1. 词的表示方法
语言是高度抽象的离散符号系统,为能够使用神经网络来解决NLP任务,几乎所有的深度学习模型都要在第一步把离散的符号变成向量。用向量来表示一个点,通常把这个向量叫做词向量。
最常见的词向量是one-hot表示法,但它有两个缺点:会造成维度爆炸、不能根据向量间的距离反映不同词之间的语义关系。
2. Word2Vec
我们可以使用语言模型(例如机器翻译)来获得词向量,但语言模型的训练非常慢,词向量是这些任务的副产品。而Mikolov等人提出的Word2Vec直接用于词向量训练,模型速度更快。
Word2Vec的基本思想:一个词的语义可以由它的上下文确定,Word2Vec有两个模型:
- CBOW:用上下文预测中心词向量,类似英语完形填空- Skip-Gram:用中心词预测上下文向量,能够更好训练长尾词汇
2.1 CBOW:上下文是一个词
上下文是一个词的CBOW模型如下图,其中词典的大小为V(词的个数),隐藏层的单元数为N(词向量维度)。输入输出均为one-hot形式词向量。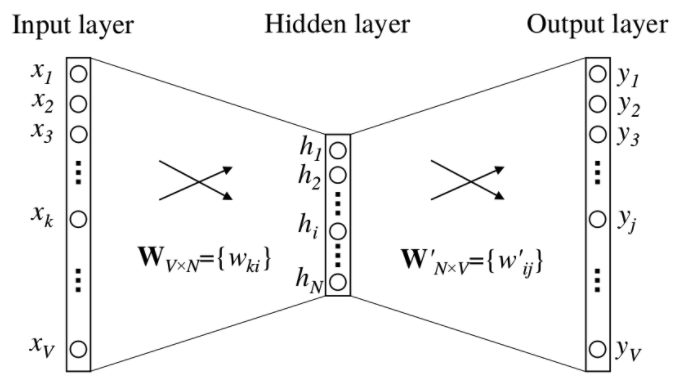
表达式如下:

其中 分别为
分别为 的列向量。需再对所有
的列向量。需再对所有 进行softmax,得到输出概率
进行softmax,得到输出概率 ,计算如下:
,计算如下:
使用交叉熵损失,损失函数计算方式如下:
其中 表示目标向量one-hot的index,由
表示目标向量one-hot的index,由 可知E与所有
可知E与所有 均有关,损失函数对
均有关,损失函数对 求偏导,结果如下:
求偏导,结果如下:
所以参数更新梯度为:


 和
和 第
第 行数据。
行数据。
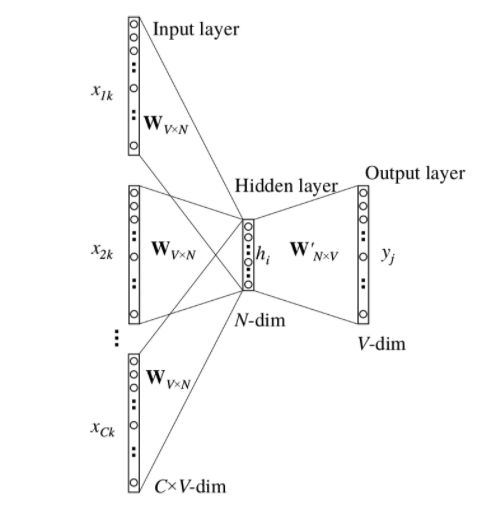
2.2 多个词的上下文
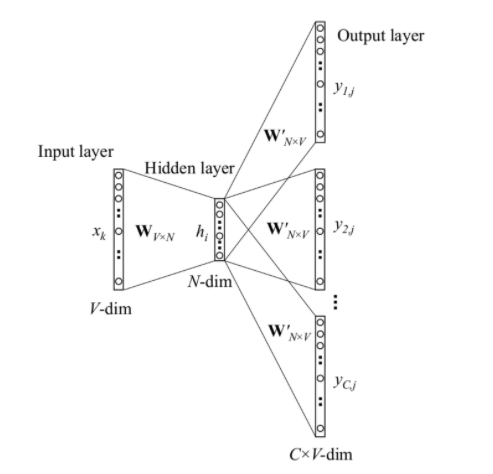
2.3 Skip-Gram模型
3. 计算效率
3.1 Hierarchical Softmax
将词汇作为叶结点,根据出现频率构造霍夫曼树,每个非叶结点概率等于其左右子节点概率之和,根节点概率为1(即所有叶子节点概率值之和为1,与softmax等效),通过hierarchical softmax将时间复杂度由O(n)降低为O(logn)
3.2 Negative Sampling
对于每一个正样本,只需采样k个负样本(论文中对于小数据集k取值5~20,大数据集k取值2~5),即可快速得到近似效果。
4. 总结
1. CBOW与Skip-gram的时间复杂度
论文中CBOW与Skip-gram的时间复杂度分别为:
其中N为序列数、D为embedding维度、V为词汇表长度、C为Skip-gram窗口大小,使用lookup table时,计算量主要集中于decode阶段,由上述时间复杂度计算公式可知Skip-gram的时间复杂度明显大于CBOW,且随超参数C的增加,这种现象会更加明显。
2. CBOW与Skip-gram训练方式
论文中两种形式的训练方式分别如下:
- COBW:上下文预测中心词,通过multi-hot向量,通过lookup table得到多个embedding向量,将它们取均值(或求和)后进行decode;- Skip-gram:中心词预测上下文,通过one-hot向量,通过lookup table得到一个embedding向量,decode后得到上下文中的每一个词(每一次前向计算预测其中一个)。
3. CBOW与Skip-gram效果
由于训练方式差异,CBOW中每当出现一个词时会对它进行一次训练,而Skip-gram中每当出现一个词,会对它进行2C次训练(窗口为C),显然Skip-gram更易得到更好的结果;且由于Skip-gram训练方式的特性同时也使得它能够更好地处理长尾词汇,设置频率域值时可较CBOW设置得更低一些。实验效果如下: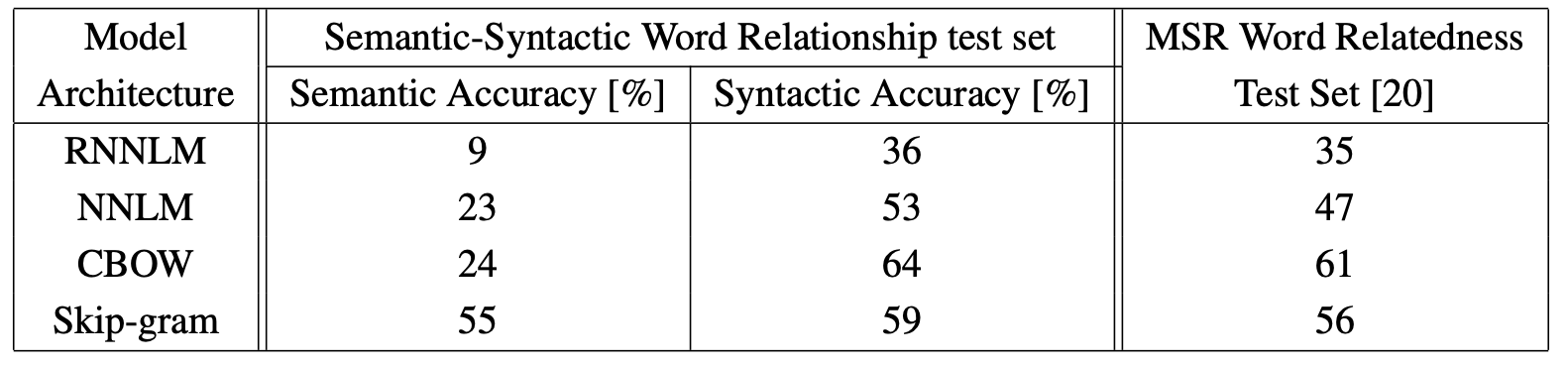
4. embedding维度与效果的关系
增大vector_size能够得到更好的效果,根据原论文实验,同时考虑内存与性能间的trade off,vector_size设置300左右较好,相关结果如下: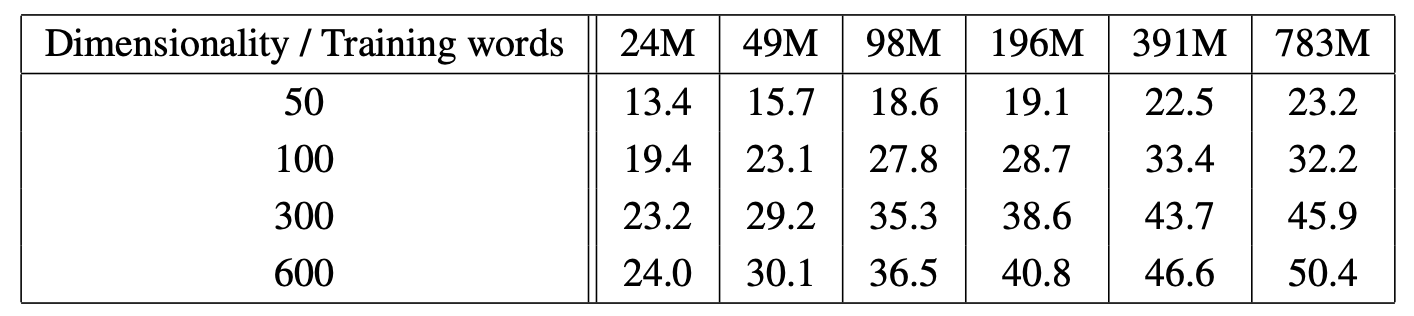
5. embedding效果对数据量和维度的敏感度
在一批数据上训练3个epoch,效果比不上在两杯数据集上训练一个epoch。因此提高数据量对提高embedding效果贡献更大,实验如下: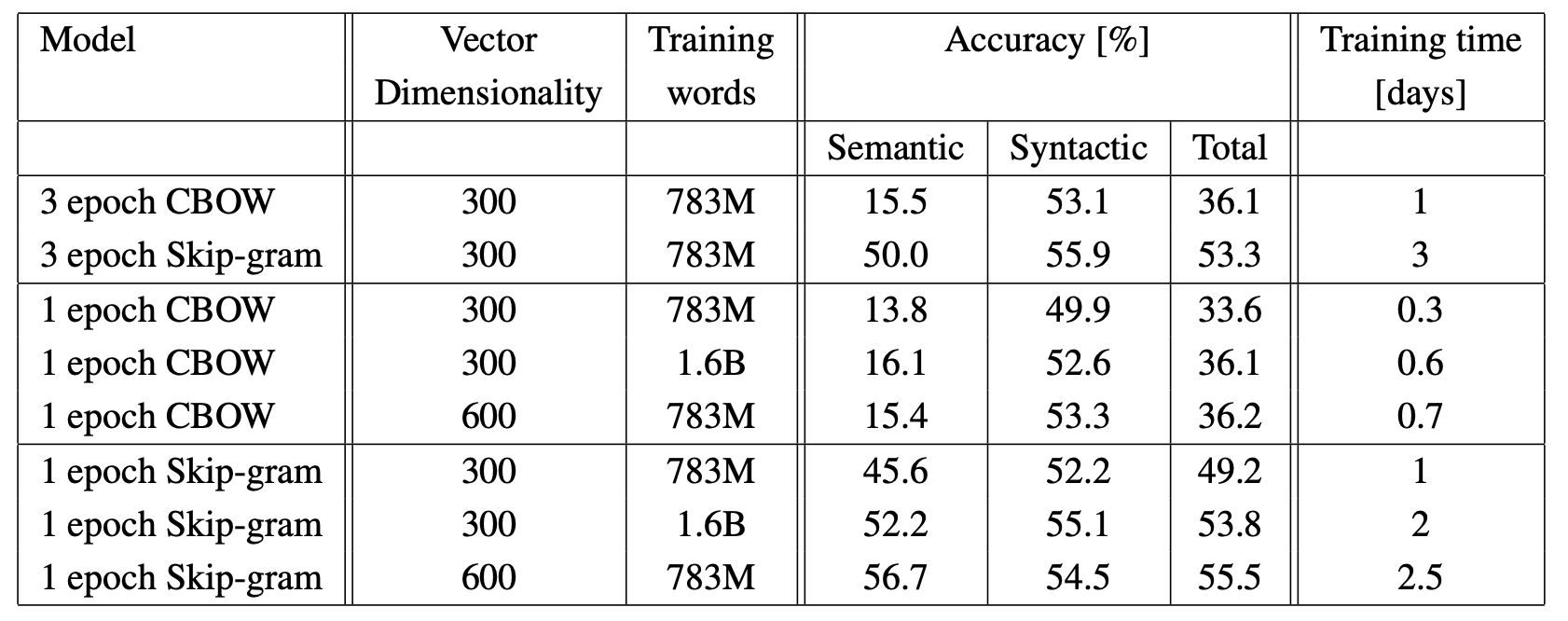

若有收获,就点个赞吧
0 人点赞
