1.ETL
由于Presto可以方便地支持多种数据源(即使不支持也可以通过实现Presto的SPI接口方便地实现对新数据源的支持)并且可以支持多种数据源的混合计算,因此我们可以使用简单的SQL语句将一个数据源中的数据导入到另一个数据源中。目前官方Presto版本仅支持将MySQL或者PostgreSQL两种RDBMS, 你可以通过Create Table…As Select…语句将MySQL或者Postgre中的数据导入到Hive中, 而且不支持将Hive中的数据反向导入到RDBMS中。不过我们已经通过二次开发实现了将Hive中的数据导入到MySQL中。在某公司现实使用场景中, 通过与azkaban调度系统配合使用, 可以实现定时或者以固定频率调度特定的Presto执行脚本(形如Insert Overwrite Table Partition(…) As Select…的SQL语句, 目前官方Presto版本尚未提供该功能, 但是若使用JD-Presto则可以提供该功能)来完成相关的ETL工作。Presto的这种使用方式提供了一种全新的ETL方案, 比传统的ETL方案更方便、快捷。如图16-1所示是某公司这种应用场景的实际系统架构。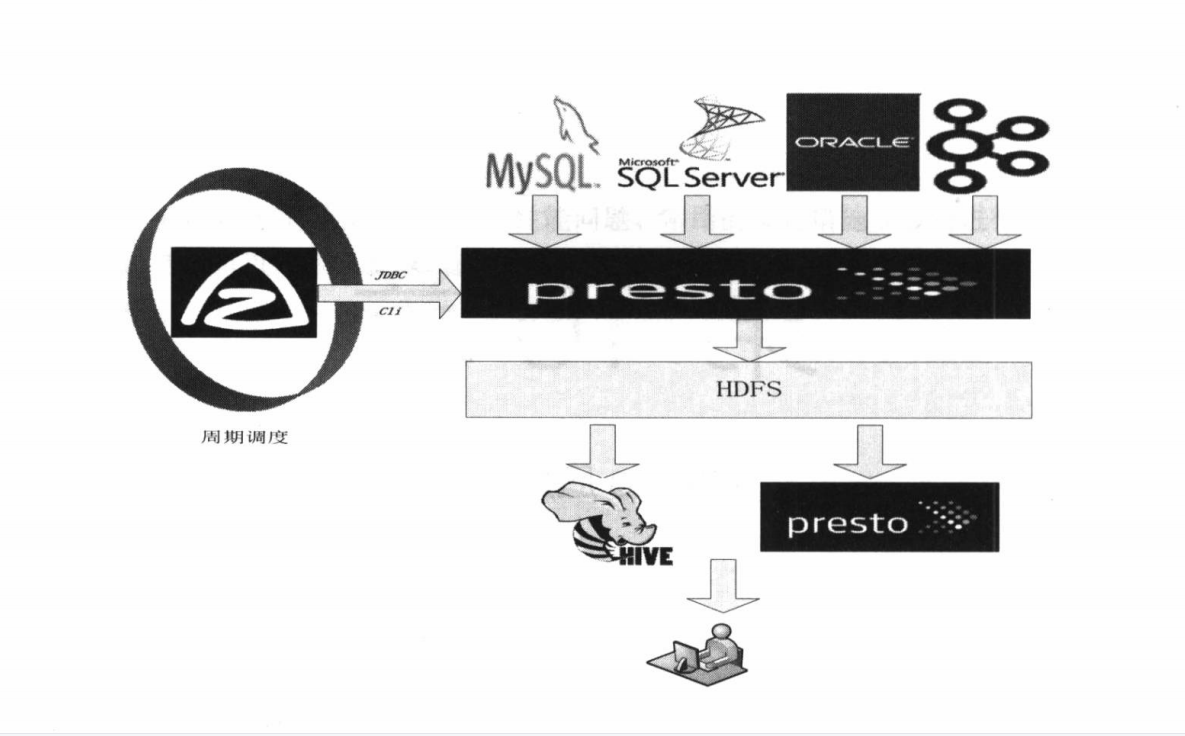
2.实时数据计算
由于Presto卓越的性能表现, 使得Presto可以弥补Hive无法满足的实时计算空白, 因此可以将Presto与Hive配合使用:对于海量数据的批处理和计算由Hive来完成; 对于大量数据(单次计算扫描数据量级在GB到TB) 的计算由Presto完成。Presto能够完成的实时计算实际上分为以下两种情况。
1.快照数据实时计算
在这种情况下,可以基于某个时间点的快照数据进行计算,但是要求计算过程快速完成(200ms~20min) 。
2.完全实时计算
要完成完全实时计算,需要满足以下两个条件。
(1)使用的基准数据要实时更新,时刻保持与线上实际数据库中的数据完全一致。
(2)计算过程要能够快速完成。
在某公司的实际使用场景中, Presto被用于下述两种业务场景中。
- 基于T+1数据的实时计算
在这种业务场景中,用户并不要求基准数据的实时更新,但是要求每次查询数据都能够快速响应。需要Presto和Hive配合使用来满足实际的业务需求。每天凌晨通过azkaban调度Hive脚本, 根据前一天的数据计算生成中间结果表, 生成完毕之后使用Presto查询中间结果表, 得出用户最终所需要的数据。满足该业务场景的解决方案如图16-2所示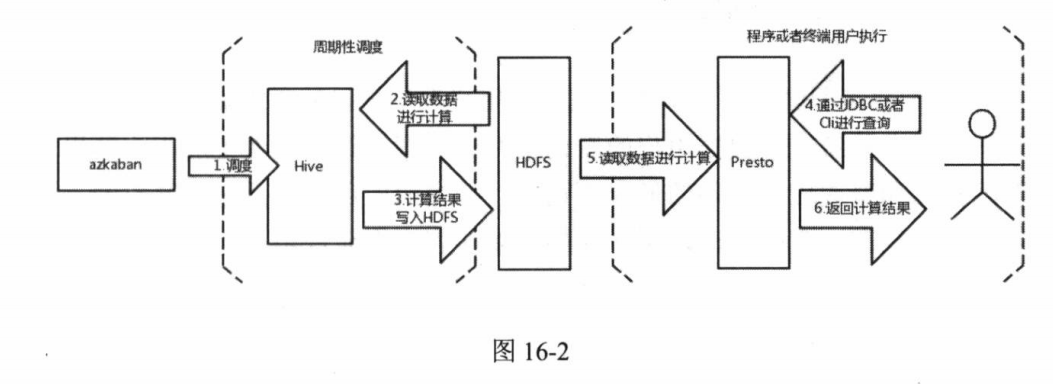
- 基于RDBMS的实时计算
在这种业务场景中,用户要求查询的数据完全实时,即只要业务库中的数据发生改变, 通过Presto查询的时候, 就可以查询到刚刚改变之后的数据。要达到这个效果,我们需要使用合理的机制保证数据实时同步,因此我们使用数据库复制技术,为线上的业务数据库建立实时同步的从库, 然后用Presto查询数据库中的数据, 进而进行计算(请注意:使用官方的Presto直接读取数据库的性能还太低, 因此建议使用JD-Presto中的PDB O从数据库中读取数据并进行计算) 。满足该业务场景的解决方案如图16-3所示。
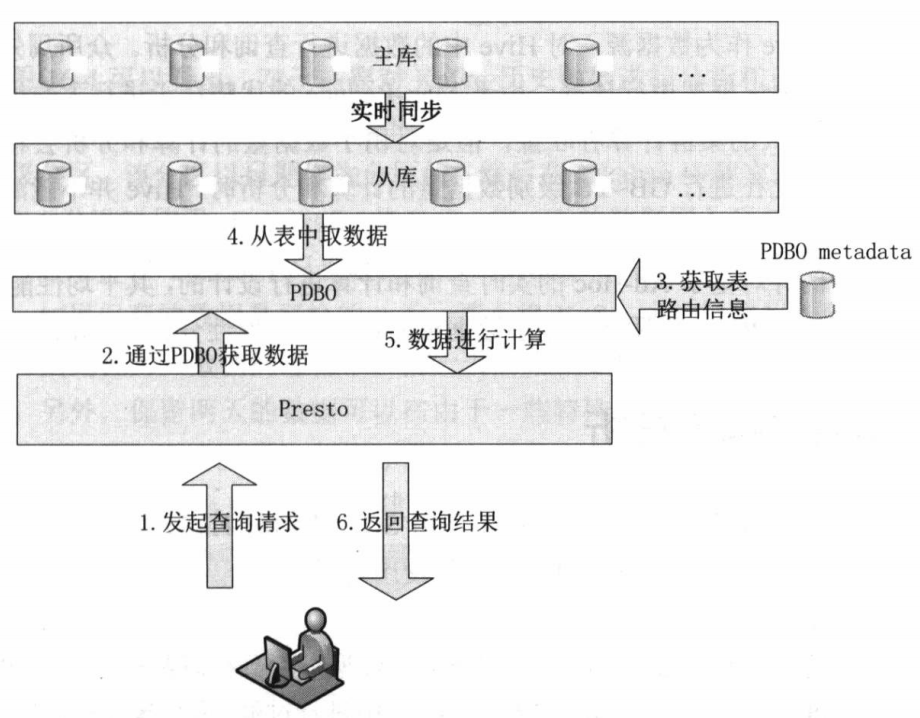
3.Ad-Hoc查询
Ad-hoc查询就是即席查询, 即席查询允许用户根据自己的需求随时调整和选择查询条件,计算平台或者系统能够根据用户的查询条件返回查询结果或者生成相应的报表。由此可见,即席查询和普通应用查询的最大不同是:普通的应用查询是定制开发的,其查询语句是固定或者限制在一定的变动范围之内的;而即席查询允许用户随意指定或者改变查询语句或者查询条件。由于普通的应用查询都是定制开发的,其查询语句几乎是固定的,因此,在系统实施时就可以通过建立索引或者分区等技术来优化这些查询,从而提高查询效率。但是即席查询是用户在使用时临时产生的、系统无法预知的,因此也无法对这些查询进行有针对性的优化和改进。
某公司使用Presto完成Ad-Hoc查询,实际的Ad-Hoc使用场景包括以下两种。
(1)使用BI工具进行报表展现
BI工具通过ODBC驱动连接至Presto集群, BI工程师使用BI工具进行不同维度的报表设计和展现。由于目前Facebook提供的ODBC驱动是使用D语言开发的,而且功能尚不完善, 因此采用Treasure Data提供的基于Presto-gres中的ODBC驱动改造之后的ODBC驱动连接到Presto集群。
(2) 使用Cli客户端进行数据分析
Presto使用Hive作为数据源, 对Hive中的数据进行查询和分析。众所周知, Hive使用Map-Reduce框架进行计算, 由于Map-Reduce的优势在于进行大数据量的批运算和提供强大的集群计算吞吐量,但是对稍小数据量的计算和分析会花费相当长的时间, 因此在进行GB~TB级别数据量的计算和分析时, Hive并不能满足实时性要求。Presto是专门针对基于Ad-Hoc的实时查询和计算进行设计的, 其平均性能是Hive的10倍, 因此Presto更适合于稍小数据量的计算和差异性分析等Ad-Hoc查询。
4.实时数据流分析
实时数据流分析主 要是指通过presto-kafka使用SQL语句对Kafka中的数据流进行清洗、分析和计算。其在 实际使用过程中有以下两种使用场景。
(1)保留历史数据
在这种使用场景下 , 由于Presto每次对Kafka中的数据进行分析时都需要从Kafka集群中将所有的数据都读取 出来, 然后在Presto集群的内存中进行过滤、分析等操作, 若在Kafka中保留了大量的历史数 据, 那么通过presto-kafka使用SQL语句对Kafka中的数据进行分析就会在数据传输上花费 大量的时间, 从而导致查询效率的降低。因此我们应该避免在Kafka中存储大量的数据,从 而提高查询性能。
某公司在这种使用 场景下, 通过使用presto-hive与presto-kafka配合, 完成历史数据的分析和查询。具体系统 架构如图16-4所示。
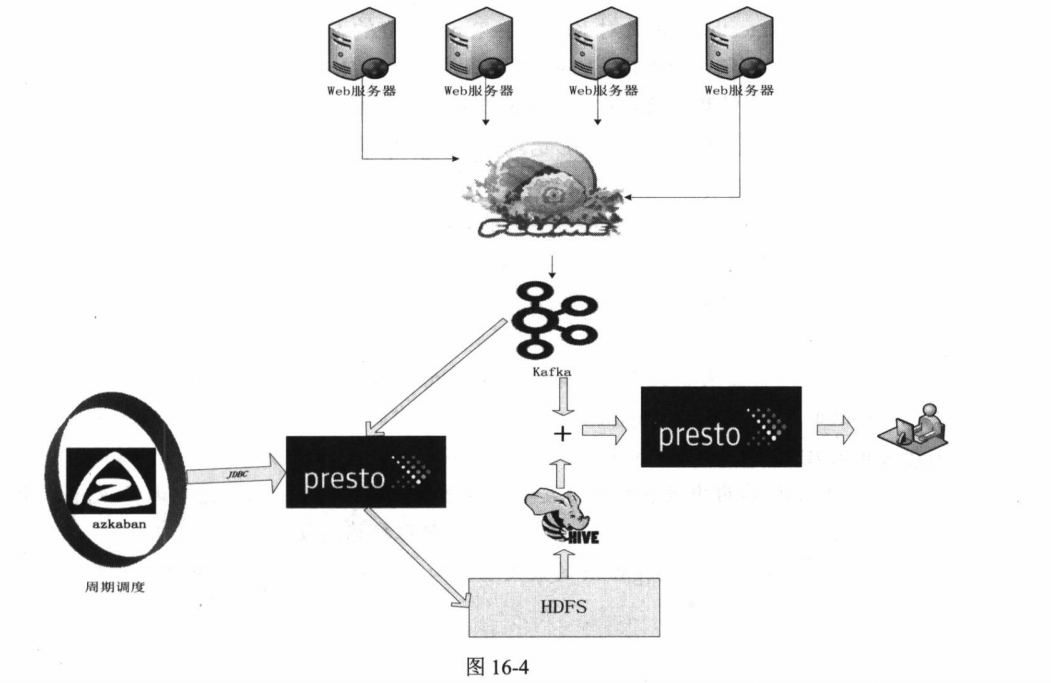
从图16-4可以看出, 对于需要对Kafka历史数据进行分析和计算的需求, 我们需要配合使用presto-hive与presto-kafka完成计算。首先我们先在Hive中建立一个分区表, 分区表有一级分区, 该分区以日期作为分区值。然后在azkaban中建立周期性调度任务, 在每天凌晨0点0分准时使用presto-kafka将Kafka前一天的数据写入到Hive的分区表前一天日期对应的分区中, 在Kafka中只保留最近两天的数据(保留两天的数据, 主要是出于容错性的考虑, 如果保存的数据是严格的一天, 那么将Kafka中的数据写入到HDFS是需要一定时间的,因此在写入数据的过程中,前一天的某些数据就有可能会被删除了,从而导致数据丢失;另外,保留两天的数据可以在由于一些特殊原因导致写入失败的时候有充足的时间进行人工干预, 从而保证数据正确写入) 。然后在Presto中创建一个View(视图) 用于组合Hive中的表和Kafka中的表, 创建视图的语句如下:
在上面的语句中, hive.test.test kafka是Hive中的表, 该表用于存储Kafka中今天之前的所有数据; kafka.test.test log 3是针对Kafka中Topic建立的表, 该Topic中存储的是最近两天的数据。从上面的语句可以看出:View其实就是组合的Hive中的全表和Kafka中当天的数据量, 这样View中的数据就是实时的最新数据。只需要对业务方开放该View的访问权限, 业务方就可以通过Presto使用SQL语句对实时流数据进行分析了。
(2)只保留最新数据
对于只需要在Kafka中只保留最近一天的数据, 其实并不需要做特殊的处理, 只需要在Kafka中限制Kafka数据的最大保留期限为24小时就可以了。然后直接通过Presto使用SQL语句对Kafka中的数据进行分析和查询即可。
注意:
在使用Presto-kafka对数据进行分析的时候, Presto是通过Split从Kafka集群中读取数据的, 而Kafka中的一个log-segment就对应Presto中的一个Split。如果Kafka中的一个log-segment太大就会导致Presto中读取的一个Split太大, 而Split个数太少, 从而严重降低Presto从Kafka集群中读取数据的效率。因此在实际应用中, 需要适当调整Kafka中log-segment的最大大小, 从而保证Presto从kafka读取数据的效率。某公司设置Kafka中log-segment的最大size为128MB, 经过实际验证, 效果非常不错。

若有收获,就点个赞吧
0 人点赞
