1. 简介
GBDT是个人气很高的机器学习算法,也有不少高效的实现(如XGBoost),但当面对数据样本量极大、特征维度非常高时,就会开始显得力不从心。主要原因在于对每个特征,都需要扫描所有的数据从而找到最佳分割点,这是非常耗时的。
针对样本量大和特征维度高,LightGBM在XGBoost基础上提出GOSS(Gradient-based One-Side Sampling)和EFB(Exclusive Feature Bundling),分别应对这两个问题。
2. 改进点
1. 直方图算法
XGBoost采用预排序算法降低排序成本,将样本按照特征取值排序,在训练过程中直接顺序取值寻找最优分裂点位,该算法的候选分裂点数与样本数量成正比。
LightGBM采用直方图算法代替预排序算法,通过对连续值进行分箱实现特征离散化, ,达到加速的目的。
,达到加速的目的。
2. 基于梯度的单边采样算法(GOSS)
GOSS是一个采样算法,目的是丢弃一些对计算信息增益没有帮助的实例,解决样本量极大的问题。GOSS主要根据样本梯度绝对值大小对每个样本赋予采样权重,可证明具有较大梯度的数据对信息增益的贡献较大,一个直接的想法是丢弃所有梯度较小的数据,但这样会改变数据的总体分布。
- **GOSS的做法:每次迭代**时先根据梯度大小对**所有样品**降序排序,选取绝对值最大的前数据,权重均为,再对剩下的梯度较小的数据随机选择,权重均为,然后使用这数据进行这一轮模型训练,如下:

3. 互斥特征绑定算法(EFB)
EFB是一种降维算法。高维数据通常非常稀疏,特征空间的稀疏性为设计一个近似无损失减少参数数量的方法提供了可能。EFB通过把互斥(不同时为0)特征打包到一个单一特征中,可以极大的加速GBDT的训练,且不影响准确率(树模型不受量纲影响)。
1. **将哪些特征绑定到一起:**在训练前预先计算每个特征与其他特征的冲突率(同时为非零值概率),把每个特征看作一个节点,特征间冲突率为连接两节点的边的权值,构建出一个的邻接矩阵。将该问题转换为无向图着色问题(_对所有节点按非零冲突率连接个数由大到小排序,再进行迭代。每轮迭代使用一个颜色,按排列顺序依次寻找未着色的节点,并判断是否可以为当前节点染当前颜色,满足它的相邻节点均与它不同色。这样能以最少的颜色数对所有节点进行染色_),其中相同颜色的点被认为是互相不冲突(不同时为非零)的,可绑定到一个特征中。1. **如何绑定:**绑定问题的一个关键点是要求保证原始特征可以在绑定后的特征中区分出来。考虑到直方图算法将连续的值保存为离散的bins,可以通过对绑定前的每个特征的值加一个偏差以将不同特征的值分到绑定后特征的不同区间(bin)中去。(_如在bundle中绑定了两个特征A和B,A特征的原始取值区间为__,B特征的原始取值区间为,则可对B特征中的值都加一个偏差常量10,将其取值范围变为,这样融合后的特征C的取值区间即为,且其中__属于原来的A特征,__属于原来的B特征。_)
4. Leaf-wise建树
XGBoost是Level-wise建树,而LightGBM采用Leaf-wise建树,示意图如下: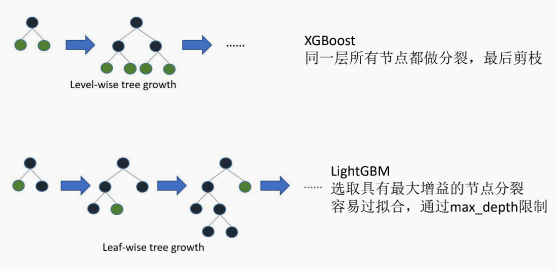
level-wise与leaf-wise建树过程示意图
3. 速度对比
- 在XGB和LGB在实例中的速度比较如下:
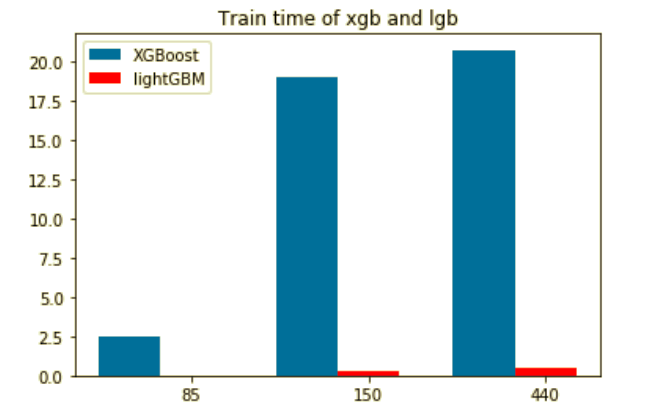
XGBoost和LightGBM在实例中的速度对比
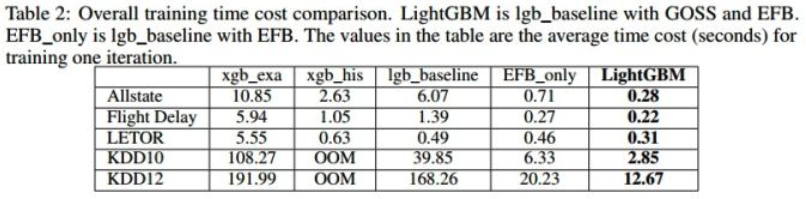
- 对XGBoost、不使用GOSS与EFB的LightBGM(lgb_baseline)、xgb_exa(预排序算法)、xgb_his(基于直方图的算法)等进行速度对比如下:

若有收获,就点个赞吧
0 人点赞
