1. 模型建立
在不清楚每棵树的具体结构时,直接最优化目标函数显然时不可能的,XGBoost算法利用加法模型简化目标函数,在前面的树的基础上训练下一棵决策树,令 ,有:
,有:
因此,模型可表示如下:
其中 表第
表第 棵树,
棵树, 表示样本
表示样本 在中的得分。
在中的得分。
2. 目标函数
XGBoost的目标函数由损失函数和正则项两部分组成,分别控制模型的准确度和复杂度(防止过拟合),定义如下:
其中 表示XGBoost模型的参数,
表示XGBoost模型的参数, 是二阶连续可导的函数。
是二阶连续可导的函数。
3. 参数估计
假设已有 棵树,则在生成第
棵树,则在生成第 棵树的过程中的目标函数为:
棵树的过程中的目标函数为:
令 ,将函数在
,将函数在 处泰勒展开,得:
处泰勒展开,得:
代入上式 中,有:
中,有:
在 生成过程中,前面的树为常数,优化过程只需考虑与相关项,即:
生成过程中,前面的树为常数,优化过程只需考虑与相关项,即:
令 ,其中
,其中 为叶子结点个数,
为叶子结点个数, 为得分。再定义映射到叶子结点
为得分。再定义映射到叶子结点 的样本集合为
的样本集合为 ,并且
,并且 和
和 ,得:
,得:
根据二次函数求极值点方法,解得:
代入该目标函数,得:
4. 生成过程的度量指标
根据上一节解得的目标函数,生成树过程中信息增益计算如下:
其中第一部分表示分裂后与分裂前的增益情况,第二部分为复杂度惩罚因子,用于衡量额外叶子节点带来的复杂度损失。
5. 一些优化(加速)方法
1. 收缩和列采样
在防止过拟合方面,除了在目标函数中加入正则项,收缩和列采样也经常使用。
- 收缩相当于梯度下降中的学习率,降低每棵树对整体模型的影响;- 列采样采用了bagging思想,不仅能够防止过拟合,还能显著提高计算速度。
2. Column Block for Parallel Learning
树学习中最耗时的部分是数据排序,为减少排序成本,提出在训练前对每个特征的所有数据按特征值进行排序,按顺序排列结果分别保存它们的统计量( )对应的索引。这样后续迭代过程中不需要再对数据进行排序,如下图所示
)对应的索引。这样后续迭代过程中不需要再对数据进行排序,如下图所示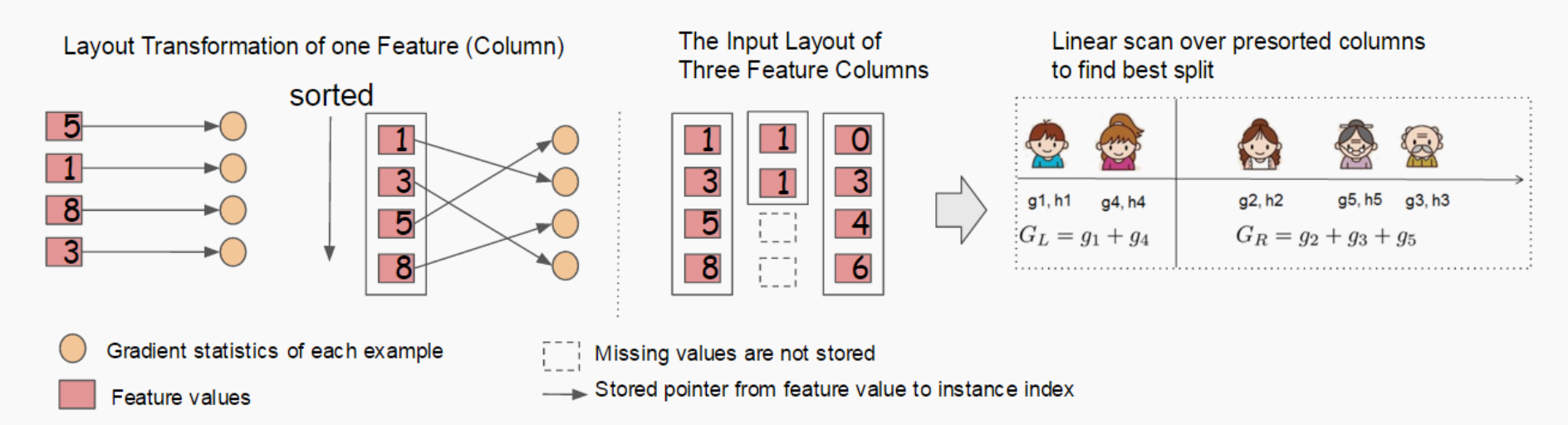
Column Block示意图
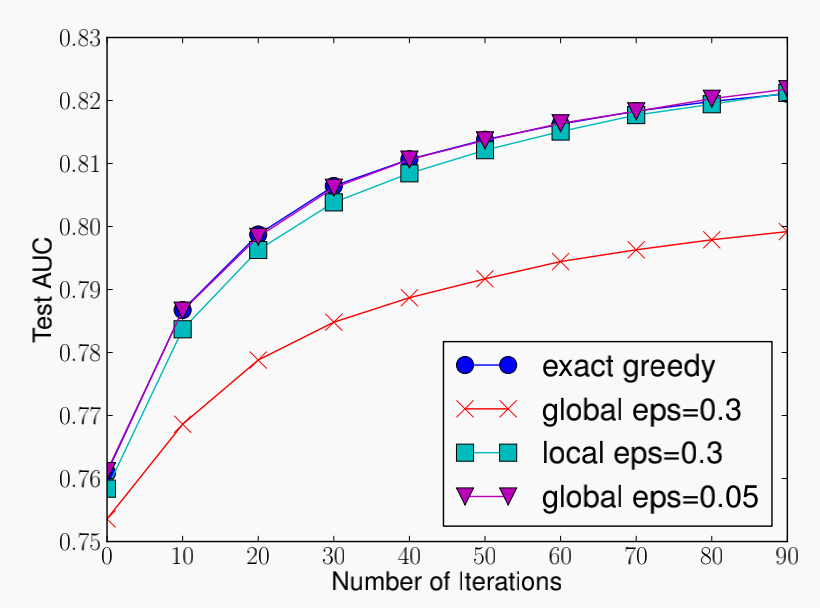
3. 近似计算
常规树学习模型采用贪心算法,通过枚举所有点找到最佳分裂节点,这种方法通常可行。但当数据量很大、数据不能一次性全部读入内存时,贪心算法效率会极大下降,此时需要一种近似计算方法。
近似算法:按照特征值(或 值)的分布选择一些百分位点(或通过分箱)作为候选分裂点,又分为两个方法:
值)的分布选择一些百分位点(或通过分箱)作为候选分裂点,又分为两个方法:
- 全局选择:仅在树构造前选择处候选分裂点(候选节点足够多时达到局部选择的效果)- 局部选择:每次分裂后更新候选分裂点(一般效果较好)
4. 稀疏\缺失处理
在许多情况中,输入 是稀疏的(或有缺失值),XGB通过在树节点中添加默认划分方向的方法对稀疏\缺失数据进行处理。首先忽视缺失数据,寻找最佳分割点,再将缺失数据样本分别划分到两个叶子节点,取信息增益最高的结果。
是稀疏的(或有缺失值),XGB通过在树节点中添加默认划分方向的方法对稀疏\缺失数据进行处理。首先忽视缺失数据,寻找最佳分割点,再将缺失数据样本分别划分到两个叶子节点,取信息增益最高的结果。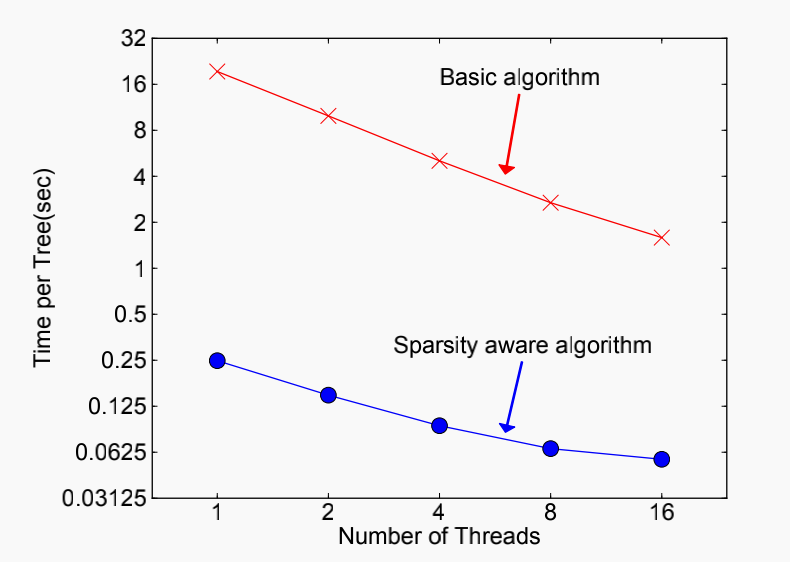
引入稀疏感知处理后速度有较大提升

若有收获,就点个赞吧
0 人点赞
