1)要使用Fiddler进行抓包,首先需要确保Capture Traffic是开启的(安装后是默认开启的),勾选File->Capture Traffic,也可以直接点击Fiddler界面左下角的图标开启和关闭抓包。
2)所以基本上不需要做什么配置,安装后就可以进行抓包了。那么我们怎么分析抓到的这些数据包呢?如图所示的区域为数据包列表,要分析这些数据包,首先要了解各字段的含义。
#:顺序号,按照抓包的顺序从1递增
Result:HTTP状态码
Protocol:请求使用的协议,如HTTP/HTTPS/FTP等
HOST:请求地址的主机名或域名
URL:请求资源的位置
Body:请求大小
Caching:请求的缓存过期时间或者缓存控制值
Content-Type:请求响应的类型
Process:发送此请求的进程ID
Comments:备注
Custom:自定义值
3)每个Fiddler抓取到的数据包都会在该列表中展示,点击具体的一条数据包可以在右侧菜单点击Insepector查看详细内容。主要分为请求(即客户端发出的数据)和响应(服务器返回的数据)两部分。
4)HTTP Request Header:以百度为例,查看请求百度主页这条数据包的请求数据,从上面的Headers中可以看到如下内容: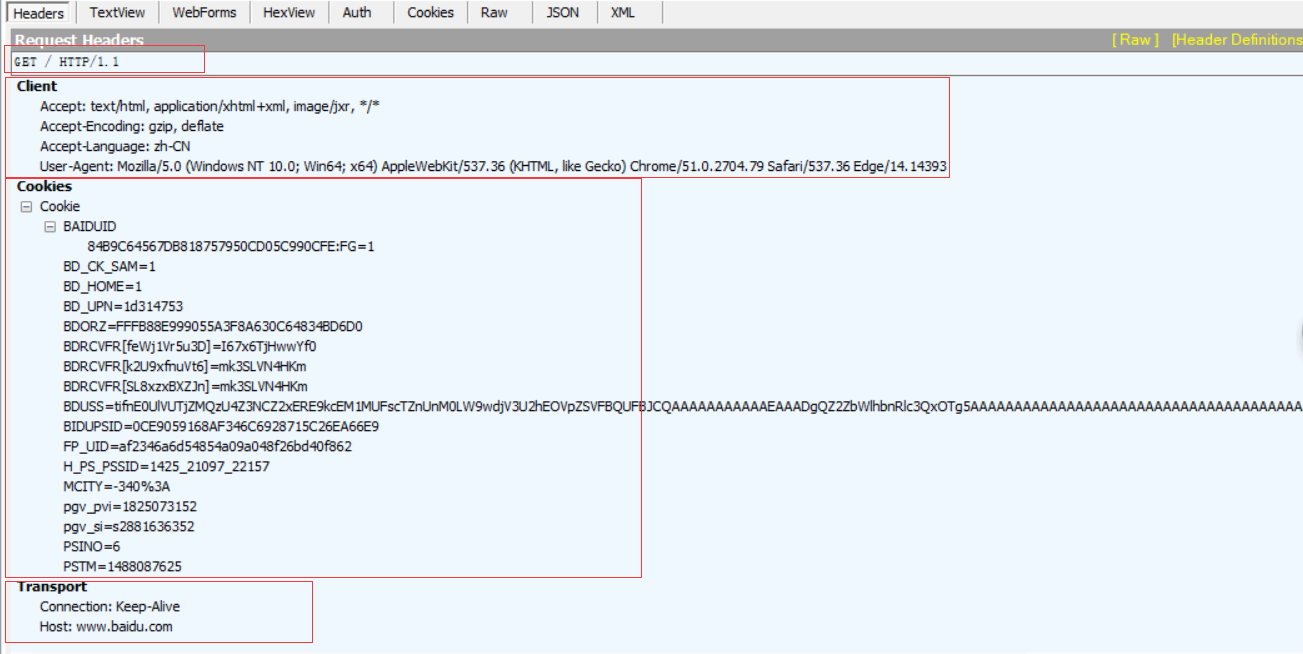
请求方式:GET
协议: HTTP/1.1
Client 头域:
Accept: text/html, application/xhtml+xml, image/jxr, / ————-浏览器端可以接受的媒体类型
Accept-Encoding: gzip, deflate ————-压缩方法
Accept-Language: zh-CN ————-语言类型
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393 ————-客户端使用的操作系统和浏览器的名称和版本
COOKIE头域:将cookie值发送给服务器
Transport 头域:
Connection:当网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接是否关闭。keep-alive表示不会关闭,客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接;close表示关闭,客户端再次访问这个服务器上的网页,需要重新建立连接。
HOST:主机名或域名,若没有指定端口,表示使用默认端口80.
5)HTTP Response Header:继续以百度为例,如图所示:
协议:HTTP/1.1
状态码:200
Cache头域:
Cache-Control: private ————-此响应消息不能被共享缓存处理,对于其他用户的请求无效
Date: Sat, 05 Aug 2017 04:37:43 GMT ————-生成消息的具体时间和日期
Expires: Sat, 05 Aug 2017 04:37:42 GMT ————-浏览器会在指定过期时间内使用本地缓存
Cookie/Login 头域:
Set-Cookie: BDSVRTM=264; path=/ ————-把cookie发送到客户端
Set-Cookie: BD_HOME=1; path=/
Set-Cookie: H_PS_PSSID=1425_21097_22157; path=/; domain=.baidu.com
Entity头域
Content-Length: 202740 ————-正文长度
Content-Type: text/html;charset=utf-8 ————-告知客户端服务器本身响应的对象的类型和字符集
Miscellaneous 头域:
Bdpagetype: 2
Bdqid: 0x99791efd00036253
Bduserid: 2577220064
Server: BWS/1.1 ————-指明HTTP服务器的软件信息
X-Ua-Compatible: IE=Edge,chrome=1
Security头域:
Strict-Transport-Security: max-age=172800 ————-基于安全考虑而需要发送的参数,关于这个参数的解释,请参考:http://www.freebuf.com/articles/web/66827.html
Transport头域:
Connection: Keep-Alive
6)TextView:显示请求或响应的数据。
7)WebForms:请求部分以表单形式显示所有的请求参数和参数值;响应部分与TextView内容是一样的。
8)Auth:显示认证信息,如Authorization
9)Cookies:显示所有cookies
10)Raw:显示Headers和Body数据
11)JSON:若请求或响应数据是json格式,以json形式显示请求或响应内容
12)XML:若请求或响应数据是xml格式,以xml形式显示请求或响应内容
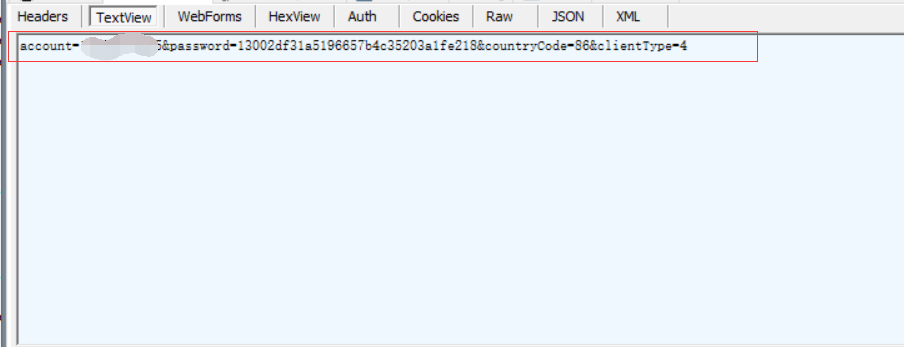
13)上面是以百度主页为例,百度主页采用的是GET请求,在TextView中没有请求body,我们再以无忧行网站登录接口为例,它是一个POST请求,除了请求头外,在TextView中多了请求数据。这也是GET请求和POST请求的一个区别。GET请求是将请求参数放在url中,而POST请求一般是将请求参数放在请求body中。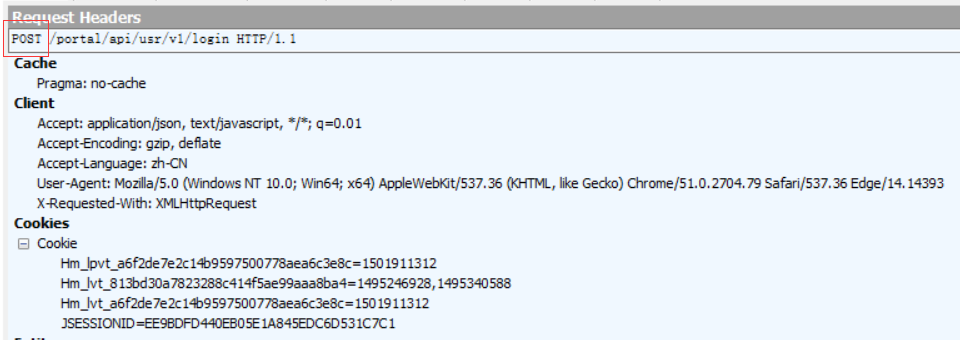
总结:通过Fiddler可以抓取请求和响应参数,通过对参数进行分析,可以定位是前端还是后台问题。例如我们在测试登录接口时,输入了正确的手机号和密码,但前端提示“请输入正确的用户名和密码”;仅仅通过界面提示我们只能描述bug表象,但不能分析出问题原因。假设通过抓包我们发现是由于前端参数名错误或参数值为空,从而导致后台报错。这个时候我们将bug指向前端开发人员,并将参数数据和接口文档中对应的报文数据作为附件上传,是不是可以提高bug的解决效率呢?Fiddler在实际的功能测试中有很大的作用,一方面帮助我们更好的了解某个业务中客户端和服务器端是通过哪些接口进行请求的,从而更好的了解代码逻辑;另一方面,我们还可以通过响应数据判断哪里出现了问题,例如可能服务器程序挂了,导致前端报“服务器故障”,这时我们通过抓包发现响应数据返回502,这时我们可以手动去重启服务或是联系运维重启服务,从而提高问题的解决效率。

若有收获,就点个赞吧
0 人点赞
