ETL工具(sqoop,DataX,Kettle,canal,StreamSets)ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程,是数据仓库的生命线。抽取(Extract)主要是针对各个业务系统及不同服务器的分散数据,充分理解数据定义后,规划需要的数据源及数据定义,制定可操作的数据源,制定增量抽取和缓慢渐变的规则。转换(transform)主要是针对数据仓库建立的模型,通过一系列的转换来实现将数据从业务模型到分析模型,通过ETL工具可视化拖拽操作可以直接使用标准的内置代码片段功能、自定义脚本、函数、存储过程以及其他的扩展方式,实现了各种复杂的转换,并且支持自动分析日志,清楚的监控数据转换的状态并优化分析模型。装载(Load)主要是将经过转换的数据装载到数据仓库里面,可以通过直连数据库的方式来进行数据装载,可以充分体现高效性。在应用的时候可以随时调整数据抽取工作的运行方式,可以灵活的集成到其他管理系统中。
大数据学习路线:
https://juejin.cn/post/6940518611895189541
https://github.com/heibaiying/BigData-Notes/blob/master/notes/%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%AD%A6%E4%B9%A0%E8%B7%AF%E7%BA%BF.md
https://blog.51cto.com/ikeguang/4681980
https://www.bilibili.com/read/cv5213600?spm_id_from=333.788.b_636f6d6d656e74.8
数据迁移工具:
https://www.modb.pro/db/83856
什么是有状态计算,什么是无状态计算?在数据的流处理中他们的区别是什么?一般来说就是计算分为无状态和有状态两种情况。
无状态计算会观察每个独立的事件,并且会在最后一个时间出结果,例如一些报警和监控,一直观察每个事件,当触发警报的事件来临就会触发警告。
有状态的计算就会基于多个事件来输出结果,比如说计算过去一个小时的平均温度等等。
https://www.cnblogs.com/liyuanhong/articles/14518037.html
Hadoop:是一个分布式计算的开源框架
HDFS:是Hadoop的三大核心组件之一
Hive:用户处理存储在HDFS中的数据,hive的意义就是把好写的hive的sql转换为复杂难写的map-reduce程序。
Hbase:是一款基于HDFS的数据库,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等。
HBase:HBase是Hadoop的数据库,一个分布式、可扩展、大数据的存储。
- hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作
- hbase可以认为是hdfs的一个包装。他的本质是数据存储,是个NoSql数据库;hbase部署于hdfs之上,并且克服了hdfs在随机读写方面的缺点。
Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用。
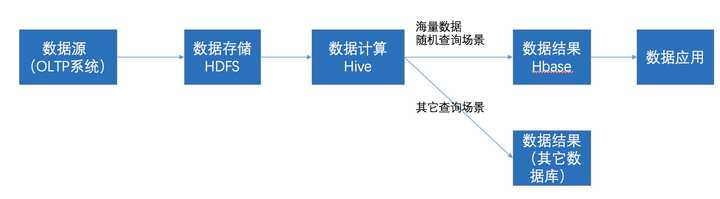
在大数据架构中,Hive和HBase是协作关系,数据流一般如下图:
- 通过ETL工具将数据源抽取到HDFS存储;
- 通过Hive清洗、处理和计算原始数据;
- HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
- 数据应用从HBase查询数据;
分区容错性:
大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区(partition)。 分区容错的意思是,区间通信可能失败。 比如,一台服务器放在中国,另一台服务器放在美国,这就是两个区,它们之间可能无法通信。
CA-单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
CP-满足一致性,分区容错的系统,通常性能不是特别高
AP-满足可用性,分区容错性的系统,通常可能对一致性要求低一些

若有收获,就点个赞吧
0 人点赞
