一、vue方面
1.生命周期

2.父子组件通信
3.computed的原理
components有缓存,主要用来计算,更新的结果和更新前的值有关系
watch没有缓存,主要用来监听
4.slot插槽
就是在对已经封装完的组件中插入自己想要定义的不同组件。就是封装的组件中插入子组件,而子组件可以根据自己需求去定义。而slot插槽有三种不同类型的插槽,分别为匿名插槽、具名插槽、作用域插槽。
- 具名字插槽
其实就是slot组件上多一个name属性
以及template模板上多了一个v-slot
- 匿名插槽
实际上是name为default的插槽,然后template上面的v-slot省略
- 作用域插槽
知道了匿名插槽和具名插槽是远远不够!
因为这两种插槽仅仅只能能把Dom插入到封装好的组件中,
而不能获取组件中的数据,这样有时候是满足不了我们的需求的。
如果想获取组件的数据,那么还是得靠作用域插槽!
组件中使用 :data=”xx”的形式,xx可以是任何类型,模板中使用 slot-scope=”childData” childData.xx获取组件中的数据
v-slot指令可以用#代替
5.Vuex的使用
6.路由传参
7.双向绑定的原理
- vue2.0
vue2.0使用据变化更新视图,视图变化更新数据。 将data中的js对象做遍历,利用Object.defineProperty将data中的数据全部转换成getter/setter,每个组件都对应一个Watcher实例,收集数据中的依赖,当数据发生改变触发setter时,会通知对应的组件,组件通过虚拟DOMdiff算法再做改变,如官网的流程图所示: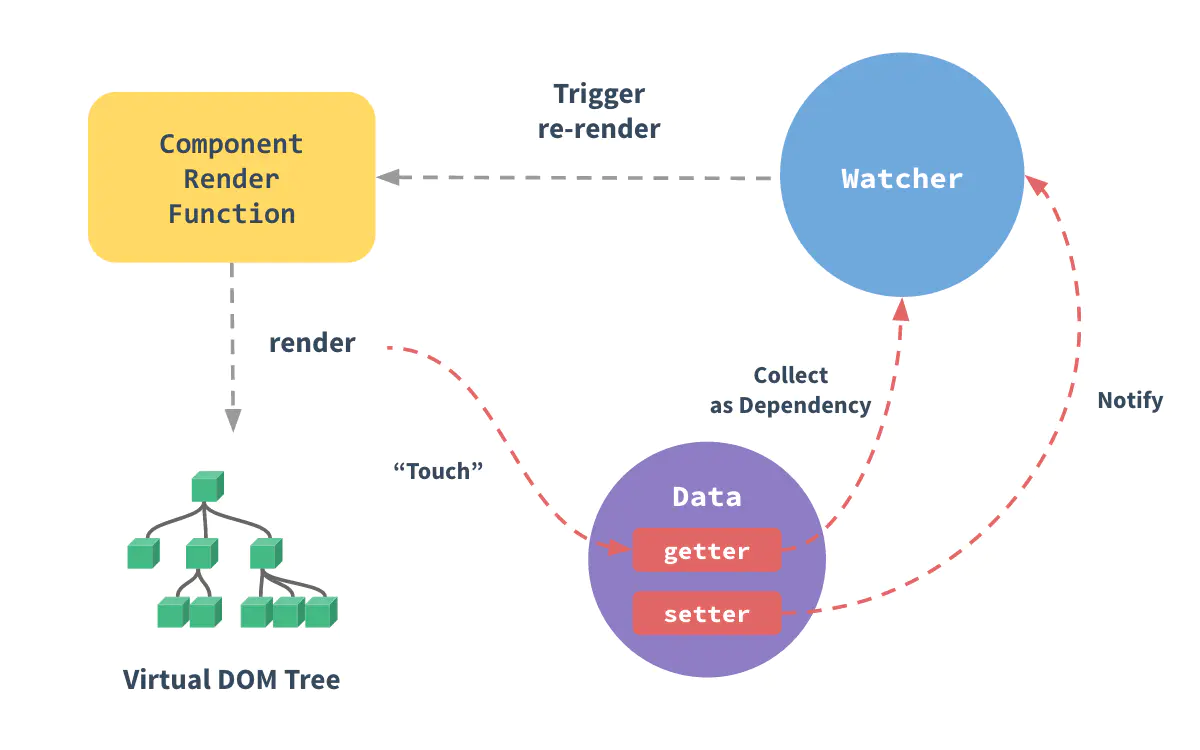
Object.defineProperty(obj, 'name', {get() {return document.getElementById('app').innerHTML},set(val) {console.log('name发生了变化')return document.getElementById('app').innerHTML = val}})
- vue3.0
二、系统设计方面
1.后台管理的权限实现
2.项目中使用的构建工具
3.工作中遇到什么问题
- 人影指挥中特别着急的时间
- 安阳防灾中气象局人员的沟通
- 安全射界中的出图分辨率问题
- 威盾中 预警提醒时段
- 威顿中生成word文档
三、小程序方面
1.小程序生命周期

四、前端工程化方面
五、浏览器对象方面
1.cookie,localstorage,sessionStorage
六、原生js方面
1.闭包
所谓的闭包就是为了能够另一个函数访问一个函数作用域中的变量的书写形式
2.面向对象
3.数组的常用API和操作
4.对象的常用API和操作
5. 回流和重绘
回流和重绘可以说是每一个web开发者都经常听到的两个词语,我也不例外,可是我之前一直不是很清楚这两步具体做了什么事情。最近由于部门内部要做分享,所以对其进行了一些研究,看了一些博客和书籍,整理了一些内容并且结合一些例子,写了这篇文章,希望可以帮助到大家。
浏览器的渲染过程
本文先从浏览器的渲染过程来从头到尾的讲解一下回流重绘,如果大家想直接看如何减少回流和重绘,可以跳到后面。(这个渲染过程来自MDN)
从上面这个图上,我们可以看到,浏览器渲染过程如下:
- 解析HTML,生成DOM树,解析CSS,生成CSSOM树
- 将DOM树和CSSOM树结合,生成渲染树(Render Tree)
- Layout(回流):根据生成的渲染树,进行回流(Layout),得到节点的几何信息(位置,大小)
- Painting(重绘):根据渲染树以及回流得到的几何信息,得到节点的绝对像素
- Display:将像素发送给GPU,展示在页面上。(这一步其实还有很多内容,比如会在GPU将多个合成层合并为同一个层,并展示在页面中。而css3硬件加速的原理则是新建合成层,这里我们不展开,之后有机会会写一篇博客)
渲染过程看起来很简单,让我们来具体了解下每一步具体做了什么。
生成渲染树
为了构建渲染树,浏览器主要完成了以下工作:
- 从DOM树的根节点开始遍历每个可见节点。
- 对于每个可见的节点,找到CSSOM树中对应的规则,并应用它们。
- 根据每个可见节点以及其对应的样式,组合生成渲染树。
第一步中,既然说到了要遍历可见的节点,那么我们得先知道,什么节点是不可见的。不可见的节点包括:
- 一些不会渲染输出的节点,比如script、meta、link等。
- 一些通过css进行隐藏的节点。比如display:none。注意,利用visibility和opacity隐藏的节点,还是会显示在渲染树上的。只有display:none的节点才不会显示在渲染树上。
注意:渲染树只包含可见的节点
回流
前面我们通过构造渲染树,我们将可见DOM节点以及它对应的样式结合起来,可是我们还需要计算它们在设备视口(viewport)内的确切位置和大小,这个计算的阶段就是回流。
为了弄清每个对象在网站上的确切大小和位置,浏览器从渲染树的根节点开始遍历,我们可以以下面这个实例来表示:
<!DOCTYPE html><html><head><meta name="viewport" content="width=device-width,initial-scale=1"><title>Critial Path: Hello world!</title></head><body><div style="width: 50%"><div style="width: 50%">Hello world!</div></div></body></html>
我们可以看到,第一个div将节点的显示尺寸设置为视口宽度的50%,第二个div将其尺寸设置为父节点的50%。而在回流这个阶段,我们就需要根据视口具体的宽度,将其转为实际的像素值。(如下图)
重绘
最终,我们通过构造渲染树和回流阶段,我们知道了哪些节点是可见的,以及可见节点的样式和具体的几何信息(位置、大小),那么我们就可以将渲染树的每个节点都转换为屏幕上的实际像素,这个阶段就叫做重绘节点。
既然知道了浏览器的渲染过程后,我们就来探讨下,何时会发生回流重绘。
何时发生回流重绘
我们前面知道了,回流这一阶段主要是计算节点的位置和几何信息,那么当页面布局和几何信息发生变化的时候,就需要回流。比如以下情况:
- 添加或删除可见的DOM元素
- 元素的位置发生变化
- 元素的尺寸发生变化(包括外边距、内边框、边框大小、高度和宽度等)
- 内容发生变化,比如文本变化或图片被另一个不同尺寸的图片所替代。
- 页面一开始渲染的时候(这肯定避免不了)
- 浏览器的窗口尺寸变化(因为回流是根据视口的大小来计算元素的位置和大小的)
注意:回流一定会触发重绘,而重绘不一定会回流
根据改变的范围和程度,渲染树中或大或小的部分需要重新计算,有些改变会触发整个页面的重排,比如,滚动条出现的时候或者修改了根节点。
浏览器的优化机制
现代的浏览器都是很聪明的,由于每次重排都会造成额外的计算消耗,因此大多数浏览器都会通过队列化修改并批量执行来优化重排过程。浏览器会将修改操作放入到队列里,直到过了一段时间或者操作达到了一个阈值,才清空队列。但是!当你获取布局信息的操作的时候,会强制队列刷新,比如当你访问以下属性或者使用以下方法:
- offsetTop、offsetLeft、offsetWidth、offsetHeight
- scrollTop、scrollLeft、scrollWidth、scrollHeight
- clientTop、clientLeft、clientWidth、clientHeight
- getComputedStyle()
- getBoundingClientRect
- 具体可以访问这个网站:https://gist.github.com/pauli…
以上属性和方法都需要返回最新的布局信息,因此浏览器不得不清空队列,触发回流重绘来返回正确的值。因此,我们在修改样式的时候,最好避免使用上面列出的属性,他们都会刷新渲染队列。如果要使用它们,最好将值缓存起来。
减少回流和重绘
好了,到了我们今天的重头戏,前面说了这么多背景和理论知识,接下来让我们谈谈如何减少回流和重绘。
最小化重绘和重排
由于重绘和重排可能代价比较昂贵,因此最好就是可以减少它的发生次数。为了减少发生次数,我们可以合并多次对DOM和样式的修改,然后一次处理掉。考虑这个例子
const el = document.getElementById('test');el.style.padding = '5px';el.style.borderLeft = '1px';el.style.borderRight = '2px';
例子中,有三个样式属性被修改了,每一个都会影响元素的几何结构,引起回流。当然,大部分现代浏览器都对其做了优化,因此,只会触发一次重排。但是如果在旧版的浏览器或者在上面代码执行的时候,有其他代码访问了布局信息(上文中的会触发回流的布局信息),那么就会导致三次重排。
因此,我们可以合并所有的改变然后依次处理,比如我们可以采取以下的方式:
使用cssText
const el = document.getElementById('test');el.style.cssText += 'border-left: 1px; border-right: 2px; padding: 5px;';
修改CSS的class
const el = document.getElementById('test');el.className += ' active';
批量修改DOM
当我们需要对DOM对一系列修改的时候,可以通过以下步骤减少回流重绘次数:
- 使元素脱离文档流
- 对其进行多次修改
- 将元素带回到文档中。
该过程的第一步和第三步可能会引起回流,但是经过第一步之后,对DOM的所有修改都不会引起回流,因为它已经不在渲染树了。
有三种方式可以让DOM脱离文档流:
- 隐藏元素,应用修改,重新显示
- 使用文档片段(document fragment)在当前DOM之外构建一个子树,再把它拷贝回文档。
- 将原始元素拷贝到一个脱离文档的节点中,修改节点后,再替换原始的元素。
考虑我们要执行一段批量插入节点的代码:
function appendDataToElement(appendToElement, data) {let li;for (let i = 0; i < data.length; i++) {li = document.createElement('li');li.textContent = 'text';appendToElement.appendChild(li);}}const ul = document.getElementById('list');appendDataToElement(ul, data);
如果我们直接这样执行的话,由于每次循环都会插入一个新的节点,会导致浏览器回流一次。
我们可以使用这三种方式进行优化:
隐藏元素,应用修改,重新显示
这个会在展示和隐藏节点的时候,产生两次重绘
function appendDataToElement(appendToElement, data) {let li;for (let i = 0; i < data.length; i++) {li = document.createElement('li');li.textContent = 'text';appendToElement.appendChild(li);}}const ul = document.getElementById('list');ul.style.display = 'none';appendDataToElement(ul, data);ul.style.display = 'block';
使用文档片段(document fragment)在当前DOM之外构建一个子树,再把它拷贝回文档
const ul = document.getElementById('list');const fragment = document.createDocumentFragment();appendDataToElement(fragment, data);ul.appendChild(fragment);
将原始元素拷贝到一个脱离文档的节点中,修改节点后,再替换原始的元素。
const ul = document.getElementById('list');const clone = ul.cloneNode(true);appendDataToElement(clone, data);ul.parentNode.replaceChild(clone, ul);
对于上述那种情况,我写了一个demo来测试修改前和修改后的性能。然而实验结果不是很理想。
原因:原因其实上面也说过了,浏览器会使用队列来储存多次修改,进行优化,所以对这个优化方案,我们其实不用优先考虑。
避免触发同步布局事件
上文我们说过,当我们访问元素的一些属性的时候,会导致浏览器强制清空队列,进行强制同步布局。举个例子,比如说我们想将一个p标签数组的宽度赋值为一个元素的宽度,我们可能写出这样的代码:
function initP() {for (let i = 0; i < paragraphs.length; i++) {paragraphs[i].style.width = box.offsetWidth + 'px';}}
这段代码看上去是没有什么问题,可是其实会造成很大的性能问题。在每次循环的时候,都读取了box的一个offsetWidth属性值,然后利用它来更新p标签的width属性。这就导致了每一次循环的时候,浏览器都必须先使上一次循环中的样式更新操作生效,才能响应本次循环的样式读取操作。每一次循环都会强制浏览器刷新队列。我们可以优化为:
const width = box.offsetWidth;function initP() {for (let i = 0; i < paragraphs.length; i++) {paragraphs[i].style.width = width + 'px';}}
同样,我也写了个demo来比较两者的性能差异。你可以自己点开这个demo体验下。这个对比差距就比较明显。
对于复杂动画效果,使用绝对定位让其脱离文档流
对于复杂动画效果,由于会经常的引起回流重绘,因此,我们可以使用绝对定位,让它脱离文档流。否则会引起父元素以及后续元素频繁的回流。这个我们就直接上个例子。
打开这个例子后,我们可以打开控制台,控制台上会输出当前的帧数(虽然不准)。
从上图中,我们可以看到,帧数一直都没到60。这个时候,只要我们点击一下那个按钮,把这个元素设置为绝对定位,帧数就可以稳定60。
css3硬件加速(GPU加速)
比起考虑如何减少回流重绘,我们更期望的是,根本不要回流重绘。这个时候,css3硬件加速就闪亮登场啦!!
划重点:使用css3硬件加速,可以让transform、opacity、filters这些动画不会引起回流重绘 。但是对于动画的其它属性,比如background-color这些,还是会引起回流重绘的,不过它还是可以提升这些动画的性能。
本篇文章只讨论如何使用,暂不考虑其原理,之后有空会另外开篇文章说明。
如何使用
常见的触发硬件加速的css属性:
- transform
- opacity
- filters
- Will-change
效果
我们可以先看个例子。我通过使用chrome的Performance捕获了一段时间的回流重绘情况,实际结果如下图:
从图中我们可以看出,在动画进行的时候,没有发生任何的回流重绘。如果感兴趣你也可以自己做下实验。
重点
- 使用css3硬件加速,可以让transform、opacity、filters这些动画不会引起回流重绘
- 对于动画的其它属性,比如background-color这些,还是会引起回流重绘的,不过它还是可以提升这些动画的性能。
css3硬件加速的坑
- 如果你为太多元素使用css3硬件加速,会导致内存占用较大,会有性能问题。
在GPU渲染字体会导致抗锯齿无效。这是因为GPU和CPU的算法不同。因此如果你不在动画结束的时候关闭硬件加速,会产生字体模糊。
6.赋值深复制浅复制
赋值(Copy)
赋值是将某一数值或对象赋给某个变量的过程,分两种情况:基本数据类型:赋值,赋值后两个变量互不影响
- 引用数据类型: 赋址,两个变量指向同一个地址,同一个对象,相互之间有影响
对基本数据类型的赋值,两个变量相互不影响:
var a = 1;var b = a;a = 2;console.log(a); // 2console.log(b); // 1复制代码
对引用数据类型进行赋址操作,两个变量指向同一个对象,改变变量a的值会影响变量b的值,哪怕改变的只是对象a中的基础数据类型:
var a = {name: 'Jane',book: {name: 'Vue.js',price: 50}};var b = a;b.name = 'hahaha';b.book.price = 52;console.log(a); // { name: 'hahaha', book: { name: 'Vue.js', price: 52 } }console.log(b); // { name: 'hahaha', book: { name: 'Vue.js', price: 52 } }复制代码
通常开发中我们不希望出现这种相互影响的情况,所以需要浅拷贝或者深拷贝。
浅拷贝(Shallow Copy)
什么是浅拷贝
新建一个对象,这个对象有原始对象属性值的一份精确拷贝。如果属性是基本数据类型,拷贝的是基本数据类型的值;如果属性是引用类型,拷贝的是内存地址,所以如果一个对象改变了这个地址,就会影响到另外一个对象。 图中,
图中,SourceObject是原始对象,有基本数据类型field1和引用数据类型refObj。浅拷贝之后,field1和field2是不同属性,互不影响。refObj是同一个对象,改变之后会影响另一个对象。
简单地说,浅拷贝只解决了第一层的问题,即第一层的基本数据类型和引用类型数据的引用地址。
浅拷贝的应用场景
- Object.assign()
Object.assign()把所有可枚举属性从一个或多个对象复制到目标对象,返回目标对象。
var a = {name: 'Jane',book: {name: 'Vue.js',price: 50}};var b = Object.assign({}, a);b.name = 'hahaha';b.book.price = 52;console.log(a); // { name: 'Jane', book: { name: 'Vue.js', price: 52 } }console.log(b); // { name: 'hahaha', book: { name: 'Vue.js', price: 52 } }复制代码
上面的代码可以看出,基本数据类型的属性name的值没有改变,而引用类型的属性book的值改变就会影响到另一个对象。
展开语法 Spread
var a = {name: 'Jane',book: {name: 'Vue.js',price: 50}};var b = {...a};b.name = 'hahaha';b.book.price = 52;console.log(a); // { name: 'Jane', book: { name: 'Vue.js', price: 52 } }console.log(b); // { name: 'hahaha', book: { name: 'Vue.js', price: 52 } }复制代码
效果跟
Object.assign()一样。Array.prototype.slice()
slice()方法返回一个新的数组对象,这个对象是由begin和end(不包括end)决定的原数组的浅拷贝。原数组不会被改变。
var a = [0, '1', [2, 3]];var b = a.slice(1);console.log(b); // ['1', [2, 3]]a[1] = '99';a[2][0] = 4;console.log(a); // [0, '99', [4, 3]]console.log(b); // ['1', [4, 3]]复制代码
从上面的代码可以看出,a[1]改变之后b[0]并没有改变,a[2][0]改变之后相应的b[1][0]跟着改变了。说明slice()是浅拷贝,相应的还有concat等。
深拷贝(Deep Copy)
什么是深拷贝
深拷贝会拷贝所有的属性,并拷贝属性指向的动态分配的内存。当对象和它所引用的对象一起拷贝时即发生深拷贝。深拷贝相较于浅拷贝速度慢并且花销更大。深拷贝的两个对象互不影响。
深拷贝的使用场景JSON.parse(JSON.stringify(object))
var a = {name: 'Jane',book: {name: 'Vue.js',price: 50}};var b = JSON.parse(JSON.stringify(a));b.name = 'hahaha';b.book.price = 52;console.log(a); // { name: 'Jane', book: { name: 'Vue.js', price: 50 } }console.log(b); // { name: 'hahaha', book: { name: 'Vue.js', price: 52 } }复制代码
深拷贝之后,两个对象互不影响。
看看深拷贝数组:
var a = [0, '1', [2, 3]];var b = JSON.parse(JSON.stringify(a));console.log(b); // [0, '1', [2, 3]]a[1] = '99';a[2][0] = 4;console.log(a); // [0, '99', [4, 3]]console.log(b); // [0, '1', [2, 3]]复制代码
深拷贝数组,两个数组也互不影响。
JSON.parse(JSON.stringify(object))存在的问题
- 会忽略
undefined - 会忽略
symbol - 不能序列化函数
- 不能解决循环引用对象
上面的代码说明不能正确处理var obj = {name: 'Jane',a: undefined,b: Symbol('Jane'),c: function() {}}console.log(obj);// {// name: 'Jane',// a: undefined,// b: Symbol(Jane),// c: ƒ ()// }var b = JSON.parse(JSON.stringify(obj));console.log(b);// {name: 'Jane'}复制代码
undefined、symbol和函数。 下面看看循环引用对象的情况:
执行上面的代码会报错:var obj = {a: 1,b: {c: 2,d: 3}}obj.a = obj.b;obj.b.c = obj.a;var b = JSON.parse(JSON.stringify(obj));复制代码
 深拷贝除了
深拷贝除了JSON.parse(JSON.stringify(object)),还有jQuery.extend()和lodash.cloneDeep(),后续文章研究。7.隐式转换
```javascript var a = {}; if (a) { console.log(‘为真’); } else { console.log(‘为假’); } console.log(‘a==true:’, a == true); console.log(‘a==false:’, a == false); console.log(‘!a:’, !a); console.log(‘a=={}:’, a == {}); console.log(‘!a=={}:’, !a == {}); console.log(‘a==0:’, a == 0); console.log(‘a==1:’, a == 1); console.log(‘===================================================’); var b = []; if (b) { console.log(‘为真’); } else { console.log(‘为假’); } console.log(‘b==true:’, b == true); console.log(‘b==false:’, b == false); console.log(‘!b:’, !b); console.log(‘b=={}:’, b == []); console.log(‘!b=={}:’, !b == []); console.log(‘b==0:’, b == 0); console.log(‘b==1:’, b == 1);

七、前端工程化
1.webpack原理
八、移动端
1.移动端适配

若有收获,就点个赞吧
0 人点赞
