在一个完整的离线大数据处理系统中,除了HDFS+MapReduce+Hive组成分析系统的核心之外,还需要数据采集、结果数据导出、任务调度等不可或缺的辅助系统,而这些辅助工具在hadoop生态体系中都有便捷的开源框架,在此,我们首先来介绍下数据采集部分所用的的开源框架——Flume。
Flume定义
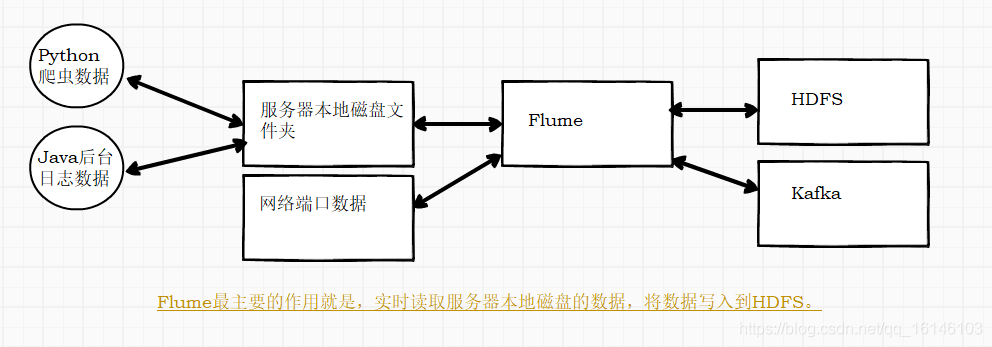
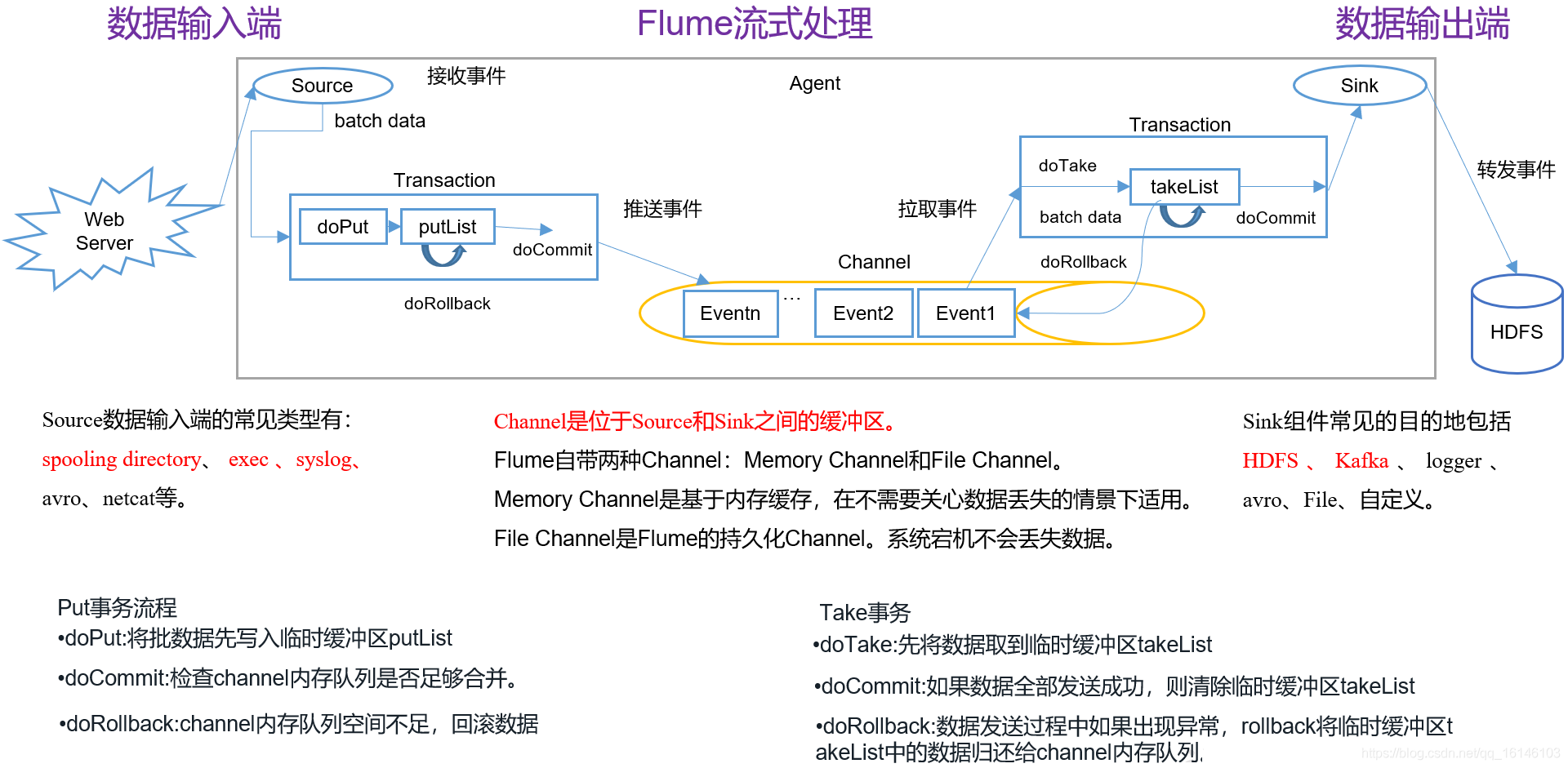
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。
Flume可以采集文件,socket数据包、文件、文件夹、kafka等各种形式源数据,又可以将采集到的数据(下沉sink)输出到HDFS、hbase、hive、kafka等众多外部存储系统中
一般的采集需求,通过对flume的简单配置即可实现
Flume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以适用于大部分的日常数据采集场景。
- 可以和任意存储进程集成。
- 输入的的数据速率大于写入目的存储的速率,flume会进行缓冲,减小hdfs的压力。
- flume中的事务基于channel,使用了两个事务模型(sender + receiver),确保消息被可靠发送。
[
](https://blog.csdn.net/qq_16146103/article/details/105894334)

若有收获,就点个赞吧
0 人点赞
