假设空间:模型所有参数的取值集合 样本空间:训练集中输入值的集合
模型训练其实就是在假设空间中进行搜索的过程
1. 发现过拟合
过拟合最直观的表现就是 training accuracy 特别高,但是testing accuracy 特别低,即两者相差特别大。
2. 过拟合产生原因
(1) 训练数据不足
当我们训练数据不足的时候,即使得到的训练数据没有噪声,训练出来的模型也可能产生过拟合现象,解释如下:
假设我们的总体数据分布如下: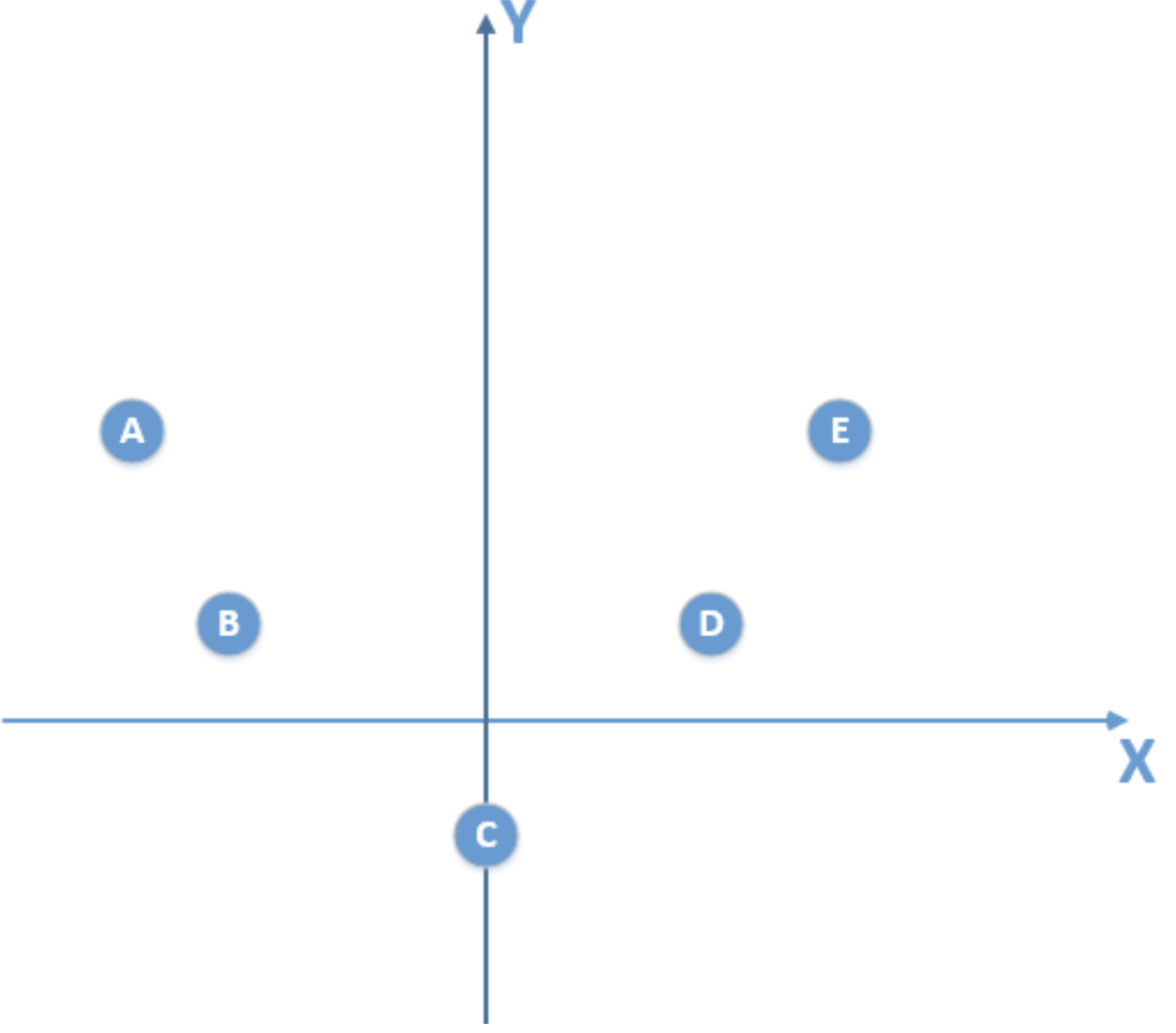
我们得到的训练数据由于是有限的,比如是下面这个: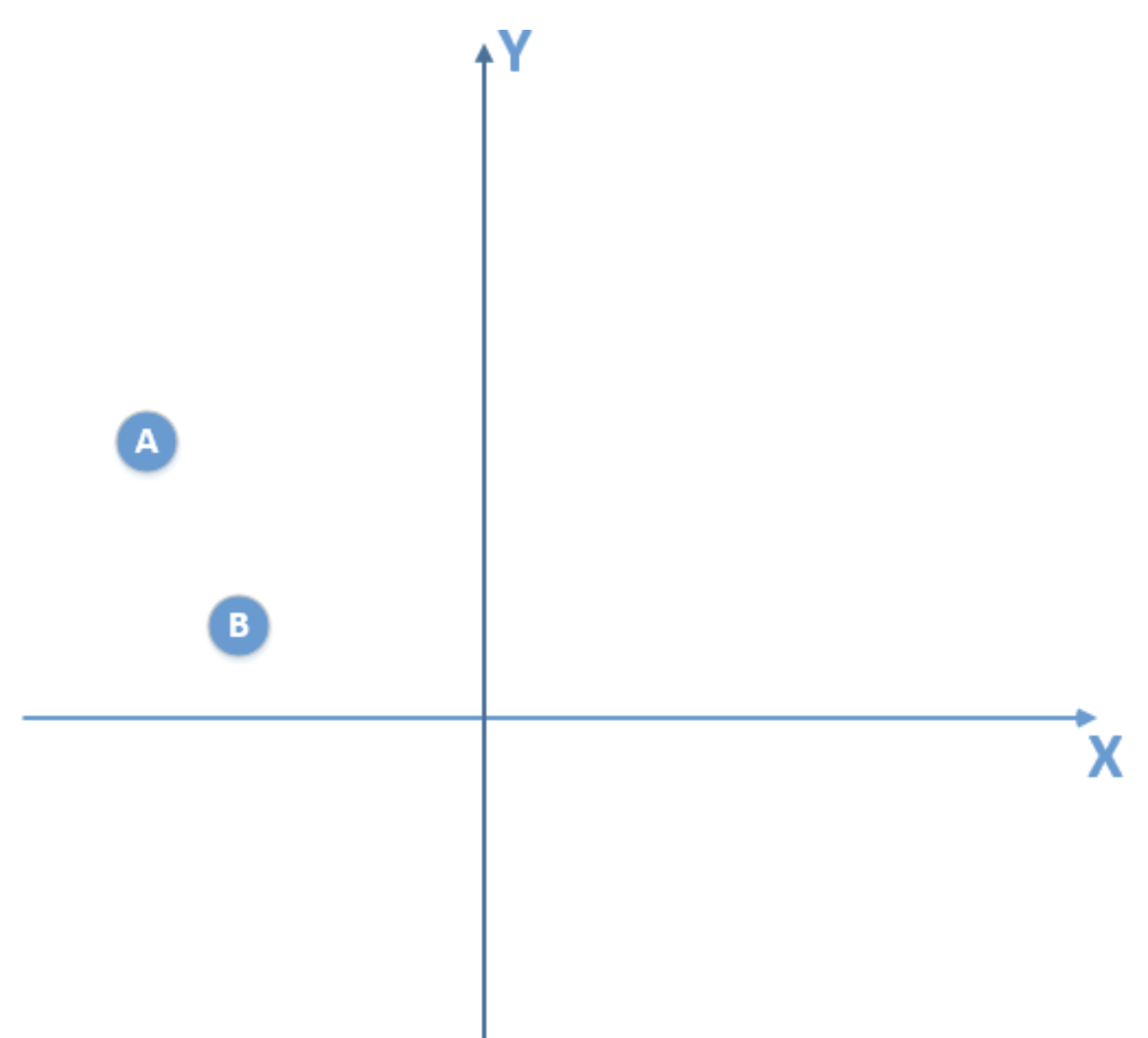
那么由这个训练数据,我得到的模型是一个线性模型,通过训练较多的次数,我可以得到在训练数据使得损失函数为0的线性模型,拿这个模型我去泛化真实的总体分布数据(实际上是满足二次函数模型),很显然,泛化能力是非常差的,也就出现了过拟合现象。
(2) 数据有噪声
所有的机器学习过程都是一个search假设空间的过程!我们是在模型参数空间搜索一组参数,使得我们的损失函数最小,也就是不断的接近我们的真实假设模型,而真实模型只有知道了所有的数据分布,才能得到。
往往我们的模型是在训练数据有限的情况下,找出使损失函数最小的最优模型,然后将该模型泛化于所有数据的其它部分。这是机器学习的本质。
现在假设真实模型的所有数据的分布如下: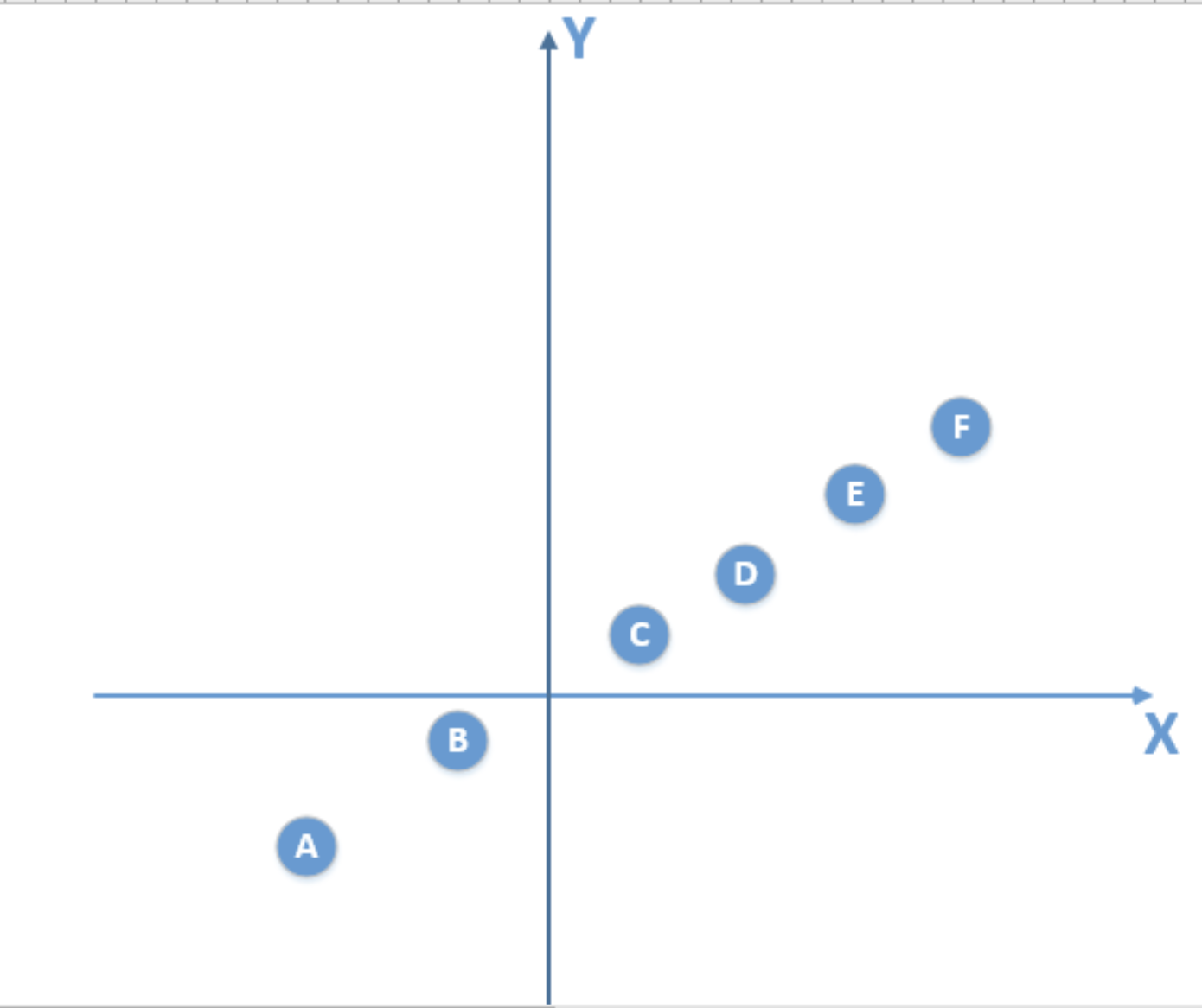
要根据已知的部分数据拟合上述模型,假设已知数据(包含噪声)如下: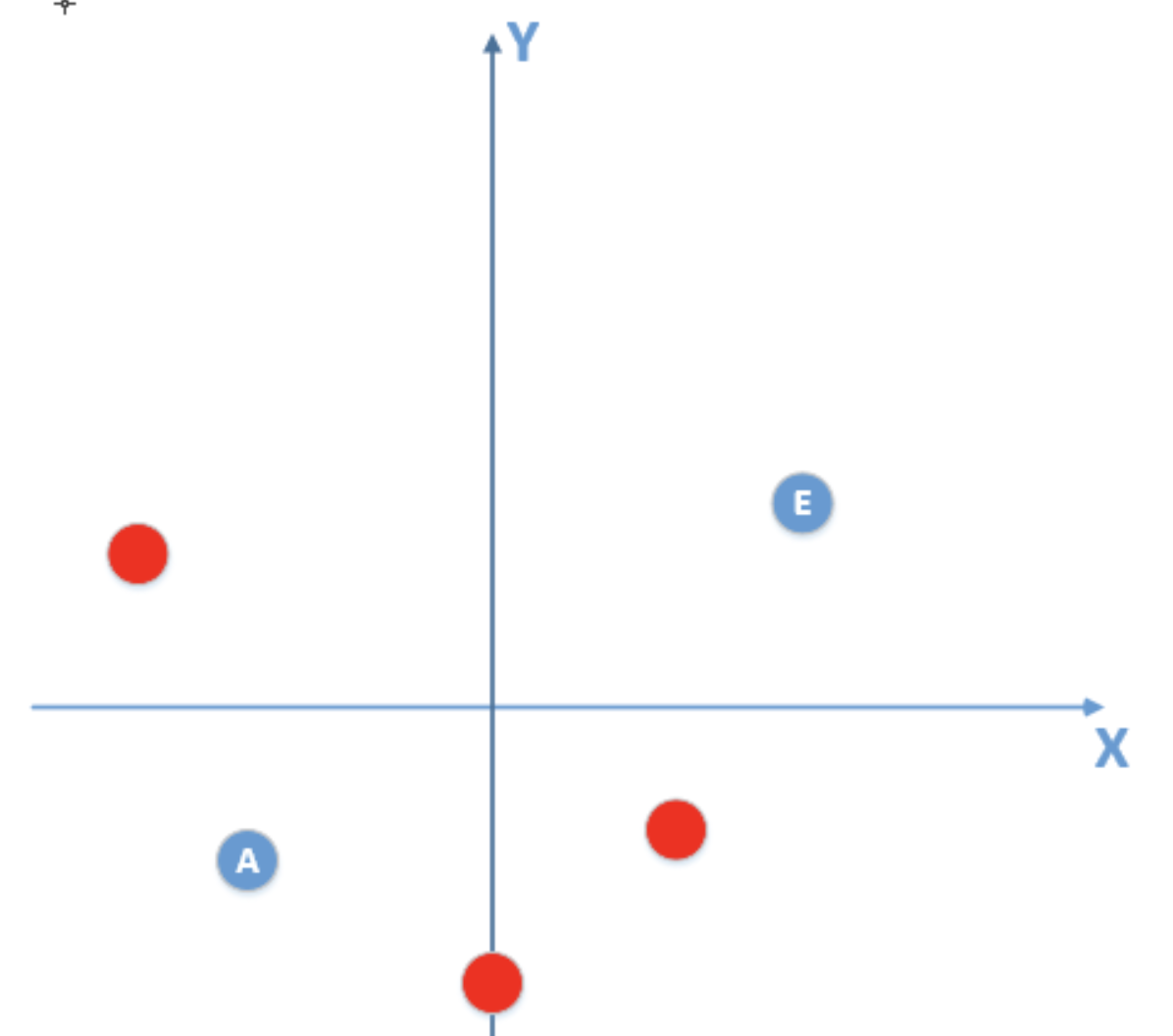
显然由这些包含噪声的数据拟合出的模型在真实数据中的泛化性极差,尽管可以通过大量训练在训练集中得到很高的准确率,但在测试集上准确率必定很低。
(3) 模型太复杂或训练过度
机器学习模型的能力一般远远高于问题复杂度,也就是说,机器学习算法有「拟合出正确规则的前提下,进一步拟合噪声」的能力。这一点可以和原因(2)结合。
3. 避免过拟合的方法
(1) 数据层面
- 从数据源头获取更多数据- 数据清洗,清除异常数据- 数据增强(Data Augmentation)
(2) 模型层面
- **减少网络层数、神经元个数,限制模型拟合能力**- **Dropout**
每次随机忽略隐藏层的某些节点,减弱模型拟合能力;同时,我们相当于用训练数据训练了 (H:隐藏层节点总数)个模型,所以这也类似bagging的做法。
(H:隐藏层节点总数)个模型,所以这也类似bagging的做法。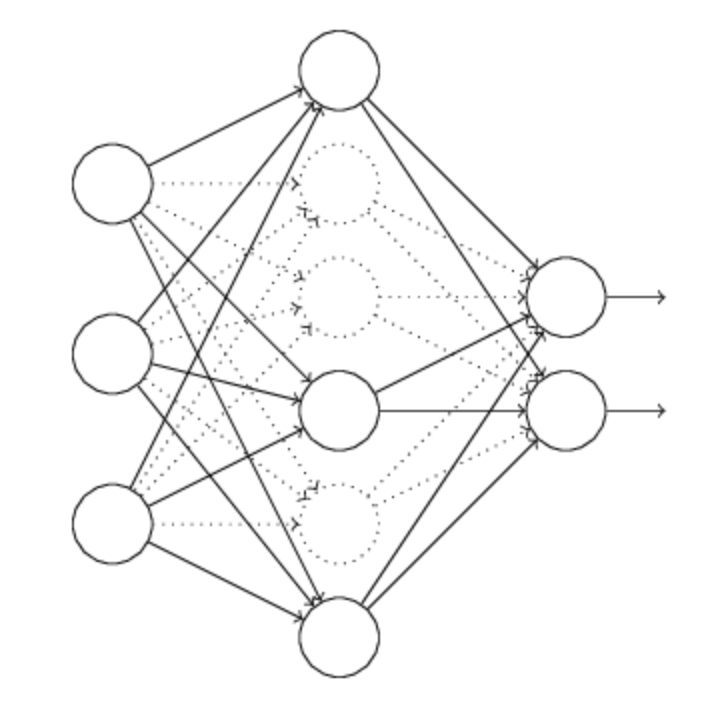
- **Early Stopping:**
对于每个神经元而言,其激活函数在不同区间的性能是不同的:
当网络权值较小时,神经元的激活函数工作在线性区(权值很小,相乘后将要输入激活函数的值接近0,在上图中的线性区域),此时神经元的拟合能力较弱(类似线性神经元)。
有了上述共识之后,我们就可以解释为什么限制训练时间(early stopping)有用:因为我们在初始化网络的时候一般都是初始为较小的权值。随着训练进行,网络权值(绝对值)越来越大,越来越多的神经元进入非线性区,模型的拟合能力越来越强。利用early stopping,在合适的时间提前停止训练,就可以避免更多的神经元进入非线性区域,限制网络的拟合能力,防止过拟合。
- **正则化**
将权值加入损失函数中,限制权值(绝对值)变大,效果同上,让更多神经元处于线性区,减弱模型拟合能力。
(3) 增加噪声
在输入中加高斯噪声,会在输出中生成  的干扰项。训练时,减小误差,同时也会对噪声产生的干扰项进行惩罚,达到减小权值的平方的目的,达到与 L2 regularization 类似的效果(对比公式)。
的干扰项。训练时,减小误差,同时也会对噪声产生的干扰项进行惩罚,达到减小权值的平方的目的,达到与 L2 regularization 类似的效果(对比公式)。

若有收获,就点个赞吧
0 人点赞
