AUC的优势:AUC的计算方法同时考虑了分类器对于正例和负例的分类能力,在样本不平衡的情况下,依然能够对分类器作出合理的评价。
AUC直观理解:随机抽出一对样本(一个正样本,一个负样本),分类器将正样本预测为正例的概率大于将负样本预测为正例的概率。
1. 什么是AUC
AUC(Area Under Curve)是一个模型评价指标,只能用于二分类模型的评价。对于二分类模型,还有很多其他评价指标,比如logloss、accuracy、precision,但是为什么AUC和logloss更常用呢?
因为很多机器学习的模型对分类问题的预测结果都是概率,如果要计算accuracy和precision,需要先手动设置一个阈值,把概率转化成类别,如果对一个样本的预测概率高于这个预测,就把这个样本放进一个类别里面;低于这个阈值,则放进另一个类别里面。所以这个阈值很大程度上影响了accuracy的计算。使用AUC或logloss可以避免把预测概率转换成类别。
ROC曲线和PR曲线:
相同:都能评价分类器的性能
不同:正负样本分布失衡时,同一个分类器,它的ROC没太大变化(AUC反映把任一正样品分类为正的概率),而它的PR曲线变化显著。实际上分类器的分类效果确实变差了,ROC曲线欺骗了我们。
2. 画出AUC
首先要根据混淆矩阵,画出ROC(Receiver Operating Characteristic)曲线。
由此引出TPR(真阳率)、FPR(伪阳率)两个概念:

仔细观察两个公式,发现其实TPR就是TP除以TP所在的列,FPR就是FP除以FP所在的列,二者意义如下:
- TPR:所有真实类别为1的样本中,被预测为类别1的比例
- FPR:所有真实类别为0的样本中,被预测为类别1的比例
以FPR为x轴,TPR为y轴,一个分类器在阈值在【0,1】范围内变化时将分别得到对应的点(TPR,FPR),将这些点连接起来,即为ROC曲线,ROC曲线之下的面积,即为AUC。
注:
- 因为FPR、TPR都是计算各类别样本被预测为1的概率,因此若阈值为1,TP、FP均为0,此时位于左下角(0,0);若阈值为0,TP、FP均为1,此时位于右上角(1,1)。
- 随着阈值减小,ROC曲线一定向右上(包括右、上)移动。
按照定义,AUC即ROC曲线下的面积,而ROC曲线的横轴是FPR,纵轴是TPR,当两者相等时,即 y=x ,如下图: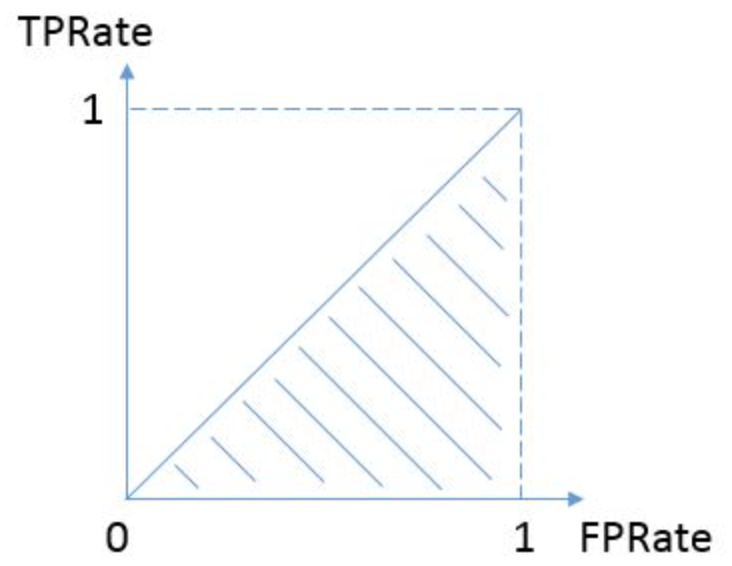
表示的意义是:对于不论真实类别是1还是0的样本,分类器预测为1的概率是相等的。(相当于随机预测)
而我们希望分类器达到的效果是:对于真实类别为1的样本,分类器预测为1的概率(即TPR)要大于真实类别为0而预测类别为1的概率(FPR),即 y>x ,因此大部分的ROC曲线像下面这样: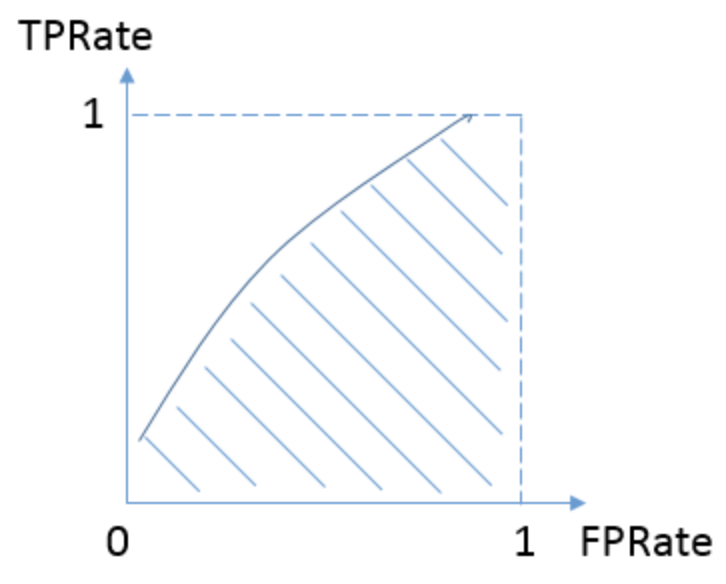
3. 计算AUC
AUC计算时,令正例样本有M个,负例样本有N个,则共有 MxN 对正负样本,AUC的值即 MxN对样本中,满足将正例预测为1的概率大于将负例预测为1的概率的对数占比。
- 对预测概率从高到低排序
- 对每一个概率值设置一个rank值,表示其超过的样本的数目
- 将所有正例样本的rank值相加,表示取正例 x2 时,可以取得的 x1 满足要求 p1<p2 的总个数
- 但 x1 中还包含正例,不能取,应减去。例如,若 x2 为最大的正例,则应减去概率比它小的 M-1 个正例;若 x2 为次大正例,则应减去比它概率小的 M-2 个正例;以此类推
所以计算公式如下:
def auc_calculate(labels,preds,n_bins=100):postive_len = sum(labels)negative_len = len(labels) - postive_lentotal_case = postive_len * negative_lenpos_histogram = [0 for _ in range(n_bins)]neg_histogram = [0 for _ in range(n_bins)]bin_width = 1.0 / n_binsfor i in range(len(labels)):nth_bin = int(preds[i]/bin_width)if labels[i]==1:pos_histogram[nth_bin] += 1else:neg_histogram[nth_bin] += 1accumulated_neg = 0satisfied_pair = 0for i in range(n_bins):satisfied_pair += (pos_histogram[i]*accumulated_neg + \pos_histogram[i]*neg_histogram[i]*0.5)accumulated_neg += neg_histogram[i]return satisfied_pair / float(total_case)
Q&A:
为什么AUC越大模型就越好?
因为AUC越大,表示该模型的ROC曲线越靠近左上角,将正例预测为1的的概率大于将负例预测为1的概率。ROC曲线相比P-R曲线有什么特点?
(训练集与测试集正负样本比例相近用AUC,差异大用PR)
当正负样本的分布发生变化时,ROC曲线的形状能够基本保持不变,而P-R曲线的形状一般会发生较剧烈的变化。
ROC能够尽量降低不同测试集带来的干扰,更加客观的衡量模型本身的性能。如果研究者希望更多地看到模型在特定数据集上的表现,P-R曲线能够更直观地反映其性能。f1-score局限性
若A模型precision大、recall小,B模型precision小、recall大,显然两模型不同(precision大强调不能错,适合门禁系统;recall大强调不能少,适合发掘潜在客户),但两模型的f1-score可能相同。目标函数和评估指标区别
以逻辑回归为例,目标函数用于确定模型,用的是交叉熵;而评估指标用于评价模型,用ROC-AUC或PR-AUC。准确率(Accuracy)局限
对于正负样本不平衡的情况,准确率通常不具备参考价值(如99负样本和1正样本,模型全部预测为负样本,准确率为99%)

若有收获,就点个赞吧
0 人点赞
