create database用于创建新的数据库
COMMENT:数据库的注释说明语句
LOCATION:指定数据库在HDFS存储位置, 默认/user/hive/warehouse/dbname.db
WITH DBPROPERTIES:用于指定一些数据库的属性配置。
创建数据库itcast
注意: 如果需要使用location指定路径的时候, 最好指向的是一个新创建的空文件夹。
create database if not exists itcast
comment “this is my first db”
with dbproperties (‘createdBy’=’Allen’);
(1)数据类型
Hive数据类型指的是表中列的字段类型;
整体分为两类: 原生数据类型(primitive data type)和复杂数据类型(complex data type) 。
最常用的数据类型是字符串String和数字类型Int
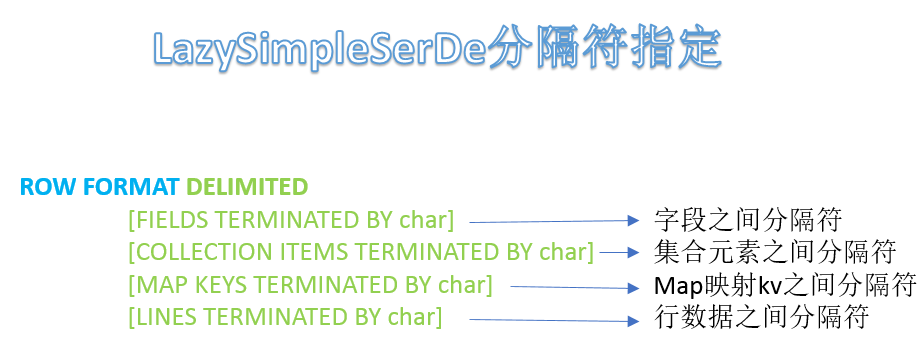
(2)分隔符指定语法
- ROW FORMAT DELIMITED语法用于指定字段之间等相关的分隔符,这样Hive才能正确的读取解析数据。
- 或者说只有分隔符指定正确,解析数据成功,我们才能在表中看到数据。
- LazySimpleSerDe是Hive默认的,包含4种子语法,分别用于指定字段之间、集合元素之间、 map映射 kv之间、换行的分隔符号。
- 在建表的时候可以根据数据的特点灵活搭配使用。
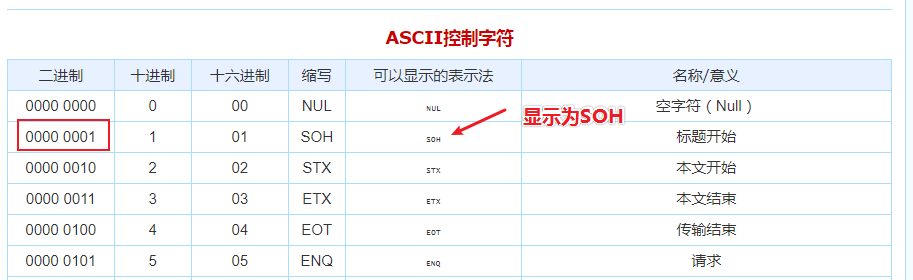
Hive默认分隔符 :
Hive建表时如果没有row format语法指定分隔符,则采用默认分隔符;
默认的分割符是’\001’,是一种特殊的字符,使用的是ASCII编码的值,键盘是打不出来的 ;
(1/3)数据文件
分析一下:字段都是基本类型,字段的顺序需要注意一下。
字段之间的分隔符是制表符,需要使用row format语法进行指定。
create table itheima.t_archer(id int comment "ID编号",name string comment "英雄名称",hp_max int comment "最大生命力",mp_max int comment "最大法力",attack_max int comment "最高物攻",defense_max int comment "最大物防",attack_range string comment "攻击范围",role_main string comment "主要定位",role_assist string comment "次要定位")row format delimitedfields terminated by "\t"; -- 字段之间的分隔符是tab键 制表符
(2/3) 建表语句
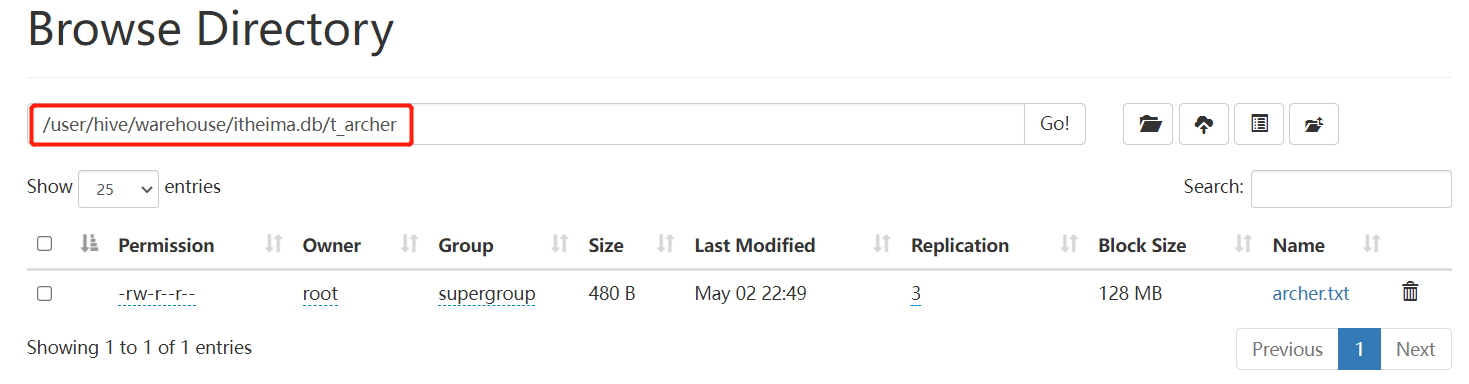
建表成功之后,在Hive的默认存储路径下就生成了表对应的文件夹;
把archer.txt文件上传到对应的表文件夹下 archer.txt
#在node机器上进行操作
cd ~
mkdir hivedata
cd hivedata/
#把文件从课程资料中首先上传到node1 linux系统上
#执行命令把文件上传到HDFS表所对应的目录下
hadoop fs -put archer.txt /user/hive/warehouse/itheima.db/t_archer
(3/3)结果验证
执行查询操作,可以看出数据已经映射成功。
核心语法: row format delimited fields terminated by 指定字段之间的分隔符。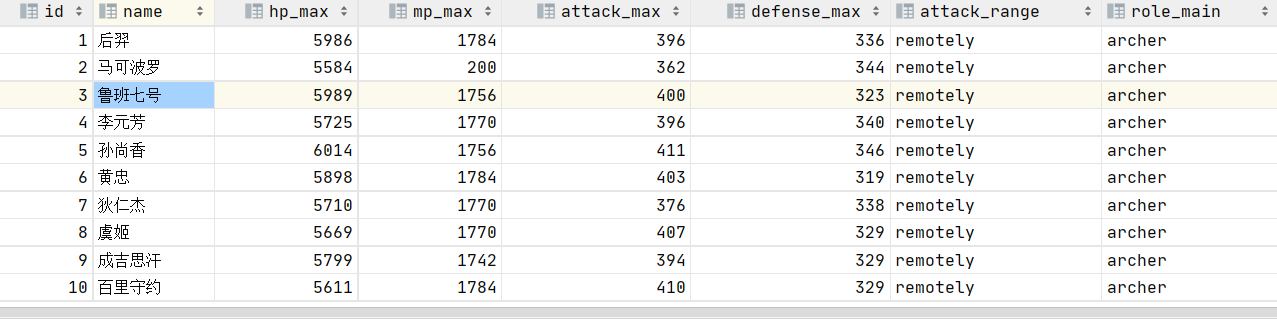

若有收获,就点个赞吧
0 人点赞
