
1. Abstract
大规模推荐系统领域主要面临来自三个方面的挑战:Scale、Freshness、Noise。本文从召回和排序两个层次,介绍YouTube如何设计推荐系统以应对上述问题。
主要网络结构如下: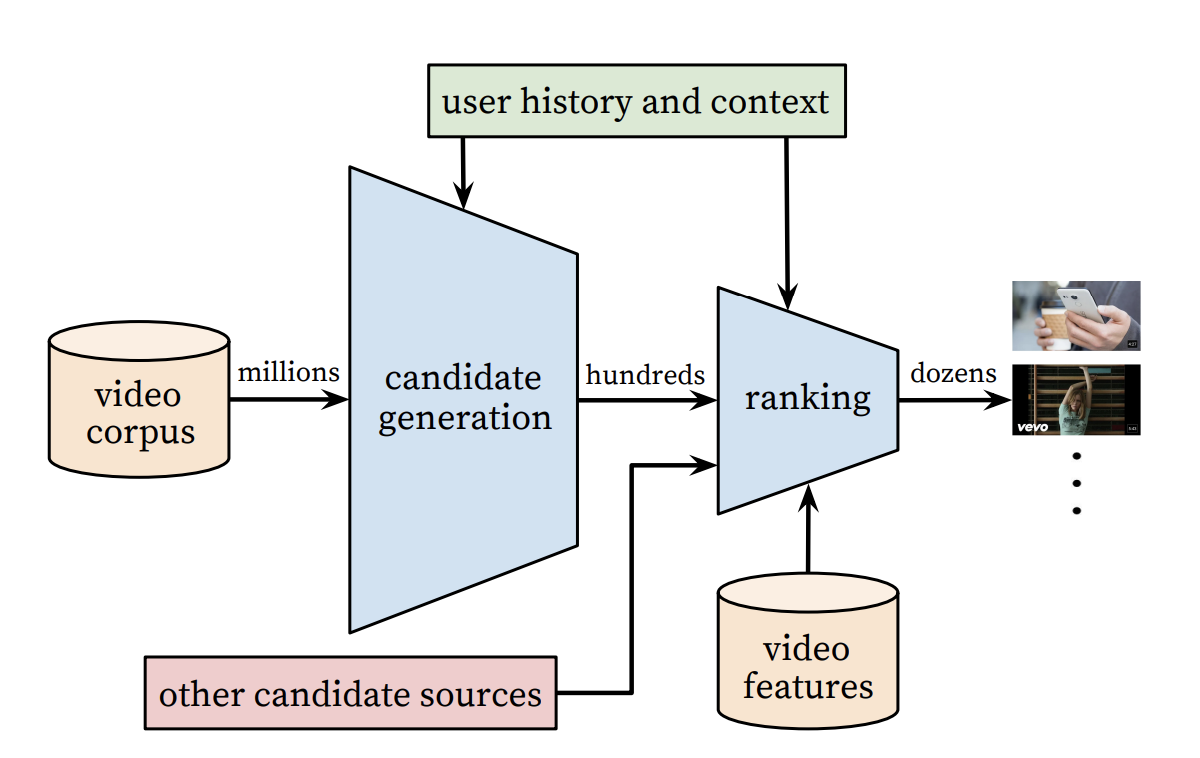
2. Candidate Generation
YouTube首先通过召回网络从百万量级的视频规模中筛选出数百个与当前用户最相关的结果,模型结构如下: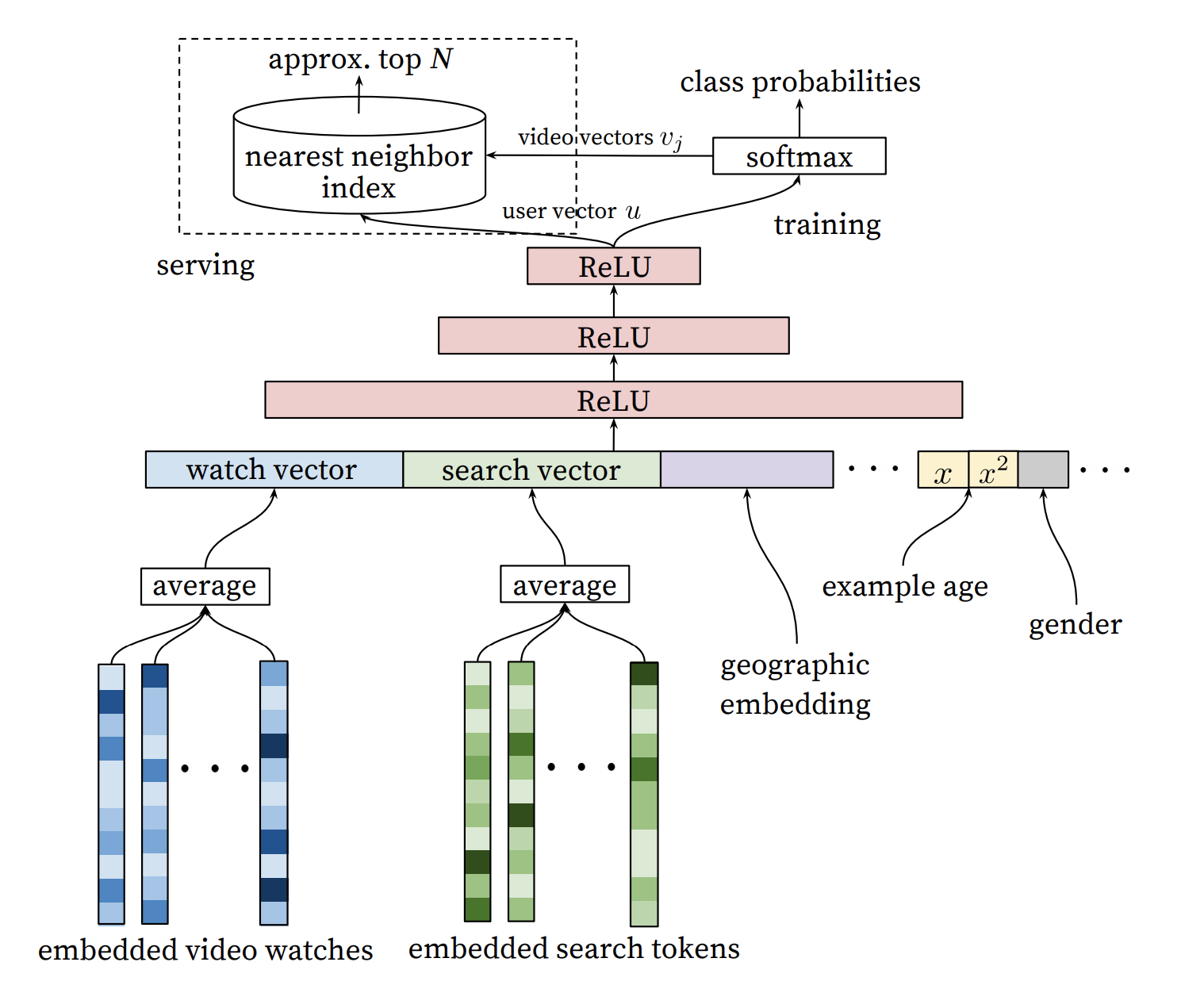
2.1 Recommendation as Classification
在召回层阶段,使用DNN进行多分类代替过去的矩阵分解方法,关系式如下:
其中分别为视频和用户的embedding向量,分别为当前用户和其上下文信息。在该层中进行如下几项工程优化:
- 阶段以用户观看完视频的行为为正样本,得到更加丰富的正样本;
- 使用negative sample(对每一个正样本,抽取一千负样本),模型训练加快了100倍;
- 在inference阶段取消softmax层,通过召回网络得到的user embedding在所有video embedding中进行最近领搜索,获得召回层结果;
- 考虑到用户在自己喜欢的领域会偏好最新的video,引入age(video从第一次被曝光到当前的时长)特征;
- 在训练阶段,每个用户采样相同数量训练数据,以防止模型损失被非常活跃的用户主导;
- 丢弃时序特征,防止模型过分依赖序列数据,导致embedding训练不充分(最近被Google技术人员透露是因为当时RNN使用存在BUG导致效果不好才得出这种结论,实际有用,后来改掉BUG后已采用该特征);
由于用户的观看序列通常都是连续、有关联的,故预测下一次可能观看视频比预测是否会观看任意视频效果更好。
3. Ranking
在排序阶段,由于数量级较小,模型可以使用更多的user、video特征。根据业务场景需要,rank层使用加权逻辑回归代替常规逻辑回归,起到预测观看时长的效果,具体结构如下:
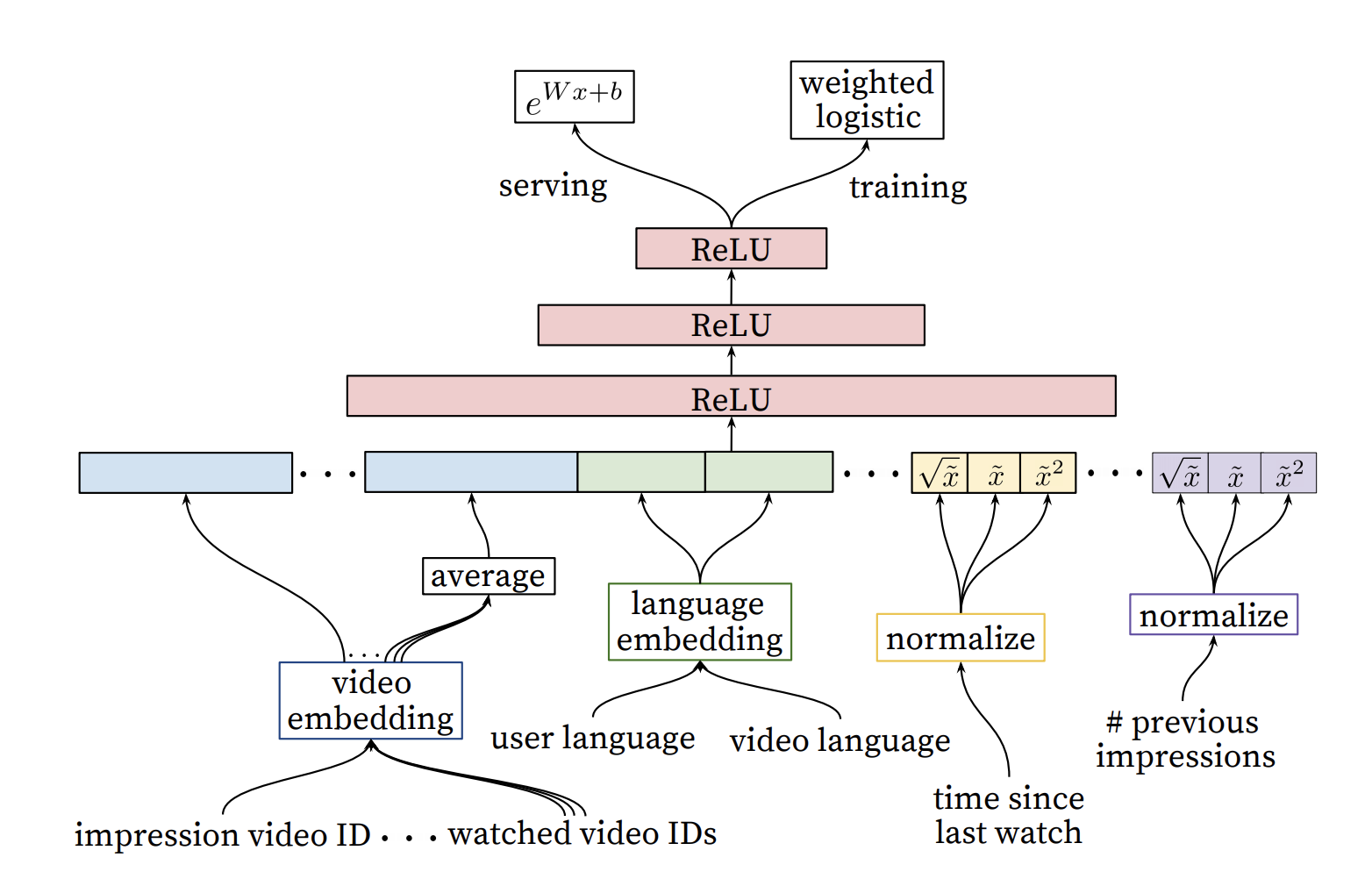
在ranking层进行的优化有:模型从商业模型角度出发,观看时间越长,则广告收益越多,同时能够打压标题党;
- 在对video进行embedding时,只选择topN进行embedding,其余用全0进行填充,一方面节省时间,另一方面低频ID特征常常训练结果并不好(实际操作中将低频词汇去掉后embedding效果往往更好);
- 对部分归一化后的特征进行开根号和平方,构造新特征,达到提升模型表现力的效果,能提高模型的离线准确度。

若有收获,就点个赞吧
0 人点赞
