什么是算子下推
算子下推其实就是谓词下推概念的扩展。目的就是将外层查询块的 WHERE 子句中的谓词移入所包含的较低层查询块,从而能够提早进行数据过滤以及有可能更好地利用索引。
基本思想即:将过滤表达式尽可能移动至靠近数据源的位置,以使真正执行时能直接跳过无关的数据。
传统的谓词下推
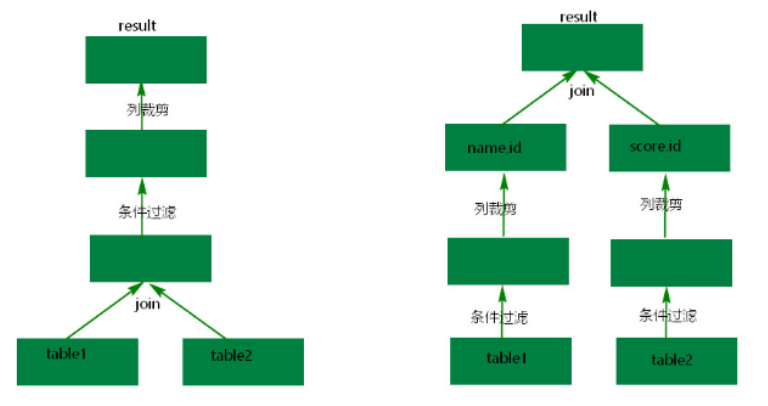
在传统数据库的查询系统中谓词下推作为优化手段很早就出现了,谓词下推的目的就是通过将一些过滤条件尽可能的在最底层执行可以减少每一层交互的数据量,从而提升性能。例如下面这个例子:
select count(1) from A Join B on A.id = B.id where A.a >10 and B.b <100;
在处理Join操作之前需要首先对A和B执行TableScan操作,然后再进行Join,再执行过滤,最后计算聚合函数返回,但是如果把过滤条件A.a > 10和B.b < 100分别移到A表的TableScan和B表的TableScan的时候执行,可以大大降低Join操作的输入数据。优化后的语句如下:
select count(1) from (select * from A where a>10 )A1 Join( select * from B where b<100) B1 on A1.id = B1.id;
OpenLookeng下推接口
将SQL进行解析,对应生成执行数解析。这个过程就会对执行的谓词算子进行优化,将过滤的计划节点提前下推。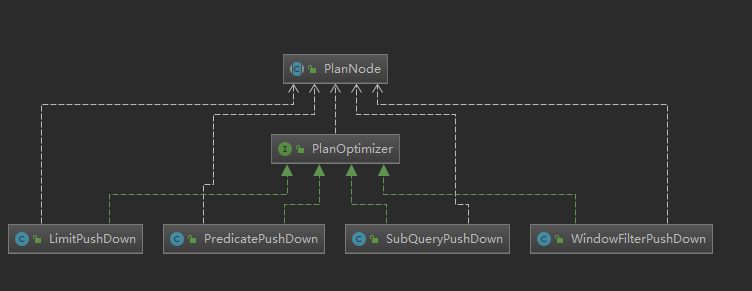
对应实现计划树的优化接口,现有实现下推接口有Limit,Predicate,SubQuery,WindowFilter。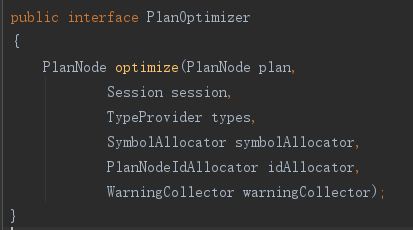

若有收获,就点个赞吧
0 人点赞
