Flink 端到端的精确一次需要保证source,transformation,sink的精确一次;
sink如何保证精确一次?需要支持幂等写入或事务写入,Flink的两阶段提交需要事务支持
1.1.1.1 幂等写入(Idempotent Writes)
幂等写入是指:任意多次向一个系统写入数据,只对目标系统产生一次结果影响。
Hbase,Redis和Cassandra这样的KV数据库一般经常用来作为Sink,用以用以实现端到端的Exactly-Once
需要注意的是:并不是一个KV数据库就一定支持幂等写。幂等写对KV对有要求,那就是Key-Value必须是可确定性计算的。例如我设计的Key:
name+curTimestamp,每次执行数据重发时,生成的Key都不相同,会产生多次结果,整个操作不是幂等的。因此,为了追求端到端的Exactly+Once,我们设计业务逻辑时要尽量使用确定性的计算逻辑和数据模型。
1.1.1.2 事务写入(Transactional Writes)
Flink借鉴了数据库中的事务处理技术,同时结合自身的Checkpoint机制来保证Sink只对外部输出产生一次影响。大致的流程如下:
Flink先将待输出的数据保存下来暂时不向外部系统提交,等到Checkpoint结束时,Flink上下游所有算子的数据都是一致的时候,Flink将之前保存的数据全部提交(Commit)到外部系统。换句话说,只有经过Checkpoint确认的数据才向外部系统写入。
如下图所示,如果使用事务写,那只把时间戳3之前的输出提交到外部系统,时间戳3以后的数据(例如时间戳5和8生成的数据)暂时保存下来,等待下次Checkpoint时一起写入到外部系统。这就避免了时间戳5这个数据产生多次结果,多次写入到外部系统。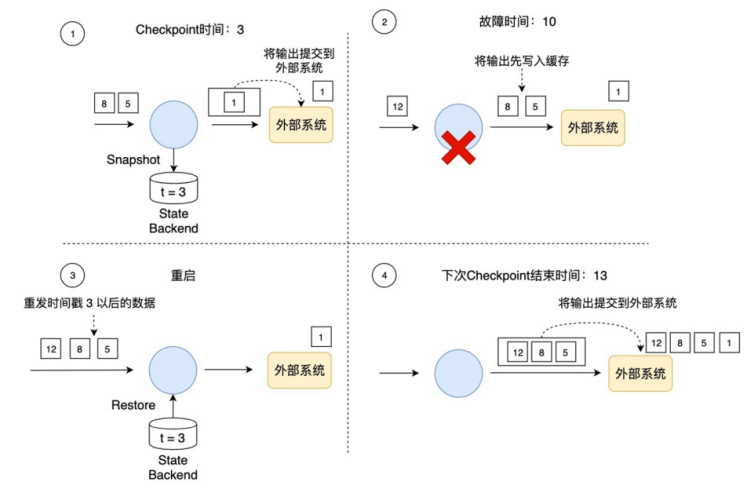
在事务写的具体实现上,Flink目前提供了两种方式:
1.预写日志(Write-Ahead-Log,WAL)
2.两阶段提交(Two-Phase-Commit,2PC)
这两种方式区别主要在于:
1.WAL方式通用性更强,适合几乎所有外部系统,但也不能提供百分百端到端的Exactly-Once,因为WAL预习日志会先写内存,而内存是易失介质。
2.如果外部系统自身就支持事务(比如MySQL、Kafka),可以使用2PC方式,可以提供百分百端到端的Exactly-Once。
事务写的方式能提供端到端的Exactly-Once一致性,它的代价也是非常明显的,就是牺牲了延迟。输出数据不再是实时写入到外部系统,而是分批次地提交。目前来说,没有完美的故障恢复和Exactly-Once保障机制,对于开发者来说,需要在不同需求之间权衡。

若有收获,就点个赞吧
0 人点赞
