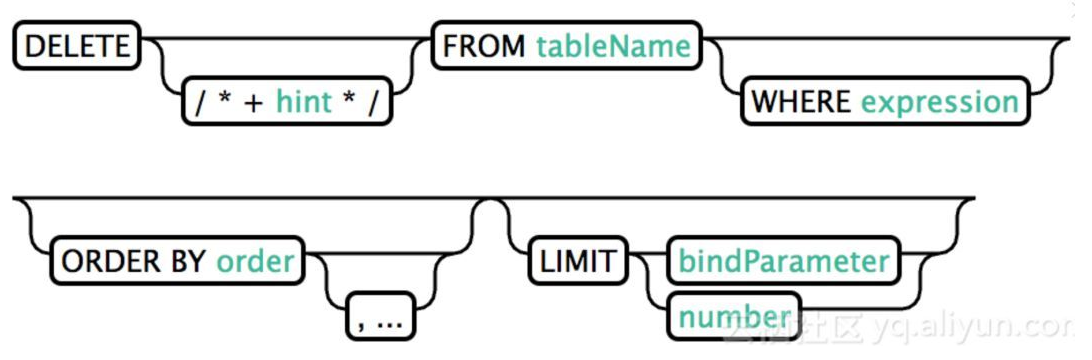
删除选定的列。如果auto commit打开,删除操作将在server端执行。
示例
DELETE FROM TABLENAME;DELETE FROM TABLENAME WHERE PK=123;DELETE FROM TABLENAME WHERE NAME LIKE '%';
四、加盐表
1. 什么是加盐?
在密码学中,加盐是指在散列之前将散列内容(例如:密码)的任意固定位置插入特定的字符串。这个在散列中加入字符串的方式称为“加盐”。其作用是让加盐后的散列结果和没有加盐的结果不相同,在不同的应用情景中,这个处理可以增加额外的安全性。而Phoenix中加盐是指对pk对应的byte数组插入特定的byte数据。
2. 加盐能解决什么问题?
加盐能解决HBASE读写热点问题,例如:单调递增rowkey数据的持续写入,使得负载集中在某一个RegionServer上引起的热点问题。
3. 怎么对表加盐?
在创建表的时候指定属性值:SALT_BUCKETS,其值表示所分buckets(region)数量, 范围是1~256。
CREATE TABLE mytable (my_key VARCHAR PRIMARY KEY, col VARCHAR) SALT_BUCKETS = 8;
4. 加盐的原理是什么?
加盐的过程就是在原来key的基础上增加一个byte作为前缀,计算公式如下:
new_row_key = ((byte) (hash(key) % BUCKETS_NUMBER) + original_key
以上公式中 BUCKETS_NUMBER 代表创建表时指定的 salt buckets 大小,hash 函数的实际计算方式如下:
public static int hash (byte a[], int offset, int length) {if (a == null)return 0;int result = 1;for (int i = offset; i < offset + length; i++) {result = 31 * result + a[i];}return result;}
5. 一个表“加多少盐合适”?
- 当可用block cache的大小小于表数据大小时,较优的slated bucket是和region server数量相同,这样可以得到更好的读写性能。
当表的数量很大时,基本上会忽略blcok cache的优化收益,大部分数据仍然需要走磁盘IO。比如对于10个region server集群的大表,可以考虑设计64~128个slat buckets。
6. 加盐时需要注意
创建加盐表时不能再指定split key。
- 加盐属性不等同于split key, 一个bucket可以对应多个region。
- 太大的slated buckets会减小range查询的灵活性,甚至降低查询性能。
五、二级索引
1、概要
目前HBASE只有基于字典序的主键索引,对于非主键过滤条件的查询都会变成扫全表操作,为了解决这个问题Phoenix引入了二级索引功能。然而此二级索引又有别于传统关系型数据库的二级索引,本文将详细描述了Phoenix中二级索引功能、用法和原理。2、二级索引
示例表如下(为了能够容易通过HBASE SHELL对照表内容,我们对属性值COLUMN_ENCODED_BYTES设置为0,不对column family进行编码):CREATE TABLE TEST (ID VARCHAR NOT NULL PRIMARY KEY,COL1 VARCHAR,COL2 VARCHAR) COLUMN_ENCODED_BYTES=0;upsert into TEST values('1', '2', '3');
1)全局索引
全局索引更多的应用在读较多的场景。它对应一张独立的HBASE表。对于全局索引,在查询中检索的列如果不在索引表中,默认的索引表将不会被使用,除非使用hint。
创建全局索引:
CREATE INDEX IDX_COL1 ON TEST(COL1)
通过HBASE SHELL观察生成的索引表IDX_COL1。我们发现全局索引表的RowKey存储了索引列的值和原表RowKey的值,这样编码更有利于提高查询的性能。
hbase(main):001:0> scan 'IDX_COL1'ROW COLUMN+CELL2\x001 column=0:_0, timestamp=1520935113031, value=x1 row(s) in 0.1650 seconds
实际上全局索引的RowKey将会按照如下格式进行编码。

- SALT BYTE: 全局索引表和普通phoenix表一样,可以在创建索引时指定
SALT_BUCKETS或者split key。此byte正是存储着salt。 - TENANT_ID: 当前数据对应的多租户ID。
- INDEX VALUE: 索引数据。
- PK VALUE: 原表的RowKey。
2)本地索引
因为本地索引和原数据是存储在同一个表中的,所以更适合写多的场景。对于本地索引,查询中无论是否指定hint或者是查询的列是否都在索引表中,都会使用索引表。
创建本地索引:
create local index LOCAL_IDX_COL1 ON TEST(COL1);
通过HBASE SHELL观察表’TEST’, 我们可以看到表中多了一行column为L#0:_0的索引数据。
hbase(main):001:0> scan 'TEST'ROW COLUMN+CELL\x00\x002\x001 column=L#0:_0, timestamp=1520935997600, value=_01 column=0:COL1, timestamp=1520935997600, value=21 column=0:COL2, timestamp=1520935997600, value=31 column=0:_0, timestamp=1520935997600, value=x2 row(s) in 0.1680 seconds
本地索引的RowKey将会按照如下格式进行编码:
- REGION START KEY : 当前row所在region的start key。加上这个start key的好处是,可以让索引数据和原数据尽量在同一个region, 减小IO,提升性能。
- INDEX ID : 每个ID对应不同的索引表。
- TENANT ID :当前数据对应的多租户ID。
- INDEX VALUE: 索引数据。
- PK VALUE: 原表的RowKey。
3)覆盖索引
覆盖索引的特点是把原数据存储在索引数据表中,这样在查询到索引数据时就不需要再次返回到原表查询,可以直接拿到查询结果。
创建覆盖索引:
通过HBASE SHELL 查询表create index IDX_COL1_COVER_COL2 on TEST(COL1) include(COL2);
IDX_COL1_COVER_COL2, 我们发现include的列的值被写入到了value中。hbase(main):003:0> scan 'IDX_COL1_COVER_COL2'ROW COLUMN+CELL2\x001 column=0:0:COL2, timestamp=1520943893821, value=32\x001 column=0:_0, timestamp=1520943893821, value=x1 row(s) in 0.0180 seconds
对于类似select col2 from TEST where COL1='2'的查询,查询一次索引表就能获得结果。其查询计划如下:
+———————————————————————————————————————————+————————-+————————+—-+
| PLAN | EST_BYTES_READ | EST_ROWS_READ | E |
+———————————————————————————————————————————+————————-+————————+—-+
| CLIENT 1-CHUNK PARALLEL 1-WAY ROUND ROBIN RANGE SCAN OVER IDX_COL1_COVER_COL2 [‘2’] | null | null | n |
+———————————————————————————————————————————+————————-+————————+—-+
4)函数索引
函数索引的特点是能根据表达式创建索引,适用于对查询表,过滤条件是表达式的表创建索引。例如:
//创建函数索引CREATE INDEX CONCATE_IDX ON TEST (UPPER(COL1||COL2))//查询函数索引SELECT * FROM TEST WHERE UPPER(COL1||COL2)='23'
3、什么是Phoenix的二级索引?
Phoenix的二级索引我们基本上已经介绍过了,我们回过头来继续看Phoenix二级索引的官方定义:Secondary indexes are an orthogonal way to access data from its primary access path。通过以下例子我们再理解下这个定义。
1. 对表TEST的COL1创建全局索引CREATE INDEX IDX_COL1 ON TEST(COL1);1. 查询所有字段。select * from TEST where COL1='2';
以上查询的查询计划如下:
+————————————————————————————————+————————-+————————+———————+
| PLAN | EST_BYTES_READ | EST_ROWS_READ | EST_INFO_TS |
+————————————————————————————————+————————-+————————+———————+
| CLIENT 1-CHUNK PARALLEL 1-WAY ROUND ROBIN FULL SCAN OVER TEST | null | null | null |
| SERVER FILTER BY COL1 = ‘2’ | null | null | null |
+————————————————————————————————+————————-+————————+———————+
- 查询id字段:
select id from TEST where COL1=’2’;
查询计划如下
+—————————————————————————————————————-+————————-+————————+———————+
| PLAN | EST_BYTES_READ | EST_ROWS_READ | EST_INFO_TS |
+—————————————————————————————————————-+————————-+————————+———————+
| CLIENT 1-CHUNK PARALLEL 1-WAY ROUND ROBIN RANGE SCAN OVER IDX_COL1 [‘2’] | null | null | null |
| SERVER FILTER BY FIRST KEY ONLY | null | null | null |
+—————————————————————————————————————-+————————-+————————+———————+
两个查询都没有通过hint强制指定索引表,查询计划显示,查询所有字段时发生了需要极力避免的扫全表操作(一般数据量在几十万级别的扫全表很容易造成集群不稳定),而查询id时利用索引表走了点查。从现象来看,当查询中出现的字段都在索引表中时(可以是索引字段或者数据表主键,也可以是覆盖索引字段),会自动走索引表,否则查询会退化为全表扫描。
在我们实际应用中一个数据表会有多个索引表,为了能让我们的查询使用合理的索引表,目前都需要通过Hint去指定。
4、索引Building
Phoenix的二级索引创建有同步和异步两种方式。
- 在执行
CREATE INDEX IDX_COL1 ON TEST(COL1)时会进行索引数据的同步。此方法适用于数据量较小的情况。 - 异步build索引需要借助MR,创建异步索引语法和同步索引相差一个关键字:
ASYNC。//创建异步索引CREATE INDEX ASYNC_IDX ON DB.TEST (COL1) ASYNC//build 索引数据${HBASE_HOME}/bin/hbase org.apache.phoenix.mapreduce.index.IndexTool --schema DB --data-table TEST --index-table ASYNC_IDX --output-path ASYNC_IDX_HFILES
5、索引问题汇总
1)创建同步索引超时怎么办?
在客户端配置文件hbase-site.xml中,把超时参数设置大一些,足够build索引数据的时间。
<property><name>hbase.rpc.timeout</name><value>60000000</value></property><property><name>hbase.client.scanner.timeout.period</name><value>60000000</value></property><property><name>phoenix.query.timeoutMs</name><value>60000000</value></property>
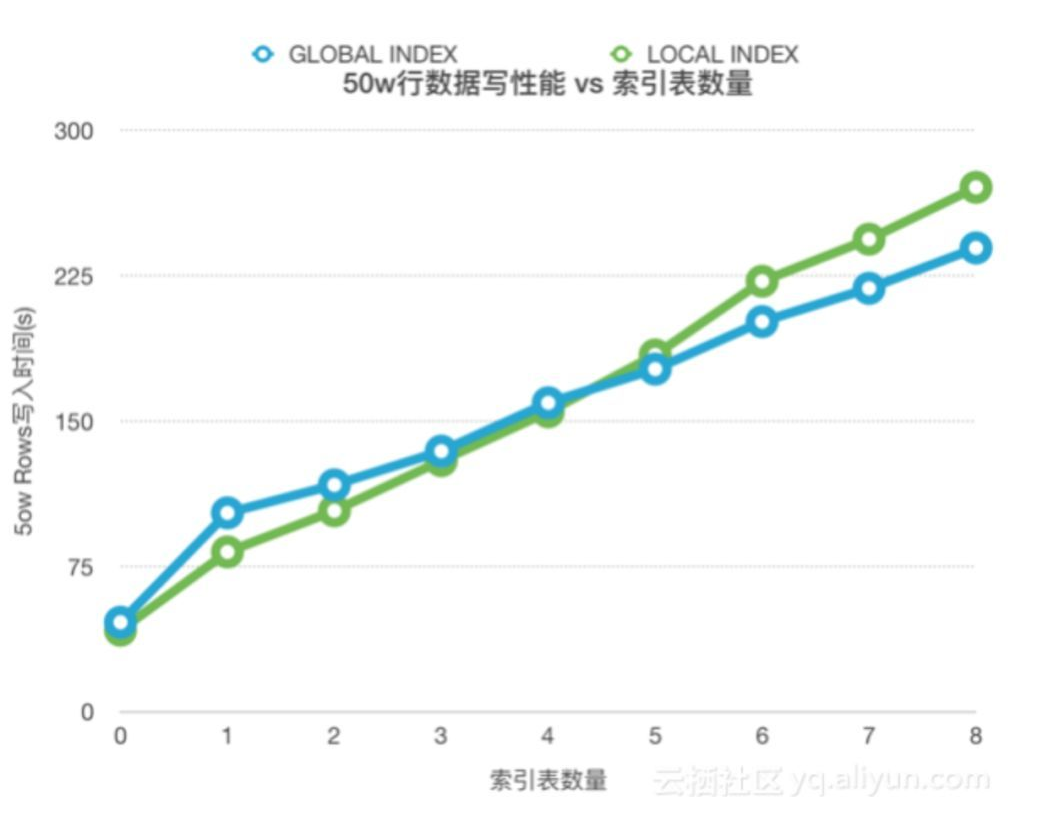
2)索引表最多可以创建多少个?
3)为什么索引表多了,单条写入会变慢?
六、MR在Ali-Phoenix上的使用
1、MR在Phoenix上的用途
1)利用MR对Phoenix表(可带有二级索引表)进行Bulkload入库, 其原理是直接生成主表(二级索引表)的HFILE写入HDFS。相对于走API的数据导入方式,不仅速度更快,而且对HBASE集群的负载也会小很多。目前云HBASE上的Phoenix支持以下数据源的Bulkload工具:
CsvBulkLoadToolJsonBulkLoadToolRegexBulkLoadToolODPSBulkLoadTool
2)利用MR Building二级索引。当主表数据量较大时,可以通过创建异步索引,使用MR快速同步索引数据。
2、如何访问云HBASE的HDFS?
由于云HBASE上没有MR,需要借助外部的计算引擎(自建的HADOOP集群或者EMR),而使用外部的计算引擎的首先面临的问题是,如何跨集群访问HDFS。 1.由于云HBASE的HDFS端口默认是不开的,需要联系工作人员开通。 2.端口开通以后,要想顺利的访问HDFS是HA配置的云HBASE集群,需要向工作人员获取云HBASE的主备(emr-header-1,emr-header-2)namenode host/IP。参考如下配置模板,设置hadoop客户端配置文件: hdfs-site.xml
<configuration><property><name>dfs.nameservices</name><value>emr-cluster</value></property><property><name>dfs.client.failover.proxy.provider.emr-cluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><name>dfs.ha.automatic-failover.enabled.emr-cluster</name><value>true</value></property><property><name>dfs.ha.namenodes.emr-cluster</name><value>nn1,nn2</value></property><property><name>dfs.namenode.rpc-address.emr-cluster.nn1</name><value>{emr-header-1-host}:8020</value></property><property><name>dfs.namenode.rpc-address.emr-cluster.nn2</name><value>{emr-header-2-host}:8020</value></property></configuration>
3.验证访问云HBASE HDFS 在emr或自建集群上访问云HBase集群
hadoop dfs -ls hdfs://emr-cluster/
3、BULKLOAD PHOENIX表
以EMR访问云HBASE为例。EMR集群需要把云HBASE HDFS的emr-cluster 相关配置和当前EMR的HDFS配置合在一起形成新的配置文件,单独存放在一个目录(${conf-dir})下。 通过yarn/hadoop命令的—config参数指定新的配置目录,使这些配置文件放在CLASSPATH最前面覆盖掉当前EMR集群hadoop_conf_dir下的配置,以便bulkload程序能识别到云HBASE HA的HDFS URL。当在emr或自建集群上能够访问自己的HDFS(hadoop --config <confdir> dfs -ls /), 也能够访问云HBase的HDFS(hadoop --config <confdir> dfs -ls hdfs://emr-cluster/)说明配置成功了。
执行如下BULKLOAD命令
yarn --config ${CONF_DIR} \jar ${PHOENIX_HOME}/phoenix-${version}-client.jar org.apache.phoenix.mapreduce.CsvBulkLoadTool \--table "TABLENAME" \--input "hdfs://emr-header-1.cluster-55090:9000/tmp/test_data" \--zookeeper "zk1,zk2,zk3" \--output "hdfs://emr-cluster/tmp/tmp_data"
注意: —output 配置的是云HBASE的临时文件,这样直接把生成的HFILE存储在云HBASE的HDFS上,后续的只有简单的move操作。否则,如果生成在EMR集群还需要走网络发送到云HBASE HDFS上。
回到顶部
七、如何使用自增ID
在传统关系型数据库中设计主键时,自增ID经常被使用。不仅能够保证主键的唯一,同时也能简化业务层实现。Phoenix怎么使用自增ID,是我们这篇文章的重点。
1、语法说明
1)创建自增序列
CREATE SEQUENCE [IF NOT EXISTS] SCHEMA.SEQUENCE_NAME[START WITH number][INCREMENT BY number][MINVALUE number][MAXVALUE number][CYCLE][CACHE number]• start用于指定第一个值。如果不指定默认为1.• increment指定每次调用next value for后自增大小。如果不指定默认为1。• minvalue和maxvalue一般与cycle连用, 让自增数据形成一个环,从最小值到最大值,再从最大值到最小值。• cache默认为100, 表示server端生成100个自增序列缓存在客户端,可以减少rpc次数。此值也可以通过phoenix.sequence.cacheSize来配置。
示例
CREATE SEQUENCE my_sequence;-- 创建一个自增序列,初始值为1,自增间隔为1,将有100个自增值缓存在客户端。CREATE SEQUENCE my_sequence START WITH -1000CREATE SEQUENCE my_sequence INCREMENT BY 10CREATE SEQUENCE my_cycling_sequence MINVALUE 1 MAXVALUE 100 CYCLE;CREATE SEQUENCE my_schema.my_sequence START 0 CACHE 10
2)删除自增序列
DROP SEQUENCE [IF EXISTS] SCHEMA.SEQUENCE_NAME示例DROP SEQUENCE my_sequenceDROP SEQUENCE IF EXISTS my_schema.my_sequence
2、案例
1)需求
对现有的书籍进行编号并存储,要求编号是惟一的。存储书籍信息的建表语句如下:
create table books(id integer not null primary key,name varchar,author varchar)SALT_BUCKETS = 8;
由于自增ID作为rowkey, 容易造成集群热点问题,所以在创建表时最好通过加盐的方式解决这个问题
2)通过自增ID,实现唯一编码,并简化实现。
创建自增序列,初始值为10000,自增间隔为1,缓存大小为1000.
CREATE SEQUENCE book_sequence START WITH 10000 INCREMENT BY 1 CACHE 1000;
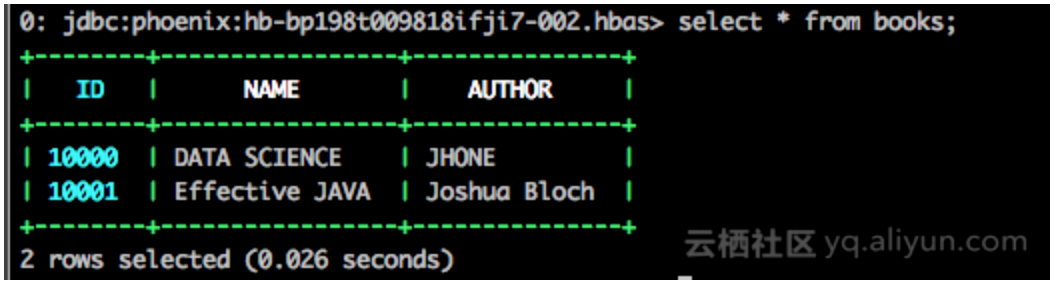
通过自增序列,写入数据信息。
UPSERT INTO books(id, name, author) VALUES( NEXT VALUE FOR book_sequence,'DATA SCIENCE', 'JHONE'); UPSERT INTO books(id, name, author) VALUES( NEXT VALUE FOR book_sequence,'Effective JAVA','Joshua Bloch');
查看结果
八、动态列
1、概要
动态列是指在查询中新增字段,操作创建表时未指定的列。传统关系型数据要实现动态列目前常用的方法有:设计表结构时预留新增字段位置、设计更通用的字段、列映射为行和利用json/xml存储字段扩展字段信息等,这些方法多少都存在一些缺陷,动态列的实现只能依赖逻辑层的设计实现。由于Phoenix是HBase上的SQL层,借助HBase特性实现的动态列,避免了传统关系型数据库动态列实现存在的问题。
2、动态列使用
示例表(用于语法说明)
CREATE TABLE EventLog (eventId BIGINT NOT NULL,eventTime TIME NOT NULL,eventType CHAR(3)CONSTRAINT pk PRIMARY KEY (eventId, eventTime)) COLUMN_ENCODED_BYTES=0
1) Upsert
在插入数据时指定新增列字段名和类型,并在values对应的位置设置相应的值。语法如下:
upsert into <tableName>(exists_col1, exists_col2, ... (new_col1 time, new_col2 integer, ...))VALUES(v1, v2, ... (v1, v2, ...))
动态列写入示例:
UPSERT INTO EventLog (eventId, eventTime, eventType, lastGCTime TIME, usedMemory BIGINT, maxMemory BIGINT) VALUES(1, CURRENT_TIME(), 'abc', CURRENT_TIME(), 512, 1024);
我们来查询看一下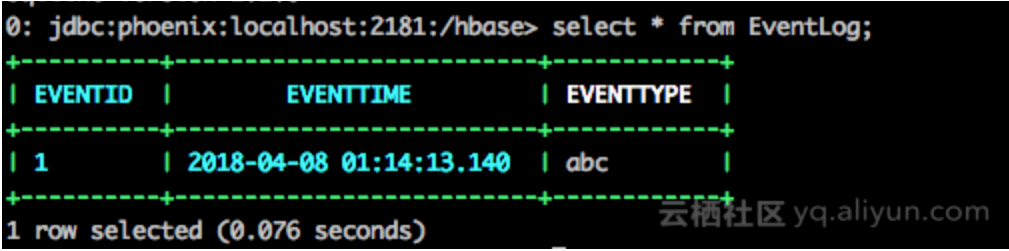
查询发现并没新增列的数据,也就是通过动态列插入值时并没有对表的schema直接改变。HBase表中发生了怎么样的变化呢?
实际上HBase表中已经新增列以及数据。那通过动态列添加的数据怎么查询呢?
2)Select
动态列查询语法
select [*|table.*|[table.]colum_name_1[AS alias1][,[table.]colum_name_2[AS alias2] …], <dy_colum_name_1>]FROM tableName (<dy_colum_name_1, type> [,<dy_column_name_2, type> ...])[where clause][group by clause][having clause][order by clause]
动态列查询示例
SELECT eventId, eventTime, lastGCTime, usedMemory, maxMemory FROM EventLog(lastGCTime TIME, usedMemory BIGINT, maxMemory BIGINT) where eventId=1

3、总结
Phoneix的动态列功能是非SQL标准语法,它给我们带来更多的灵活性,不再为静态schema的字段扩展问题而困扰。然而我们在实际应用中,应该根据自己的业务需求决定是否真的使用动态列,因为动态列的滥用会大幅度的增加我们的维护成本。
九、分页查询
1、概述
所谓分页查询就是从符合条件的起始记录,往后遍历“页大小”的行。数据库的分页是在server端完成的,避免客户端一次性查询到大量的数据,让查询数据数据分段展示在客户端。对于Phoenix的分页查询,怎么使用?性能怎么样?需要注意什么?将会在文章中通过示例和数据说明。
2、分页查询
1)语法说明
[ LIMIT { count } ][ OFFSET start [ ROW | ROWS ] ][ FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } ONLY ]
Limit或者Fetch在order by子句后转化为为top-N的查询,其中offset子句表示从开始的位置跳过多少行开始扫描。
对于以下的offsset使用示例, 我们可发现当offset的值为0时,查询结果从第一行记录开始扫描limit指定的行数,当offset值为1时查询结果从第二行记录开始开始扫描limit指定的行数…
0: jdbc:phoenix:localhost> select SS_CUSTOMER_SK from STORE_SALES where SS_ITEM_SK < 3600order by SS_ITEM_SK limit 6;+-----------------+| SS_CUSTOMER_SK |+-----------------+| 109734 || null || 168740 || 344372 || 249078 || 241017 |+-----------------+6 rows selected (0.025 seconds)
0: jdbc:phoenix:localhost> select SS_CUSTOMER_SK from STORE_SALES where SS_ITEM_SK < 3600 order by SS_ITEM_SK limit 3 offset 0;+-----------------+| SS_CUSTOMER_SK |+-----------------+| 109734 || null || 168740 |+-----------------+3 rows selected (0.034 seconds)
0: jdbc:phoenix:localhost> select SS_CUSTOMER_SK from STORE_SALES where SS_ITEM_SK < 3600 order by SS_ITEM_SKlimit 3 offset 1;+-----------------+| SS_CUSTOMER_SK |+-----------------+| null || 168740 || 344372 |+-----------------+3 rows selected (0.026 seconds)
0: jdbc:phoenix:localhost> select SS_CUSTOMER_SK from STORE_SALES where SS_ITEM_SK < 3600 order by SS_ITEM_SKlimit 3 offset 2;+-----------------+| SS_CUSTOMER_SK |+-----------------+| 168740 || 344372 || 249078 |+-----------------+3 rows selected (0.017 seconds)
0: jdbc:phoenix:localhost> select SS_CUSTOMER_SK from STORE_SALES where SS_ITEM_SK < 3600 order by SS_ITEM_SKlimit 3 offset 3;+-----------------+| SS_CUSTOMER_SK |+-----------------+| 344372 || 249078 || 241017 |+-----------------+3 rows selected (0.024 seconds)
2)语法示例
SELECT * FROM TEST LIMIT 1000;SELECT * FROM TEST LIMIT 1000 OFFSET 100;SELECT * FROM TEST FETCH FIRST 100 ROWS ONLY;
3、性能测评
我们对如下SQL的limit子句进行性能得到以下结论。
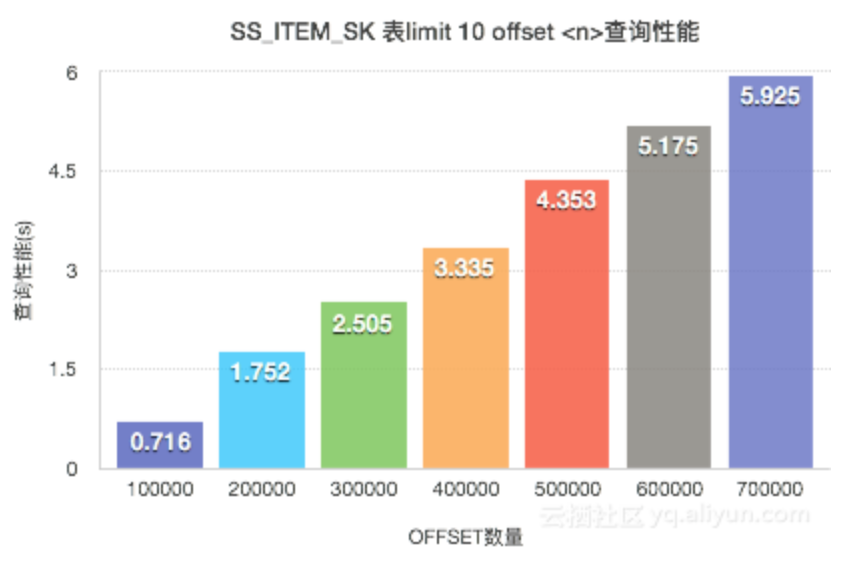
select SS_CUSTOMER_SK from STORE_SALESwhere SS_ITEM_SK < 3600order by SS_ITEM_SKlimit <m> offset <n>
结论1:当limit的值一定时,随着offset N的值越大,查询性基本会线性下降。
结论2:当offset的值一定时,随着Limit的值越大,查询性能逐步下降。当limit的值相差一个数量级时,查询性能也会有几十倍的差距。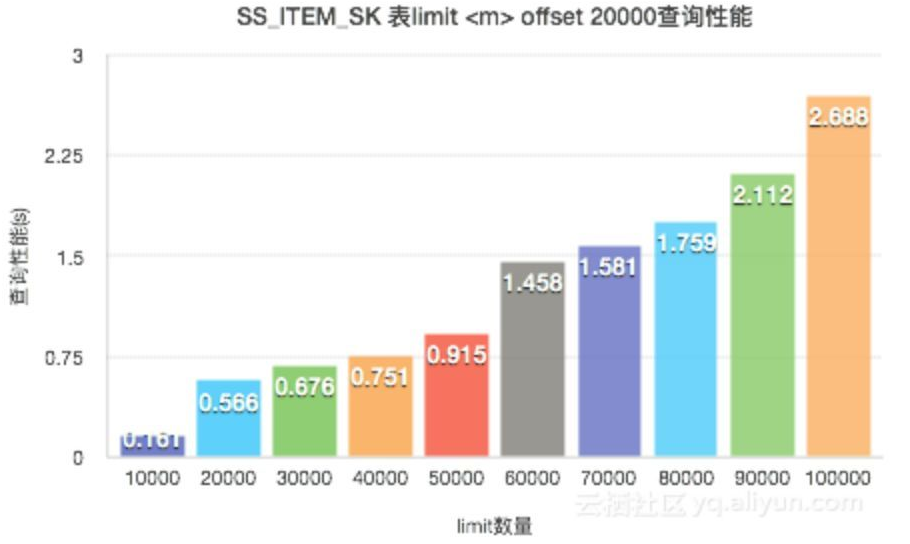
4、最后
大多数场景中分页查询都是和order by子句一起使用的, 在这里需要注意的是,order by的排序字段最好是主键,否则查询性能会比较差。(这部分最好是在做业务层设计时就能考虑到)分页查询需要根据用户的实际需求来设计,在现实产品中,一般很少有上万行每页的需求,页数太大是不合理的,同时页数太多也是不合理的。度量是否合理,仍需要根据实际需求出发。
十、全局索引设计实践
1、概述
全局索引是Phoenix的重要特性,合理的使用二级索引能降低查询延时,让集群资源得以充分利用。本文将讲述如何高效的设计和使用索引。
2、全局索引说明
全局索引的根本是通过单独的HBase表来存储数据表的索引数据。我们通过如下示例看索引数据和主表数据的关系。
— 创建数据表
CREATE TABLE DATA_TABLE(A VARCHAR PRIMARY KEY,B VARCHAR,C INTEGER,D INTEGER);
— 创建索引
CREATE INDEX B_IDX ON DATA_TABLE(B)INCLUDE(C);
— 插入数据
UPSERT INTO DATA_TABLE VALUES('A','B',1,2);
当写入数据到主表时,索引数据也会被同步到索引表中。索引表中的主键将会是索引列和数据表主键的组合值,include的列被存储在索引表的普通列中,其目的是让查询更加高效,只需要查询一次索引表就能够拿到数据,而不用去回查主表。其过程如下图: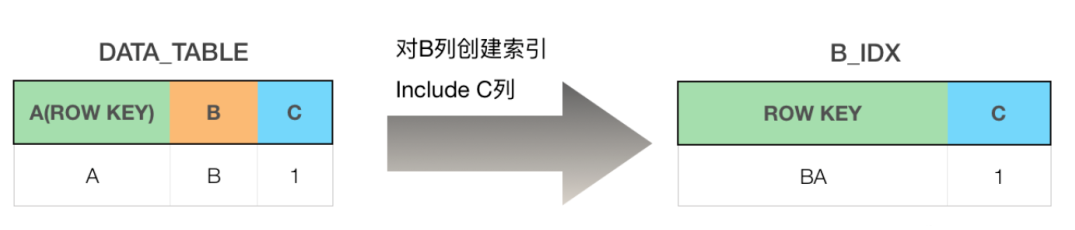
Phoenix表就是HBase表,而HBase Rowkey都是通过二进制数据的字典序排列存储,也就意味着Row key前缀匹配度越高就越容易排在一起。
3、全局索引设计
我们继续使用DATA_TABLE作为示例表,创建如下组合索引。之前我们已经提到索引表中的Row key是字典序存储的,什么样的查询适合这样的索引结构呢?
CREATE INDEX B_C_D_IDX ON DATA_TABLE(B,C,D); 所有字段条件以=操作符为例: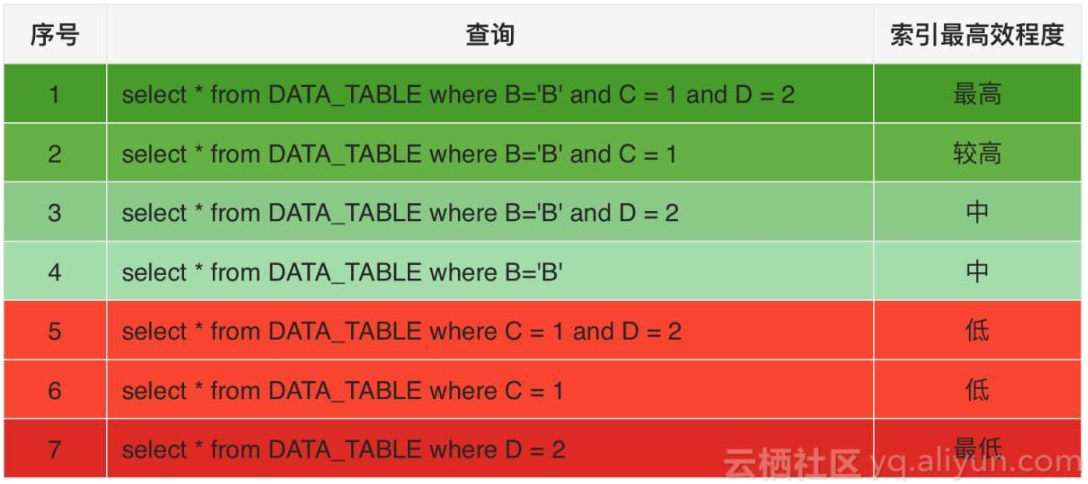
注:上表查询中and条件不一定要和索引组合字段顺序一致,可以任意组合。
在实际使用中我们也只推荐使用1~4,遵循前缀匹配原则,避免触发扫全表。5~7条件就要扫描全表数据才能过滤出来符合这些条件的数据,所以是极力不推荐的。
4、其它
- 对于order by字段或者group by字段仍然能够使用二级索引字段来加速查询。
- 尽量通过合理的设计数据表的主键规避建更多的索引表,因为索引表越多写放大越严重。
- 使用了ROW_TIMESTAMP特性后不能使用全局索引
- 对索引表适当的使用加盐特性能提升查询写入性能,避免热点。
十一、查询计划详解
1、概要
在数据库中,执行计划就是表示一条SQL将要执行的步骤,这些步骤按照不同的数据库运算符号(算子)组成,具体的组成和执行方式由数据库中的查询优化器来决定。换而言之,执行计划决定了SQL的执行效率。在数据库的使用中了解其查询计划的构成,是进行查询性能调优的必要条件。本文将详细介绍Phoenix的查询计划语法、组成结构,以及一些注意事项。
2、查询计划
1)基本说明
在phoenix中,查询计划能告诉我们如下的信息:
- 将要扫描的CHUNK数量
- 客户端并发线程数量
- 执行模式(并行或串行)
- 查询过滤字段或者扫描范围
- 将会查询的表名
- 估算扫描数据bytes大小(依赖stats信息)
- 估算扫描数据量大小(依赖stats信息)
- 估算数量bytes大小和数据量时间
- 操作符被执行在客户端或者服务端
- 涉及的查询operations(sort、filter, scan, merge, join, limit等)
2)语法
explain [select... | upsert ... select | delete...]explain语法示例如下:explain SELECT host FROM PTSDB WHERE host IN ('a','b');explain UPSERT INTO t1 SELECT id FROM t2 ORDER BY K1, V1;
3)如何选择最优查询计划
检查查询计划是否最优,核心有以下几点可以作为参考:
- 尽量避免出现FULL SCAN,尤其对于不走索引表的单表查询,不应该出现FULL SCAN
- 执行模式尽可能使用并行(某些情况一定是串行的执行模式)
- 尽可能将对应表的过滤条件或计算下推到server端
- 尽可能使用覆盖索引,生成不需要回查数据表的查询计划
3、查询计划详解
1. 操作符说明
- UNION ALL: 表示union all查询,操作符后面接查询计划中涉及查询的数量
- AGGREGATE INTO SINGLE ROW: 没有groupby语句情况下,聚合查询结果到一行中。例如 count(*)
- AGGREGATE INTO ORDERED DISTINCT ROWS:带有group by的分组查询
- FILTER BY expression: 过滤出符合表达式条件的数据
- INNER-JOIN: 多表Join
- MERGE SORT: 进行merge sort排序,大多是客户端对多线程查询结果进行排序
- RANGE SCAN: 对主键进行范围扫描,通常有指定start key和stop key
- ROUND ROBIN: 对查询没有排序要求,并发的在客户端发起扫描请求。
- SKIP SCAN: Phoenix实现的一种扫描方式,通常能比Range scan获得更好的性能。
- FULL SCAN: 全表扫描
- LIMIT: 对查询结果取TOP N
- CLIENT: 在客户端执行相关操作
- X-CHUNK: 根据统计信息可以把一个region分成多个CHUNK, X在查询计划中表示将要扫描的CHUNK数量,此处是多线程并发扫描的,并发的数量是由客户端线程池的大小来决定的
- PARALLEL X-WAY:描述了有X个并发对scan做merge sort之类的客户端操作
- SERIAL: 单线程串行执行
- SERVER: 在SERVER端(RS)执行相关操作
2. 查询计划示例说明
分组聚合查询。查询计划中有5385个并发,并行对表做范围扫描,在server端以组合rowkey的第二列k2为过滤条件过滤,并以k2列做聚合。
explain select count(k2) from OFFSET_TEST where k2 = '3343' group by k2;CLIENT 5385-CHUNK 2330168 ROWS 314572800 BYTES PARALLEL 5385-WAY RANGE SCAN OVER OFFSET_TEST [0] - [63]SERVER FILTER BY FIRST KEY ONLY AND K2 = '3343'SERVER AGGREGATE INTO DISTINCT ROWS BY [K2]CLIENT MERGE SORT
无排序查询生成ROUND ROBIN查询计划。查询计划中有5385个并发,并行对表做ROUND ROBIN的范围扫描,在server端以组合rowkey的第二列k2为过滤条件过滤。
explain select * from OFFSET_TEST where k2 = '3343';CLIENT 5385-CHUNK 2330168 ROWS 314572800 BYTES PARALLEL 5385-WAY ROUND ROBIN RANGE SCAN OVER OFFSET_TEST [0] - [63]SERVER FILTER BY K2 = '3343'
有排序查询。查询计划中有5385个并发,并行对表做范围扫描,在server端以组合rowkey的第二列k2为过滤条件过滤并排序,最后在客户端进行merge sort查询结果。
explain select * from OFFSET_TEST where k2 = '3343' order by k2;CLIENT 5385-CHUNK 2330168 ROWS 314572800 BYTES PARALLEL 5385-WAY RANGE SCAN OVER OFFSET_TEST [0] - [63]SERVER FILTER BY K2 = '3343'SERVER SORTED BY [K2]CLIENT MERGE SORT
4、API访问查询计划信息
String explainSql = "EXPLAIN SELECT * FROM T";Long estimatedBytes = null;Long estimatedRows = null;Long estimateInfoTs = null;try (Statement statement = conn.createStatement(explainSql)) {int paramIdx = 1;ResultSet rs = statement.executeQuery(explainSql);//打印查询计划System.out.println(QueryUtil.getExplainPlan(rs));//获取相关估算值rs.next();estimatedBytes =(Long) rs.getObject(PhoenixRuntime.EXPLAIN_PLAN_ESTIMATED_BYTES_READ_COLUMN);estimatedRows =(Long) rs.getObject(PhoenixRuntime.EXPLAIN_PLAN_ESTIMATED_ROWS_READ_COLUMN);estimateInfoTs =(Long) rs.getObject(PhoenixRuntime.EXPLAIN_PLAN_ESTIMATE_INFO_TS_COLUMN);}
5、注意事项
- 当有两个以上索引表时尽量使用hint去指定查询必须要使用的索引表,这样可以确保即使以后再加了索引不会影响到现在使用的查询计划
- 能通过数据表组合主键覆盖的查询条件,尽量避免创建索引表。索引表表越多,写放大越严重,维护成本也会随之增加
- 在查询计划中Scan速度,SKIP SCAN > RANGE SCAN > FULL SCAN
- 不是所有的查询operations都能下推到server端
- 查询SERVER FILTER一个普通列,一般会在server端发生全表扫描操作,也需要谨慎检查
- 组合主键或者组合索引的非前缀列,作为过滤条件列进行查询时,一般会生成SCAN OVER的查询计划,但实际上这种查询也很可能需要全表扫描,所以也需要根据实际情况检查确认
十二、数据迁移
1. 概要
数据迁移工具是否丰富,也在一定程度上决定了数据库的流行程度和它的生态圈。了解其相关工具,能让我们的数据迁移工作更加高效。本文主要介绍 Phoenix 的数据导入导出工具,希望给准备在 Phoenix 上做数据迁移的同学一些帮助。
2. 数据导入导出说明
由于在源端进行数据迁移,导入到 Phoenix 的过程中会产生新的数据修改或写入,这使得不停业务的实时迁移变的不简单。现在开源的数据迁移工具都需要停止数据源端的业务来完成数据迁移。
对于准备迁移上阿里云 HBase 的同学这个都不是问题,我们提供不停业务的实时迁移(HFile拷贝+WAL同步解析入库)支持。
从导入方式上可分为两种: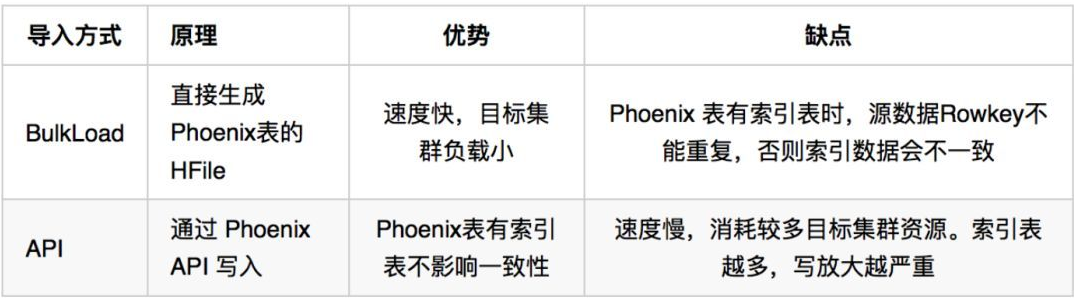
3. BulkLoad 导入数据
通过 BulkLoad 方式导入数据可以直接导入 Phoenix 表或者导入 HBase 表,然后通过创建 Phoenix 映射(此方法暂不做介绍)。直接导入 Phoenix 表的 Bulkload 工具,支持的数据源如下:
- Csv数据入库:CsvBulkloadTool
- Json数据入库:JsonBulkloadTool
- 正则匹配文本入库:RegexBulkloadTool
- ODPS表: ODPSBulkLoadTool(仅云HBase上支持)
其中 Csv/Json/Regex Bulkload,在开源 Phoenix 版本中已经提供了相应的工具类,具体使用参数可以通过--help来查看,使用示例如下:
HADOOP_CLASSPATH=$(hbase mapredcp):/path/to/hbase/conf \hadoop jar phoenix-<version>-client.jar \org.apache.phoenix.mapreduce.CsvBulkLoadTool \--table EXAMPLE \--input /data/example.csvHADOOP_CLASSPATH=/path/to/hbase-protocol.jar:/path/to/hbase/conf \hadoop jar phoenix-<version>-client.jar \org.apache.phoenix.mapreduce.CsvBulkLoadTool \--table EXAMPLE \--input /data/example.csvhadoop jar phoenix-<version>-client.jar \org.apache.phoenix.mapreduce.JsonBulkLoadTool \--table EXAMPLE \--input /data/example.json
4. API 数据导入导出
DataX是阿里内被广泛使用的离线数据同步工具/平台,支持各种常见异构数据源之间高效的数据同步功能,其原理是通过 Datax 多线程同时读取多个数据分片,使用 API 写入到目标数据源中。 现在支持 Phoenix 4.12 版本以上的数据导出导出插件,能满足日常从关系型数据库导入到 Phoenix,ODPS 导入到 Phoenix, Phoenix导出CSV文本等需求。
5. 总结
对于主键不重复的全量源数据,我们都推荐借助 MR 利用 Bulkload 方式导入 Phonenix(云 HBase 本身不提供 MR 能力,需要借助外部能访问源集群和目标集群HDFS的Hadoop)。 对于每天增量数据的同步可以使用 Datax(导入数据到 云 HBase 需要提供一个能访问源集群和目标集群的 ECS 运行 Datax)。
想要提高 Bulkload 的数据入库速度,不仅需要增加目标 Phoenix 表的 region 数量(新建表需要指定预分区数或者加盐),还需要提升 MR 运行环境的集群配置(scale out/ scale up)。DataX 提升入库的方式主要是调整配置的线程数、batch数量,同时目标表的region数量也不能太少。

若有收获,就点个赞吧
0 人点赞
