
1. Abstract
针对标准embedding方法难以处理词汇表过大和冷启动的问题,提出DHE(Deep Hash Embedding),将embedding过程分为两个部分:
- Dense Hash Encoding:encoding阶段对数据使用大量hash函数得到一个unique向量,代替常规的one-hot向量(或2个哈希再one-hot encoding的结果拼接而成的multi-hot向量)
- Deep Embedding Network:上述向量送入DNN,得到最终embedding向量
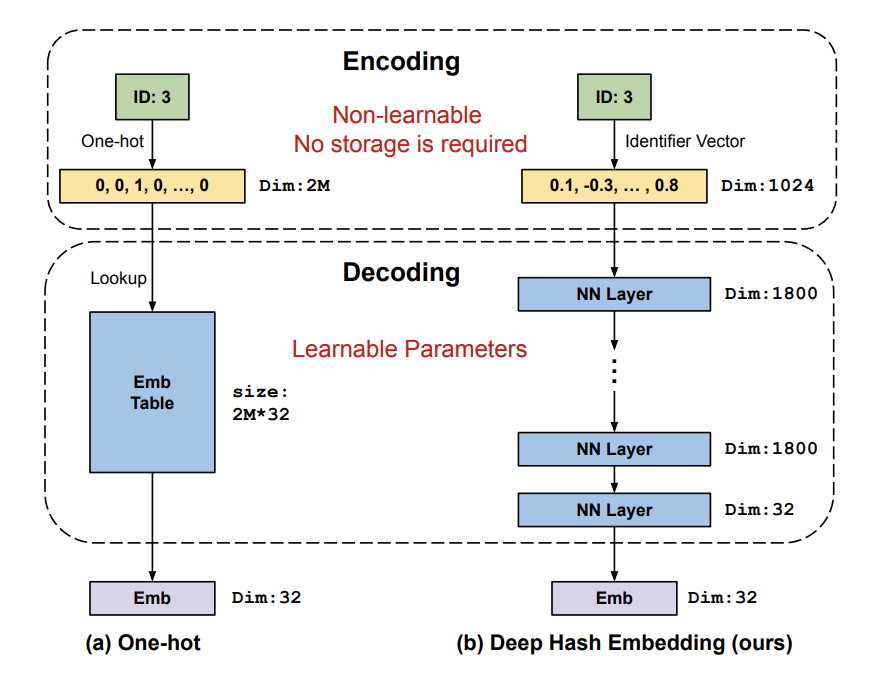
2. Dense Hash Encoding
首先把将ID类数据变换为数值向量的过程定义为encoding过程,而将数值向量变换为embedding向量的过程定义为decoding过程。DHE的encoing过程如下:
其中:
上述为ID类特征的encoding结果,为哈希函数,与传统的One-hot Hash Embedding方法中通常k取2、且将k个哈希结果进行One-Hot编码并拼接以得到encoding结果不同,DHE的哈希结果不再进行One-Hot编码,而是直接将哈希结果作为encoding某一维度上的取值(即DHE的encode结果不是稀疏向量),因此DHE可以使用更多的哈希函数(论文中k取1024),确保每一个ID都有单一的向量表示。哈希函数k取值与实验效果对应关系如下:
由于是由实数构成的向量,考虑到量纲问题,输入DNN前需进行预处理,常见的变换方式有归一化和标准化两种,实验中发现两种预处理方式效果相近,论文中最后采用归一化进行处理,具体效果对比如下:
3. Deep Embedding Network
在decoding阶段,通过由到的转换获得最终embedding结果。传统decoding过程通过embedding lookup直接获得embedding结果,相当于经过了一层非常宽的网络。根据ICLR《Why Deep Neural Networks for Function Approximation》得到的结论:提高网络深度比提高网络宽度更parameter-efficient,故论文决定在decoding阶段采用DNN代替embedding lookup,如此一来网络需要更少的参数,且不再需要花费内存保存传统方法中的lookup table,只需保存网络参数即可(但是速度变慢了,满足不了实时性的要求)。decoding阶段参数量如下:
其中h为隐藏层的层数,隐藏层层数与模型表现效果对比如下: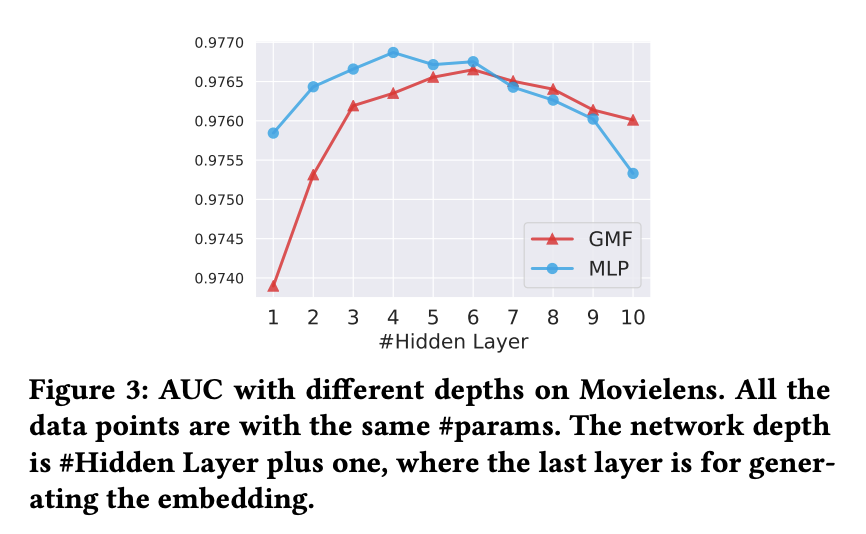
在不同数据集上实验效果如下: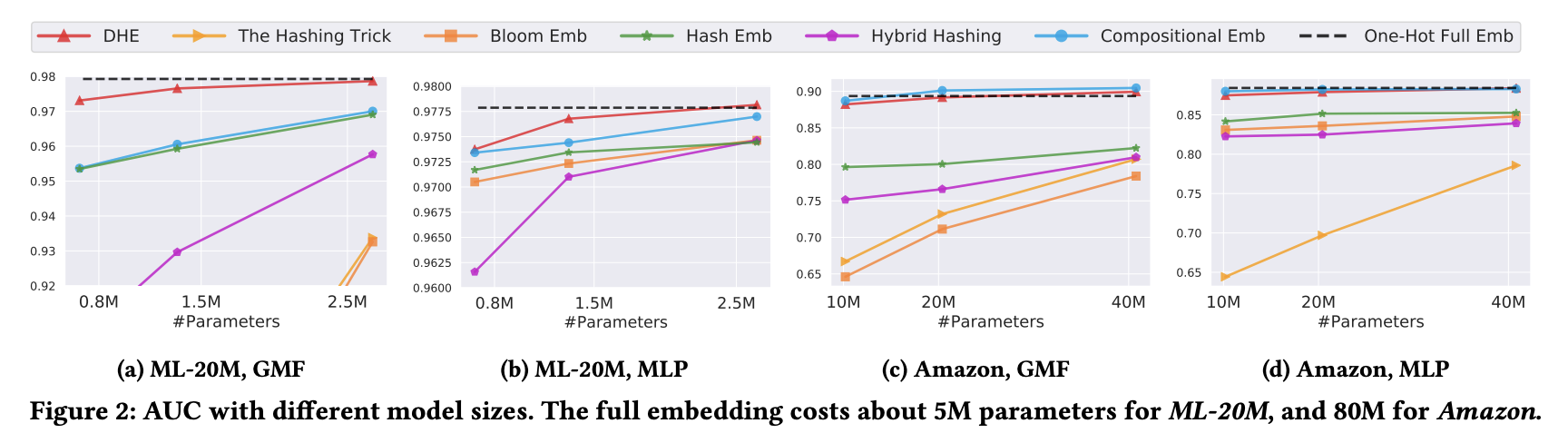
在实验中,作者发现DNN可能存在欠拟合的情况,使用dropout没有提升模型性能,也进一步验证了猜测。考虑导致欠拟合的原因是relu激活函数表达能力不够强,换用mish激活函数后可提高模型表现,并且BN也能够帮助提升模型效果,实验效果对比如下: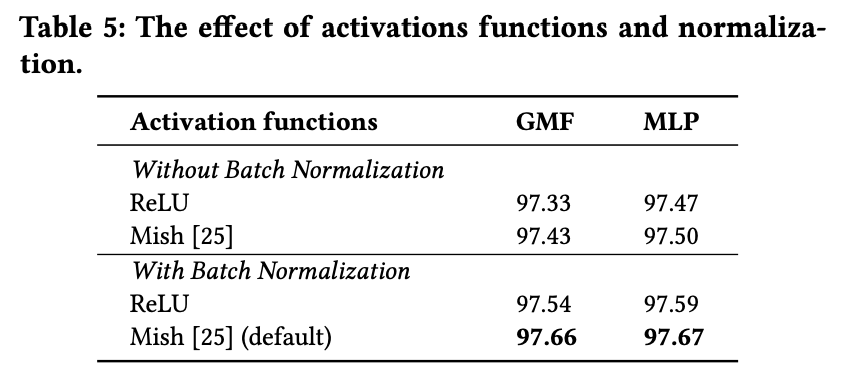
4. Side Features Enhanced Encodings for Generalization
在encoding的基础上,还可以加入side information,一方面能够提升embedding效果,另外也可以通过人口统计学信息解决冷启动问题。效果对比如下: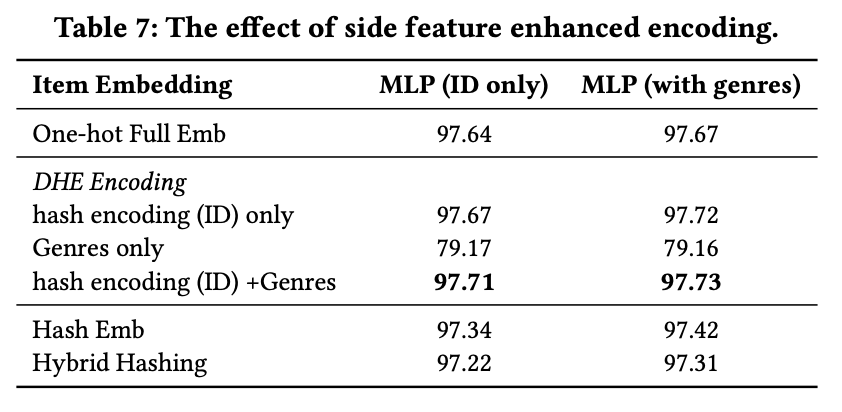

若有收获,就点个赞吧
0 人点赞
