- 1.
all:布尔全等判断 - 2.
allEqual:检查数组各项相等 - 3.
approximatelyEqual:约等于 - 4.
arrayToCSV:数组转CSV格式(带空格的字符串) - 6.
average:平均数 - 7.
averageBy:数组对象属性平均数 - 8.
bifurcate:拆分断言后的数组 - 9.
castArray:其它类型转数组 - 10.
compact:去除数组中的无效/无用值 - 11.
countOccurrences:检测数值出现次数 - 12.
deepFlatten:递归扁平化数组 - 13.
difference:寻找差异(并返回第一个数组独有的) - 14.
differenceBy:先执行再寻找差异 - 15.
dropWhile:删除不符合条件的值 - 16.
flatten:指定深度扁平化数组 - 17.
indexOfAll:返回数组中某值的所有索引 - 18.
intersection:两数组的交集 - 19.
intersectionWith:两数组都符合条件的交集 - 20.
intersectionWith:先比较后返回交集 - 21.
minN:返回指定长度的升序数组 - 22.
negate:根据条件反向筛选 - 23.
randomIntArrayInRange:生成两数之间指定长度的随机数组 - 24.
sample:在指定数组中获取随机数 - 25.
sampleSize:在指定数组中获取指定长度的随机数 - 26.
shuffle:“洗牌” 数组 - 27.
nest:根据parent_id生成树结构(阿里一面真题) - 28.数组去重的12种方法
- 29.找到最接近的数
- 30.扁平化
1. all:布尔全等判断
const all = (arr, fn = Boolean) => arr.every(fn);all([4, 2, 3], x => x > 1); // trueall([1, 2, 3]); // true
2. allEqual:检查数组各项相等
const allEqual = arr => arr.every(val => val === arr[0]);allEqual([1, 2, 3, 4, 5, 6]); // falseallEqual([1, 1, 1, 1]); // true
3. approximatelyEqual:约等于
const approximatelyEqual = (v1, v2, epsilon = 0.001) => Math.abs(v1 - v2) < epsilon;approximatelyEqual(Math.PI / 2.0, 1.5708); // true
4. arrayToCSV:数组转CSV格式(带空格的字符串)
const arrayToCSV = (arr, delimiter = ',') =>arr.map(v => v.map(x => `"${x}"`).join(delimiter)).join('\n');arrayToCSV([['a', 'b'], ['c', 'd']]); // '"a","b"\n"c","d"'arrayToCSV([['a', 'b'], ['c', 'd']], ';'); // '"a";"b"\n"c";"d"'
6. average:平均数
const average = (...nums) => nums.reduce((acc, val) => acc + val, 0) / nums.length;average(...[1, 2, 3]); // 2average(1, 2, 3); // 2
7. averageBy:数组对象属性平均数
此代码段将获取数组对象属性的平均值
1. const averageBy = (arr, fn) =>2. arr.map(typeof fn === 'function' ? fn : val => val[fn]).reduce((acc, val) => acc + val, 0) /3. arr.length;4.5. averageBy([{ n: 4 }, { n: 2 }, { n: 8 }, { n: 6 }], o => o.n); // 56. averageBy([{ n: 4 }, { n: 2 }, { n: 8 }, { n: 6 }], 'n'); // 57. 复制代码
8. bifurcate:拆分断言后的数组
可以根据每个元素返回的值,使用reduce()和push() 将元素添加到第二次参数fn中 。
1. const bifurcate = (arr, filter) =>2. arr.reduce((acc, val, i) => (acc[filter[i] ? 0 : 1].push(val), acc), [[], []]);3. bifurcate(['beep', 'boop', 'foo', 'bar'], [true, true, false, true]);4. // [ ['beep', 'boop', 'bar'], ['foo'] ]5. 复制代码
9. castArray:其它类型转数组
1. const castArray = val => (Array.isArray(val) ? val : [val]);2.3. castArray('foo'); // ['foo']4. castArray([1]); // [1]5. castArray(1); // [1]6. 复制代码
10. compact:去除数组中的无效/无用值
const compact = arr => arr.filter(Boolean);compact([0, 1, false, 2, '', 3, 'a', 'e' * 23, NaN, 's', 34]);// [ 1, 2, 3, 'a', 's', 34 ]
11. countOccurrences:检测数值出现次数
const countOccurrences = (arr, val) => arr.reduce((a, v) => (v === val ? a + 1 : a), 0);countOccurrences([1, 1, 2, 1, 2, 3], 1); // 3
12. deepFlatten:递归扁平化数组
const deepFlatten = arr => [].concat(...arr.map(v => (Array.isArray(v) ? deepFlatten(v) : v)));deepFlatten([1, [2], [[3], 4], 5]); // [1,2,3,4,5]
13. difference:寻找差异(并返回第一个数组独有的)
此代码段查找两个数组之间的差异,并返回第一个数组独有的。
const difference = (a, b) => {const s = new Set(b);return a.filter(x => !s.has(x));};difference([1, 2, 3], [1, 2, 4]); // [3]
14. differenceBy:先执行再寻找差异
在将给定函数应用于两个列表的每个元素之后,此方法返回两个数组之间的差异。
1. const differenceBy = (a, b, fn) => {2. const s = new Set(b.map(fn));3. return a.filter(x => !s.has(fn(x)));4. };5.6. differenceBy([2.1, 1.2], [2.3, 3.4], Math.floor); // [1.2]7. differenceBy([{ x: 2 }, { x: 1 }], [{ x: 1 }], v => v.x); // [ { x: 2 } ]8. 复制代码
15. dropWhile:删除不符合条件的值
此代码段从数组顶部开始删除元素,直到传递的函数返回为true。
const dropWhile = (arr, func) => {while (arr.length > 0 && !func(arr[0])) arr = arr.slice(1);return arr;};dropWhile([1, 2, 3, 4], n => n >= 3); // [3,4]
16. flatten:指定深度扁平化数组
此代码段第二参数可指定深度。
const flatten = (arr, depth = 1) =>arr.reduce((a, v) => a.concat(depth > 1 && Array.isArray(v) ? flatten(v, depth - 1) : v), []);flatten([1, [2], 3, 4]); // [1, 2, 3, 4]flatten([1, [2, [3, [4, 5], 6], 7], 8], 2); // [1, 2, 3, [4, 5], 6, 7, 8]
17. indexOfAll:返回数组中某值的所有索引
此代码段可用于获取数组中某个值的所有索引,如果此值中未包含该值,则返回一个空数组。
1. const indexOfAll = (arr, val) => arr.reduce((acc, el, i) => (el === val ? [...acc, i] : acc), []);2.3. indexOfAll([1, 2, 3, 1, 2, 3], 1); // [0,3]4. indexOfAll([1, 2, 3], 4); // []5. 复制代码
18. intersection:两数组的交集
1.2. const intersection = (a, b) => {3. const s = new Set(b);4. return a.filter(x => s.has(x));5. };6.7. intersection([1, 2, 3], [4, 3, 2]); // [2, 3]8. 复制代码
19. intersectionWith:两数组都符合条件的交集
此片段可用于在对两个数组的每个元素执行了函数之后,返回两个数组中存在的元素列表。
1.2. const intersectionBy = (a, b, fn) => {3. const s = new Set(b.map(fn));4. return a.filter(x => s.has(fn(x)));5. };6.7. intersectionBy([2.1, 1.2], [2.3, 3.4], Math.floor); // [2.1]8. 复制代码
20. intersectionWith:先比较后返回交集
1. const intersectionWith = (a, b, comp) => a.filter(x => b.findIndex(y => comp(x, y)) !== -1);2.3. intersectionWith([1, 1.2, 1.5, 3, 0], [1.9, 3, 0, 3.9], (a, b) => Math.round(a) === Math.round(b)); // [1.5, 3, 0]4. 复制代码
21. minN:返回指定长度的升序数组
const minN = (arr, n = 1) => [...arr].sort((a, b) => a - b).slice(0, n);minN([1, 2, 3]); // [1]minN([1, 2, 3], 2); // [1,2]
22. negate:根据条件反向筛选
const negate = func => (...args) => !func(...args);[1, 2, 3, 4, 5, 6].filter(negate(n => n % 2 === 0)); // [ 1, 3, 5 ]
23. randomIntArrayInRange:生成两数之间指定长度的随机数组
const randomIntArrayInRange = (min, max, n = 1) =>Array.from({ length: n }, () => Math.floor(Math.random() * (max - min + 1)) + min);randomIntArrayInRange(12, 35, 10); // [ 34, 14, 27, 17, 30, 27, 20, 26, 21, 14 ]
24. sample:在指定数组中获取随机数
const sample = arr => arr[Math.floor(Math.random() * arr.length)];sample([3, 7, 9, 11]); // 9
25. sampleSize:在指定数组中获取指定长度的随机数
此代码段可用于从数组中获取指定长度的随机数,直至穷尽数组。 使用**Fisher-Yates**算法对数组中的元素进行随机选择。
const sampleSize = ([...arr], n = 1) => {let m = arr.length;while (m) {const i = Math.floor(Math.random() * m--);[arr[m], arr[i]] = [arr[i], arr[m]];}return arr.slice(0, n);};sampleSize([1, 2, 3], 2); // [3,1]sampleSize([1, 2, 3], 4); // [2,3,1]
26. shuffle:“洗牌” 数组
此代码段使用Fisher-Yates算法随机排序数组的元素。
const shuffle = ([...arr]) => {let m = arr.length;while (m) {const i = Math.floor(Math.random() * m--);[arr[m], arr[i]] = [arr[i], arr[m]];}return arr;};const foo = [1, 2, 3];shuffle(foo); // [2, 3, 1], foo = [1, 2, 3]
27. nest:根据parent_id生成树结构(阿里一面真题)
根据每项的parent_id,生成具体树形结构的对象。
const nest = (items, id = null, link = 'parent_id') => items.filter(item => item[link] === id).map(item => ({ ...item, children: nest(items, item.id) }));
用法:
const comments = [{ id: 1, parent_id: null },{ id: 2, parent_id: 1 },{ id: 3, parent_id: 1 },{ id: 4, parent_id: 2 },{ id: 5, parent_id: 4 }];const nestedComments = nest(comments); // [{ id: 1, parent_id: null, children: [...] }]
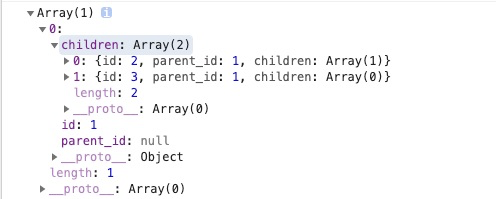
强烈建议去理解这个的实现,因为这是我亲身遇到的阿里一面真题:
28.数组去重的12种方法
数组去重,一般都是在面试的时候才会碰到,一般是要求手写数组去重方法的代码。如果是被提问到,数组去重的方法有哪些?你能答出其中的10种,面试官很有可能对你刮目相看。在真实的项目中碰到的数组去重,一般都是后台去处理,很少让前端处理数组去重。虽然日常项目用到的概率比较低,但还是需要了解一下,以防面试的时候可能回被问到。注:写的匆忙,加上这几天有点忙,还没有非常认真核对过,不过思路是没有问题,可能一些小细节出错而已。数组去重的方法一、利用ES6 Set去重(ES6中最常用)function unique (arr) {return Array.from(new Set(arr))}var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];console.log(unique(arr))//[1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {}, {}]不考虑兼容性,这种去重的方法代码最少。这种方法还无法去掉“{}”空对象,后面的高阶方法会添加去掉重复“{}”的方法。二、利用for嵌套for,然后splice去重(ES5中最常用)function unique(arr){for(var i=0; i<arr.length; i++){for(var j=i+1; j<arr.length; j++){if(arr[i]==arr[j]){ //第一个等同于第二个,splice方法删除第二个arr.splice(j,1);j--;}}}return arr;}var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];console.log(unique(arr))//[1, "true", 15, false, undefined, NaN, NaN, "NaN", "a", {…}, {…}] //NaN和{}没有去重,两个null直接消失了双层循环,外层循环元素,内层循环时比较值。值相同时,则删去这个值。想快速学习更多常用的ES6语法,可以看我之前的文章《学习ES6笔记──工作中常用到的ES6语法》。三、利用indexOf去重function unique(arr) {if (!Array.isArray(arr)) {console.log('type error!')return}var array = [];for (var i = 0; i < arr.length; i++) {if (array .indexOf(arr[i]) === -1) {array .push(arr[i])}}return array;}var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];console.log(unique(arr))// [1, "true", true, 15, false, undefined, null, NaN, NaN, "NaN", 0, "a", {…}, {…}] //NaN、{}没有去重新建一个空的结果数组,for 循环原数组,判断结果数组是否存在当前元素,如果有相同的值则跳过,不相同则push进数组。四、利用sort()function unique(arr) {if (!Array.isArray(arr)) {console.log('type error!')return;}arr = arr.sort()var arrry= [arr[0]];for (var i = 1; i < arr.length; i++) {if (arr[i] !== arr[i-1]) {arrry.push(arr[i]);}}return arrry;}var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];console.log(unique(arr))// [0, 1, 15, "NaN", NaN, NaN, {…}, {…}, "a", false, null, true, "true", undefined] //NaN、{}没有去重利用sort()排序方法,然后根据排序后的结果进行遍历及相邻元素比对。五、利用对象的属性不能相同的特点进行去重(这种数组去重的方法有问题,不建议用,有待改进)function unique(arr) {if (!Array.isArray(arr)) {console.log('type error!')return}var arrry= [];var obj = {};for (var i = 0; i < arr.length; i++) {if (!obj[arr[i]]) {arrry.push(arr[i])obj[arr[i]] = 1} else {obj[arr[i]]++}}return arrry;}var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];console.log(unique(arr))//[1, "true", 15, false, undefined, null, NaN, 0, "a", {…}] //两个true直接去掉了,NaN和{}去重六、利用includesfunction unique(arr) {if (!Array.isArray(arr)) {console.log('type error!')return}var array =[];for(var i = 0; i < arr.length; i++) {if( !array.includes( arr[i]) ) {//includes 检测数组是否有某个值array.push(arr[i]);}}return array}var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];console.log(unique(arr))//[1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {…}, {…}] //{}没有去重七、利用hasOwnPropertyfunction unique(arr) {var obj = {};return arr.filter(function(item, index, arr){return obj.hasOwnProperty(typeof item + item) ? false : (obj[typeof item + item] = true)})}var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];console.log(unique(arr))//[1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {…}] //所有的都去重了利用hasOwnProperty 判断是否存在对象属性八、利用filterfunction unique(arr) {return arr.filter(function(item, index, arr) {//当前元素,在原始数组中的第一个索引==当前索引值,否则返回当前元素return arr.indexOf(item, 0) === index;});}var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];console.log(unique(arr))//[1, "true", true, 15, false, undefined, null, "NaN", 0, "a", {…}, {…}]九、利用递归去重function unique(arr) {var array= arr;var len = array.length;array.sort(function(a,b){ //排序后更加方便去重return a - b;})function loop(index){if(index >= 1){if(array[index] === array[index-1]){array.splice(index,1);}loop(index - 1); //递归loop,然后数组去重}}loop(len-1);return array;}var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];console.log(unique(arr))//[1, "a", "true", true, 15, false, 1, {…}, null, NaN, NaN, "NaN", 0, "a", {…}, undefined]十、利用Map数据结构去重function arrayNonRepeatfy(arr) {let map = new Map();let array = new Array(); // 数组用于返回结果for (let i = 0; i < arr.length; i++) {if(map .has(arr[i])) { // 如果有该key值map .set(arr[i], true);} else {map .set(arr[i], false); // 如果没有该key值array .push(arr[i]);}}return array ;}var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];console.log(unique(arr))//[1, "a", "true", true, 15, false, 1, {…}, null, NaN, NaN, "NaN", 0, "a", {…}, undefined]创建一个空Map数据结构,遍历需要去重的数组,把数组的每一个元素作为key存到Map中。由于Map中不会出现相同的key值,所以最终得到的就是去重后的结果。十一、利用reduce+includesfunction unique(arr){return arr.reduce((prev,cur) => prev.includes(cur) ? prev : [...prev,cur],[]);}var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];console.log(unique(arr));// [1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {…}, {…}]十二、[...new Set(arr)][...new Set(arr)]//代码就是这么少----(其实,严格来说并不算是一种,相对于第一种方法来说只是简化了代码)function distinct(a, b) {return Array.from(new Set([...a, ...b]))}PS:有些文章提到了foreach+indexOf数组去重的方法,个人觉得都是大同小异,所以没有写上去。
29.找到最接近的数
根据一个值,从数组中查找与之最接近的值
首先把这个值插入数组,然后执行排序,接着与之前后两个数进行差值计算,返回与之最接近的值
/*** @description: 从数组中找到最接近的数* @param {Number} val* @param {Array} data* @return {Number} 最接近当前值的结果* @author: wangchaoxu*/function findNearByArr(val, data) {if (!!~data.indexOf(val)) return val;data.push(val);let newArr = data.sort((a, b) => a - b);let pre = newArr[newArr.indexOf(val) - 1];let next = newArr[newArr.indexOf(val) + 1];return val - pre > next - val || val - pre === next - val ? next : pre;}console.log(findNearByArr(1, [0.1,-1,-0.5,5,6,7,9,2]));//0.1
30.扁平化
需求
let ary = [1, [2, [3, [4, 5]]], 6];let str = JSON.stringify(ary);
第0种处理:直接的调用
arr_flat = arr.flat(Infinity);
第一种处理
ary = str.replace(/(\[\]))/g, '').split(',');
第二种处理
str = str.replace(/(\[\]))/g, '');str = '[' + str + ']';ary = JSON.parse(str);
第三种处理:递归处理
let result = [];let fn = function(ary) {for(let i = 0; i < ary.length; i++) }{let item = ary[i];if (Array.isArray(ary[i])){fn(item);} else {result.push(item);}}}
第四种处理:用 reduce 实现数组的 flat 方法
function flatten(ary) {return ary.reduce((pre, cur) => {return pre.concat(Array.isArray(cur) ? flatten(cur) : cur);})}let ary = [1, 2, [3, 4], [5, [6, 7]]]console.log(ary.MyFlat(Infinity))
第五种处理:扩展运算符
while (ary.some(Array.isArray)) {ary = [].concat(...ary);}
第六处理多维 ```javascript const arr1 = [1, 2, [3, 4]]; arr1.flat(); // [1, 2, 3, 4]
const arr2 = [1, 2, [3, 4, [5, 6]]]; arr2.flat(); // [1, 2, 3, 4, [5, 6]]
const arr3 = [1, 2, [3, 4, [5, 6]]]; arr3.flat(2); // [1, 2, 3, 4, 5, 6]
const arr4 = [1, 2, [3, 4, [5, 6, [7, 8, [9, 10]]]]]; arr4.flat(Infinity); // [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
```

若有收获,就点个赞吧
0 人点赞
